主成分分析、因子分析实验报告--SPSS

对2009年我国88个房地产上市公司的因子分析
分析结果:
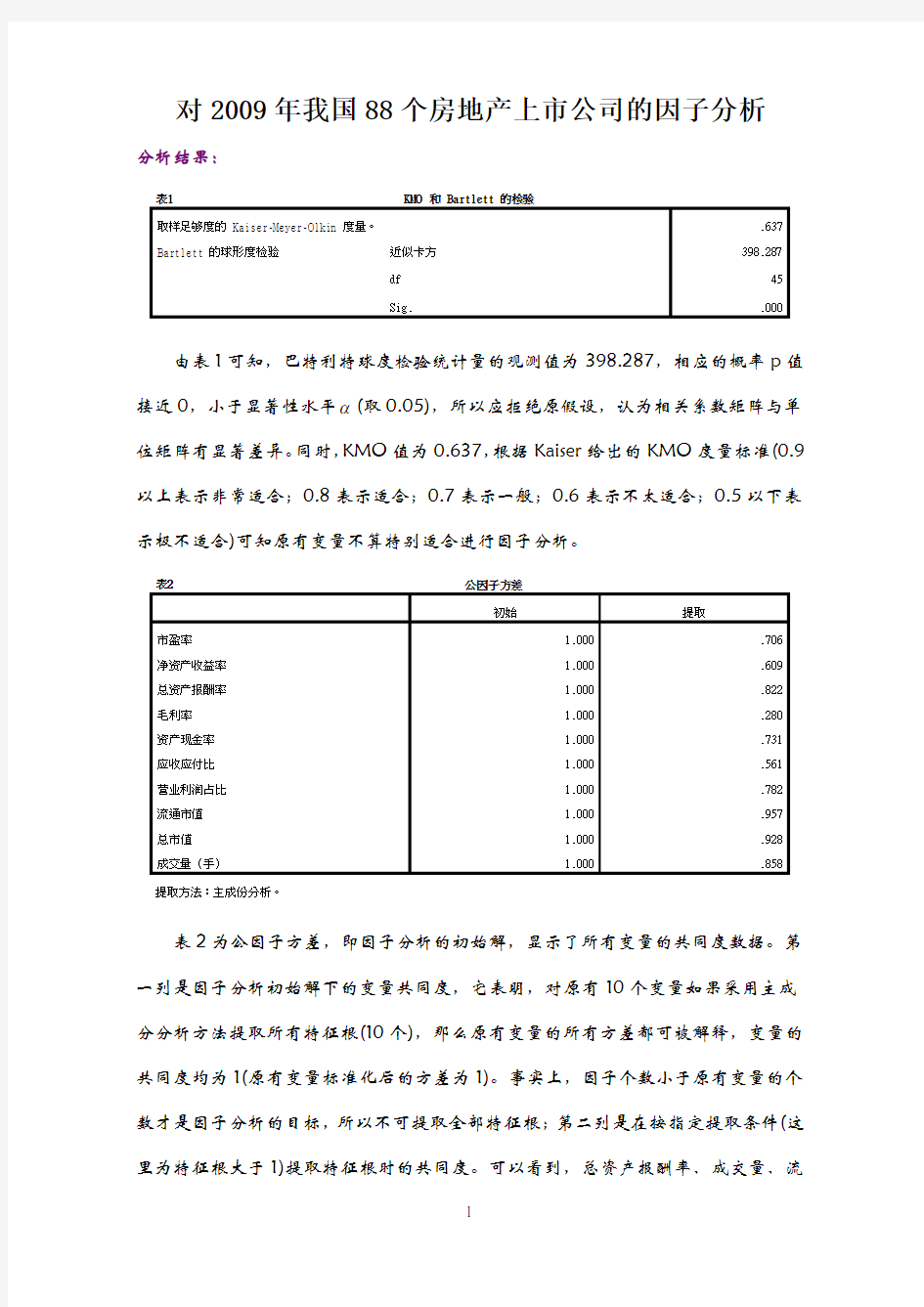
表1 KMO 和 Bartlett 的检验
取样足够度的 Kaiser-Meyer-Olkin 度量。.637 Bartlett 的球形度检验近似卡方398.287
df 45
Sig. .000 由表1可知,巴特利特球度检验统计量的观测值为398.287,相应的概率p值接近0,小于显著性水平 (取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。同时,KMO值为0.637,根据Kaiser给出的KMO度量标准(0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合)可知原有变量不算特别适合进行因子分析。
表2 公因子方差
初始提取市盈率 1.000 .706 净资产收益率 1.000 .609 总资产报酬率 1.000 .822 毛利率 1.000 .280 资产现金率 1.000 .731 应收应付比 1.000 .561 营业利润占比 1.000 .782 流通市值 1.000 .957 总市值 1.000 .928 成交量(手) 1.000 .858 提取方法:主成份分析。
表2为公因子方差,即因子分析的初始解,显示了所有变量的共同度数据。第一列是因子分析初始解下的变量共同度,它表明,对原有10个变量如果采用主成分分析方法提取所有特征根(10个),那么原有变量的所有方差都可被解释,变量的共同度均为1(原有变量标准化后的方差为1)。事实上,因子个数小于原有变量的个数才是因子分析的目标,所以不可提取全部特征根;第二列是在按指定提取条件(这里为特征根大于1)提取特征根时的共同度。可以看到,总资产报酬率、成交量、流
通市值、总市值的绝大部分信息可被因子解释,这些变量的信息丢失较少。但毛利率这一变量的信息丢失相当严重(近70%),净资产收益率、应收应付比率两个变量的信息丢失较为严重(近40%)。因此本次因子提取的总体效果并不理想。
表3展示了特征根及累积贡献率情况,按照特征根大于1的原则,选入了4个公共因子,其累积方差贡献率为72.343%,同时也可以看出,因子旋转后,累计方差比并没有改变,也就是没有影响原有变量的共同度,但却重新分配了各个因子解释原有变量的方差,改变了各因子的方差贡献,使各因子更易于解释。图五为因子的碎石图,需要说明的是这里累积方差贡献率并不高,远没有达到85%,但是根据碎石图我们可以看出在这里选四个因子还是比较合适的。
图五
表4 成份矩阵a
成份
1 2 3 4
流通市值.934 -.253 .125 .067 总市值.926 -.257 .064 .013 成交量(手).849 -.357 .065 .082 总资产报酬率.322 .791 .295 .073 净资产收益率.269 .669 .125 -.271 市盈率-.333 -.582 .418 -.286 毛利率.202 .418 .222 .122 营业利润占比.198 .155 -.776 .341 应收应付比-.231 -.190 .019 .687 资产现金率.195 -.052 -.544 -.627 提取方法 :主成份。
a. 已提取了 4 个成份。
采用最大方差法对成份矩阵(因子载荷矩阵)实施正交旋转以使因子具有命名解释性。指定按第一因子载荷降序的顺序输出旋转后的因子载荷矩阵如表5所示:表5 旋转成份矩阵a
成份
1 2 3 4
流通市值.971 .110 .032 .042 总市值.952 .079 .058 .111 成交量(手).925 -.029 .041 .022 总资产报酬率.043 .903 .070 -.021 净资产收益率-.013 .707 .029 .328 毛利率.069 .513 .021 -.104 营业利润占比.055 -.090 .878 .020 市盈率-.060 -.458 -.701 -.017 资产现金率.070 -.208 .229 .794 应收应付比-.075 -.212 .162 -.696 提取方法 :主成份。
旋转法 :具有 Kaiser 标准化的正交旋转法。
a. 旋转在 5 次迭代后收敛。
可以看出流通市值、总市值、成交量在第一因子上有较高的载荷,第一因子主要解释了这几个变量,可解释为公司价值;总资产报酬率、净资产收益率、毛利率在第二因子上有较高的载荷,第二因子主要解释了这几个变量,可解释为公司运营效益;营业利润占比、市盈率在第三因子上有较高的载荷,第三因子主要解释了这几个变量,可解释为公司获利能力;资产现金率、应收应付比在第四因子上有较高的载荷,第四因子主要解释了这几个变量,可解释为公司获现能力。
表6显示了四个因子的协方差矩阵,可以看出,四个因子之间没有线性相关性,实现了因子分析的目标。
采用回归法估计因子得分系数,并输出因子得分系数矩阵(成份得分系数矩阵),如表7所示。
表7 成份得分系数矩阵
成份
1
2
3
4
市盈率 .030 -.181 -.492 .048 净资产收益率 -.055 .367 -.060 .233 总资产报酬率 -.018 .487 -.034 -.073 毛利率 .014 .282 -.032 -.120 资产现金率 -.034 -.181 .156 .652 应收应付比 .021 -.091 .181 -.566 营业利润占比 -.021 -.136 .680 -.024 流通市值 .361 .020 -.036 -.042 总市值 .349 -.002 -.015 .017 成交量(手) .350
-.054
-.012
-.048
提取方法 :主成份。
旋转法 :具有 Kaiser 标准化的正交旋转法。 构成得分。
由表7得到四个因子1234f f f f 、、、的线性组合如下所示:(注:以下市盈率、净资产收益率、总资产报酬率、毛利率、资产现金率、应收应付比、营业利润占比、流通市值、总市值、成交量(手)依次用
12345678910
,,,,,,,,,x x x x x x x x x x 代替) 112345678910
=0.0300.0550.0180.0140340.0210.0210.3610.3490.350f x x x x x x x x x x +--+-0. -+++
212345678910
=0.1810.3670.4870.2821810.0910.1360.0200.0020.054f x x x x x x x x x x --+++-0. -+--
312345678910
=0.4920.0600.0340.0320.1810.6800.0360.0150.012f x x x x x x x x x x +----+0.156 +---
412345678910
=0.0480.2330.0730.1200.6520.5660.0240.0420.0170.048f x x x x x x x x x x -+--+ --+-
按以上四个线性组合计算因子得分,以各因子的方差贡献率占四个因子总方差贡献率的比重作为权重进行加权汇总,得到各企业的综合得分,即
f =(1f *27.269+2f *19.043+3f *13.541+4f *12.491)/72.343
下表显示了各个因子得分及综合得分中排在前十位的房地产上市公司:
由该表我们可以看到就公司市场价值而言,最高的是万科A,其次是保利地产、然后是金地集团等,在公司运营效益上相对比较好的是陆家嘴和*ST华控,而在公司获利能力和获现能力上,相对较好的是成城股份及亿城股份、首开股份及园城股份。就综合得分而言,排名最靠前的是万科A、保利地产和陆家嘴。由此我们也可以看出:对于房地产上市为公司而言,公司的市场价值对公司综合能力的影响是比较显著的,其次是公司的运营效益和公司的获利能力,由于该行业不像一般的零售业及其他产业那么注重现金流的问题,所以自然公司获现能力对公司综合能力的影响也就不是很突出。这也为房地产上市公司提供了一个参考,在他们以后的运营过程中,他们应该注重提高自己公司的市场价值和盈利能力,具体表现在流通市值、总市值、成交量(手)以及总资产报酬率、净资产收益率、毛利率、营业利润率和市盈率上。
附:四个因子的矩阵图
从该图中我们不难发现几乎没有哪个公司是在这四个因子上都有很高的得分,但是万科A在第一因子(公司市场价值)上的得分明显远高于其他各公司,这也是为什么综合得分中它的得分最高,与上述分析吻合,其实这也为各房地产上市公司指明了一条前进的道路,在资源有限的情况下,优先提升公司的市场价值,其次是公司的运营效益和盈利能力。
【实验报告】SPSS相关分析实验报告
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
应用统计spss分析报告
应用统计spss分析报告
学生姓名:肖浩鑫学号:31407371 一、实验项目名称:实验报告(三) 二、实验目的和要求 (一)变量间关系的度量:包括绘制散点图,相关系数计算及显著性检验; (二)一元线性回归:包括一元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验,利用回归方程进行估计和预测; (三)多元线性回归:包括多元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验等,多重共线性问题与自变量选择,哑变量回归; 三、实验内容 1. 从某一行业中随机抽取12家企业,所得产量与生产费用的数据如下: 企业编号产量(台)生产费用(万元)企业编号产量(台)生产费用(万元) 1 40 130 7 84 165 2 42 150 8 100 170 3 50 155 9 116 167 4 5 5 140 10 125 180 5 65 150 11 130 175 6 78 154 12 140 185 (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数,并对相关系数的显著性进行检验(),并说明二者之间的关系强度。
2. 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据: 地区人均GDP(元)人均消费水平(元) 北京22460 7326 辽宁11226 4490 上海34547 11546 江西4851 2396 河南5444 2208 贵州2662 1608 陕西4549 2035 (1)绘制散点图,并计算相关系数,说明二者之间的关系。 (2)人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (3)计算判定系数和估计标准误差,并解释其意义。(4)检验回归方程线性关系的显著性()(5)如果某地区的人均GDP为5000元,预测其人均消费水平。 (6)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 3. 随机抽取10家航空公司,对其最近一年的航班正点率和顾客投诉次数进行调查,数据如下:
SPSS实验报告_线性回归_曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
SPSS相关分析报告实验报告材料
本科教学实验报告 (实验)课程名称:数据分析技术系列实验
实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。
1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1. 分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze \ Descriptive Statistics \ Crosstabs Step2.将性别(Gender)和收入(Current Salary)分别移入Rows列表框和Columns 列表框。
Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。
SPSS实验报告(一)
SPSS实验报告(一)
湖南涉外经济学院 实验报告 课程名称:应用统计软件分析(SPSS) 专业班级: 姓名 学号: 指导教师: 职称:副研究员 实验日期: 2016.4.19 成绩评定指导教 师 签字 签字 日期
学生实验报告实验序号 一、实验目的及要求 实验目的 通过本次实验,使学生熟练掌握转换菜单和数据菜单的具体功能及操作,熟练应用两个菜单中的计算变量、重新编码、选择个案、个案排序、分类汇总等几个主要过程 实验要求 能够根据相关要求选用正确的过程对变量或者文件进行管理和操作,得到结果,并能对得出的结果进行解释。 二、实验描述及实验过程 实验描述一、下载数据(以下情况选一种): (一)分地区(31个省市区)环境污染治理投资数据(2014年) 环境污染治理投资总额(亿元),城市环境基础设施建设投资额(亿元) ,城市燃气建设投资额(亿元) ,城市集中供热建设投资额(亿元),城市排水建设投资额(亿元),城市园林绿化建设投资额(亿元),城市市容环境卫生建设投资额(亿元)
工业污染源治理投资(万元) 建设项目“三同时”环保投资额(亿元) (二)分地区(31个省市区)经济发展总体数据(2014年) 国民总收入,国内生产总值,第一产业增加值,第二产业增加值,第三产业增加值,人均国内生产总值,人口总量,城镇失业率,基尼系数等 (三)各省市房地产开发2014年相关数据 投资额,房地产开发企业个数,从业人员数,收入,税金,利润,资产,负债,平均销售价格,等等。 (四)各省市科技2014年相关数据 包括GDP,研发投入,研发投入强度(研发投入/GDP),R&D研发人员,专利授权数,发明专利授权量。 (五)查找相关行业(钢铁行业、水泥行业、医药制造、工程机械、汽车制造业、旅游酒店行业、航空、电子商务企业等)上市公司2015年度数据。包括销售收入、利润、固定资产净值、总资产利润率、营业利润率、销售净利率、净资产收益率、流动比率、资产负债率、主营业务收入增长率、营收账款周转率、存货周转
多元线性回归SPSS实验报告
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
多元统计学SPSS实验报告一
华东理工大学2016–2017学年第二学期 《多元统计学》实验报告 实验名 称实验1数据整理与描述统计分析
教师批阅:实验成绩: 教师签名: 日期: 实验报告正文: 实验数据整理 (一)对“employee”进行数据整理 1.观察量排序 ( based on current salary) 2.变量值排序(based on current salary : rsalary) 3.计算新的变量(incremental salary=current salary - beginning salary)
4.拆分数据文件(based on gender) 结论:There are 215 female employees and 259 male employees. 5.分类汇总 (break variable: gender ; function: mean ) 结论:The average current salary of female is . The average current salary of male is . (二)分别给出三种工作类别的薪水的描述统计量 实验描述统计分析 1)样本均值矩阵 结论:总共分析六组变量,每组含有十个样本。 每股收益(X1)的均值为;净资产收益率(X2)的均值为;总资产报酬率(X3)的均值为;销售净
利率(X4)的均值为;主营业务增长率(X5)的均值为;净利润增长率(X6)的均值为. 2)协方差阵 结论:矩阵共六行六列,显示了每股收益(X1)、净资产收益率(X2)、总资产报酬率(X3)、销售净利率(X4)、主营业务增长率(X5)和净利润增长率(X6)的协方差。 3)相关系数 结论:矩阵共六行六列,显示了每股收益 (X1)、净资产收益率(X2)、总资产报酬 率(X3)、销售净利率(X4)、主营业务增 长率(X5)和净利润增长率(X6)之间的 相关系数。 每格中三行分别显示了相关系数、显著性 检验与样本个数。 4)矩阵散点图
spss软件分析异常值检验实验报告
实验五:残差分析 【实验目的】 (1)通过残差检验,掌握残差分析的方法 (2)异常值检验 【仪器设备】 计算机、spss软件、何晓群《实用回归分析》表和表的数据 【实验内容、步骤和结果】 对何晓群《实用回归分析》表的数据进行残差分析 原始数据如表1,其中y表示货运总量(亿吨)x1表示工业总产值(亿元)x2表示农业总产值(亿元)x3表示居民非商业支出(亿元) 表1. 对表1数据用spss软件进行分析得以下各表
由上表可知复相关系数R=,决定系数R方=,由决定系数看出回归方程的显著性不高,接下来看方差分析表3 由表3知F值为较小,说明x1、x2、x3整体上对y的影响不太显著。 表4系数 模型非标准化系数标准系数 t Sig. B标准误差试用版 1(常量).096 x1.385.100 x2.535.049 x3.277.284
表4系数 模型 非标准化系数 标准系数 t Sig. B 标准 误差 试用版 1 (常量) .096 x1 .385 .100 x2 .535 .049 x3 .277 .284 回归方程为 123348.280 3.7547.10112.447y x x x =-+++
图1.学生化残差
差 残差: 对数据用spss进行分析得 表6异常值的诊断分析
数据不存在异常值.绝对值最大的删除学生化残差为SDR=,因而根据学生化删除残差诊断认为第6个数据为异常值.其中中心化杠杆值,cook距离为位于第一大.因此第6个数据为异常值. 对何晓群《实用回归分析》表的数据进行残差分析 原始数据为 : 表个啤酒品牌的广告费用和销售量
主成分分析案例
姓名:XXX 学号:XXXXXXX 专业:XXXX 用SPSS19软件对下列数据进行主成分分析: ……
一、相关性 通过对数据进行双变量相关分析,得到相关系数矩阵,见表1。 表1 淡化浓海水自然蒸发影响因素的相关性 由表1可知: 辐照、风速、湿度、水温、气温、浓度六个因素都与蒸发速率在0.01水平上显著相关。 分析:各变量之间存在着明显的相关关系,若直接将其纳入分析可能会得到因多元共线性影响的错误结论,因此需要通过主成份分析将数据所携带的信息进行浓缩处理。 二、KMO和球形Bartlett检验 KMO和球形Bartlett检验是对主成分分析的适用性进行检验。 KMO检验可以检查各变量之间的偏相关性,取值范围是0~1。KMO的结果越接近1,表示变量之间的偏相关性越好,那么进行主成分分析的效果就会越好。实际分析时,KMO统计量大于0.7时,效果就比较理想;若当KMO统计量小于0.5时,就不适于选用主成分分析法。 Bartlett球形检验是用来判断相关矩阵是否为单位矩阵,在主成分分析中,若拒绝各变量独立的原假设,则说明可以做主成分分析,若不拒绝原假设,则说明这些变量可能独立提供一些信息,不适合做主成分分析。
由表2可知: 1、KMO=0.631<0.7,表明变量之间没有特别完美的信息的重叠度,主成分分析得到的模型又可能不是非常完善,但仍然值得实验。 2、显著性小于0.05,则应拒绝假设,即变量间具有较强的相关性。 三、公因子方差 公因子方差表示变量共同度。表示各变量中所携带的原始信息能被提取出的主成分所体现的程度。 由表3可知: 几乎所有变量共同度都达到了75%,可认为这几个提取出的主成分对各个变量的阐释能力比较强。 四、解释的总方差 解释的总方差给出了各因素的方差贡献率和累计贡献率。
统计学原理SPSS实验报告
实验一:用SPSS绘制统计图 实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图) 对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。 实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等) 操作过程: 步骤1:启动SPSS。单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示选择数据源界面。 图1-1 启动SPSS
图1-2 选择数据源界面 步骤2 :打开一个空白的SPSS数据文件,如图1-3。启动SPSS 后,出现SPSS 主界面(数据编辑器)。同大多数Windows 程序一样,SPSS 是以菜单驱动的。多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件 步骤3:数据的输入。打开SPSS以后,直接进入变量视图窗口。SPSS的变量视图窗口分为data view和variable view两个。先在variable view中定义变量,然后在data view里面直接输入自定义数据。命名为mydata并保存在桌面。如图1-4所示。 图1-4 数据的输入 步骤4:调用Graphs菜单的Bar过程,绘制直条图。直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。选择的数据源见表1。 步骤5:数据准备。激活数据管理窗口,定义变量名:年龄标化发生率为RATE,冠心病临床型为DISEASE,血压状态为BP。RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
回归分析实验报告
实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日
一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1)
图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏
5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 第一,将EXCEL中的原始数据导入到SPSS软件中; 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。 所的结论: 标准化后的所有指标数据。 注意: SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。 factor过程对数据进行因子分析(指标之间的相关性判定略)。 【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;
【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框; 【3】设置“抽取”,勾选“碎石图”复选框; 【4】设置“旋转”,勾选“最大方差法”复选框; 【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框; 【6】查看分析结果。 所做工作: a.查看KMO和Bartlett 的检验 KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析; Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。 所的结论: 符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。 注意: 1.KMO(Kaiser-Meyer-Olkin) KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。 Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般; 0.6表示不太适合;0.5以下表示极不适合。 2.Bartlett 球度检验: 巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。 Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。 所做工作: b. 全部解释方差或者解释的总方差(Total Variance Explained)
spss相关分析实验报告
实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
表1
五、实验结果及其分析:
分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 公司销售净利率(X1)资产净利率(X2)净资产收益率(X3)销售毛利率(X4) 歌华有线五粮液用友软件太太药业浙江阳光烟台万华方正科技红河光明贵州茅台中铁二局红星发展伊利股份青岛海尔湖北宜化雅戈尔福建南纸43.31 17.11 21.11 29.55 11.00 17.63 2.73 29.11 20.29 3.99 22.65 4.43 5.40 7.06 19.82 7.26 7.39 12.13 6.03 8.62 8.41 13.86 4.22 5.44 9.48 4.64 11.13 7.30 8.90 2.79 10.53 2.99 8.73 17.29 7.00 10.13 11.83 15.41 17.16 6.09 12.97 9.35 14.3 14.36 12.53 5.24 18.55 6.99 54.89 44.25 89.37 73 25.22 36.44 9.96 56.26 82.23 13.04 50.51 29.04 65.5 19.79 42.04 22.72 第一,将EXCEL中的原始数据导入到SPSS软件中; 注意: 导入Spss的数据不能出现空缺的现象,如出现可用0补齐。 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。 所做工作: a. 原始数据的标准化处理
spss实验报告最终版本
实验课程专业统计软件应用 上课时间2012 学年 1 学期15 周(2012 年12 月18日—28 日) 学生姓名李艳学号2010211587 班级0331002 所在学院经济管 上课地点经管3 楼指导教师胡大权理学院
实验内容写作 第六章 一实验目的 1、理解方差分析的基本概念 2、学会常用的方差分析方法 二实验内容 实验原理:方差分析的基本原理是认为不同处理组的均值间的差别基本来源有两个:随机误差,如测 量误差造成的差异或个体间的差异,称为组内差异 根据老师的讲解和课本的习题完成思考与练习的5、6、7、8题。 第5题:为了寻求适应某地区的高产油菜品种,今选5个品种进行试验,每一种在4块条件完全相同的试验田上试种,其他施肥等田间管理措施完全一样。表 6.20所示为每一品种下每一块田的亩产量,根 据这些数据分析不同品种油菜的平均产量在显著水平0.05下有无显著性差异。 第一步分析 由于考虑的是控制变量对另一个观测变量的影响,而且是5个品种,所以不宜采用独立样本T检验,应该采用单因素方差分析。 第二步数据的组织 从实验材料中直接导入数据 第三步方差相等的齐性检验 由于方差分析的前提是各水平下的总体服从方差相等的正态分布,而且各组的方差具有齐性,其中正 态分布的要求并不是非常严格,但是对于方差相等的要求还是比较严格的,因此必须对方差相等的前提进 行检验。
第四步多重比较分析 通过上面的步骤,只能判断不同的施肥等田间操作效果是否有显著性差异,如果要想进一步了解究竟那 个品种与其他的有显著性均值差别等细节问题,就需要单击上图中的两两比较按钮。 第五步运行结果及分析 多重比较结果表:从该表可以看出分别对几个不同的品种进行的两两比较。最后我们可以得出结论第4品种是最好的。其他的次之。 第6题:某公司希望检测四种类型类型轮胎A,B,C,D的寿命,如表 6.21所示。其中每种轮胎应用在随选择的6种汽车上,在显著性水平0.05下判断不同类型轮胎的寿命间是否存在显著性差异。 第一步分析 由于考虑的是一个控制变量对另一个控制变量的影响,而且是4种轮胎,所以不宜采用独立样本T 检验,应该采用单因素方差分析。 第二步数据的组织 从实验材料中直接导入数据。 第三步方差相等的齐性检验 由于方差分析的前提是各水平下的总体服从方差相等的正态分布,而且各组的方差具有齐性,其中正态分 布的要求并不是非常严格,但是对于方差相等的要求还是比较严格的,因此必须对方差相等的前提进行检 验。选择菜单“分析”—均值比较—单因素ANOVA。
SPSS进行主成分分析
实验七、利用SPSS进行主成分分析 【例子】以全国31个省市的8项经济指标为例,进行主成分分析。 第一步:录入或调入数据(图1)。 图1 原始数据(未经标准化) 第二步:打开“因子分析”对话框。 沿着主菜单的“Analyze→Data Reduction→Factor ”的路径(图2)打开因子分析选项框(图3)。 图2 打开因子分析对话框的路径
图3 因子分析选项框 第三步:选项设置。 首先,在源变量框中选中需要进行分析的变量,点击右边的箭头符号,将需要的变量调入变量(Variables)栏中(图3)。在本例中,全部8个变量都要用上,故全部调入(图4)。因无特殊需要,故不必理会“Value ”栏。下面逐项设置。 图4将变量移到变量栏以后 ⒈设置Descriptives描述选项。 单击Descriptives按钮(图4),弹出Descriptives对话框(图5)。
图5 描述选项框 在Stat is tic s 统计 栏中选中U niva riate d escript ives 复选项,则输出结果中将会给出原始数据的抽样均值、方差和样本数目(这一栏结果可供检验参考);选中Initial soluti on 复选项,则会给出主成分载荷的公因子方差(这一栏数据分析时有用)。 在C orrel ation M atri x栏中,选中Coe fficien ts 复选项,则会给出原始变量的相关系数矩阵(分析时可参考);选中Deter minant 复选项,则会给出相关系数矩阵的行列式,如果希望在E xc el中对某些计算过程进行了解,可选此项,否则用途不大。其它复选项一般不用,但在特殊情况下可以用到(本例不选)。 设置完成以后,单击Cont inue 按钮完成设置(图5)。 ⒉ 设置Extra ction 选项。 打开Ext raction 对话框(图6)。因子提取方法主要有7种,在Method 栏中可以看到,系统默认的提取方法是主成分(Pr in ci pa l Compon en ts),因此对此栏不作变动,就是认可了主成分分析方法。 在Ana lyze 栏中,选中Correlatio n ma trix 复选项,则因子分析基于数据的相关系数矩阵进行分析;如果选中Covar iance matri x复选项,则因子分析基于数据的协方差矩阵进行分析。对于主成分分析而言,由于数据标准化了,这两个结果没有分别,因此任选其一即可。 在D isplay 栏中,选中U nrotated factor s olu ti on(非旋转因子解)复选项,则在分析结果中给出未经旋转的因子提取结果。对于主成分分析而言,这一项选择与否都一样;对于旋转因子分析,选择此项,可将旋转前后的结果同时给出,以便对比。 选中Scree P lo t(“山麓”图),则在分析结果中给出特征根按大小分布的折线图(形如山麓截面,故得名),以便我们直观地判定因子的提取数量是否准确。 在Extract 栏中,有两种方法可以决定提取主成分(因子)的数目。一是根据特征根(Eig envalues )的数值,系统默认的是1=c λ。我们知道,在主成分分析中,主成分得分的方差就是对应的特征根数值。如果默认1=c λ,则所有方差大于等于1的主成分将被保留,其余舍弃。如果觉得最后选取的主成分数量不足,可以将c λ值降低,例如取 9.0=c λ;如果认为最后的提取的主成分数量偏多,则可以提高c λ值,例如取1.1=c λ。 主成分数目是否合适,要在进行一轮分析以后才能肯定。因此,特征根数值的设定,要在反复试验以后才能决定。一般而言,在初次分析时,最好降低特征根的临界值(如取
管理同学spss描述统计分析实验报告
描述统计分析 一、实验目的与要求 1. 了解统计描述的常用工具及SPSS 中的统计描述模块。 2. 掌握分类变量和连续变量的统计描述方法及指标。 二、实验内容提要 1.根据数据,分析受访者的年龄分布情况,尝试分城市/合并描述。 2.根据SPSS 自带数据Employee ,分析员工性别、受教育程度、少数民族、职位类别的分布情况,并尝试分析这些属性之间的关系以及这些属性和工资之间的关系。 三、实验步骤 根据数据 在数据栏中找到拆分文件,点击,将城市添加到分组方式中,对城市进行拆分,点击确定。 在分析中选择描述统计下的描述,点击确定。 描述统计量 S0. 城市 N 极小值 极大值 均值 标准差 100北京 S3. 年龄 378 18 65 有效的 N (列表状态) 378 200上海 S3. 年龄 387 18 65 有效的 N (列表状态) 387 300广州 S3. 年龄 382 18 65 有效的 N (列表状态) 382 根据SPSS 自带数据Employee 在分析一栏中的描述统计下找到频率,点击确定。 性别分析表 Gender 频率 百分比 有效百分比 累积百分比 有效 Female 216 Male 258 合计 474 受教育程度分析表
Educational Level (years) 频率 百分比 有效百分比 累积百分比 有效 8 53 12 190 14 6 15 116 16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 合计 474 少数民族分析表 Minority Classification 频率 百分比 有效百分比 累积百分比 有效 No 370 Yes 104 合计 474 2.选择分析,描述统计下的交叉表,点击确定,分析性别和受教育程度之间的情况,将性别添加到行,将受教育程度添加到列中,点击确定。
应用统计学因子分析与主成分分析案例解析_SPSS操作分析
因子分析与主成分分析 一、问题概述 现希望对30个省市自治区经济发展基本情况的八项指标进行分析。具体采用的指标只有:GDP、居民消费水平、固定资产投资、职工平均工资、货物周转量、居民消费价格指数、商品零售价格指数、工业总产值。这是一个综合分析问题,八项指标较多,用主成分分析法进行综合。 二、数据处理与分析 1.因子分析 打开数据后,在SPSS中进行因子分析的步骤如下: 选择“分析---降维---因子分析”,在弹出的对话框里 (1)描述---系数、KMO与Bartlett的球形度检验 (2)抽取---碎石图、未旋转的因子解 (3)旋转---最大方差法、旋转解、载荷图 (4)得分---保存为变量、显示因子得分系数矩阵 (5)选项---按大小排序 点击确定得到如下各图: 图3-1 图3-2 KMO 和 Bartlett 的检验 取样足够度的 Kaiser-Meyer-Olkin 度量。.620 Bartlett 的球形度检验近似卡方231.285 df 28 Sig. .000 图3-3 公因子方差
图3-6 成份矩阵a
图3-9
(2)因子模型中各统计量的意义 A)因子载荷错误!未找到引用源。:因子载荷错误!未找到引用源。为第i个变量在第j个因子上的载荷,实际上就是错误!未找到引用源。与错误!未找到引用源。的相关系数,表示变量错误!未找到引用源。依赖因子错误!未找到引用源。的程度,反应了第i个变量错误!未找到引用源。对于第j个因子错误!未找到引用源。的重要性。 B)变量错误!未找到引用源。的变量共同度:k个公因子对第i个变量方差的贡献,也称为公因子方差比,记为错误!未找到引用源。,公式为:错误!未找到引用源。=错误!未找到引用源。(j=1,2,….,k)
spss相关分析实验报告
实验五相关分析实验报关费 一、实验目得: 学习利用s pss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表 1 如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析与肯德尔等级相关分 析. 2.在控制物理成绩不变得条件下,做数学成绩与英语成绩得相关分析(这 种情况下得相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中得相关分析。 三、实验步骤: 1.选择分析—相关—双变量,弹出窗口,在对话框得变量列表中选变量 “数学成绩"、“物理成绩” ,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)与肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差与均值.单击确定,得出输出结果,对结果进 行分析解释。 2.选择分析一相关一偏相关,弹出窗口,在对话框得变量列表选变量数学 成绩”、“英语成绩”,在控制列表选择要控制得变量“物理成绩”以 在控制物理成绩得影响下对变量数学成绩与英语成绩进行偏相关分析; 在“显著性检验”框中选双侧检验,单击确定,得出输出结果,对结果 进行分析解释. 3.选择分析一描述统计-交叉表,弹出窗口,对交叉表得行与列进行选 择,行选择为数学成绩,列选择为物理成绩.然后对统计量进行设置, 选择相关性,点击继续-确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
囲戏变量相关0 变旻(Y): 歹物理戍悄 相关浆勤 0 Pearson 叼兰endsll 的tau-b(K) J Spearman 叼标记SL苦性徇关(E) I ?―I粘址妃)][賞Jt? ][ ■備~ [ 鹽 ,丘示渎际說曹性水半(D 确定 ]|殆贴(E) H St賣(B)][ 取禱选顶(2)… 农孝号 /其 语威纽 显著性检验 双侧檢勉I) 单侧檢验(D 选他…]
SPSS对主成分回归实验报告
《多元统计分析分析》实验报告 2012 年月日学院经贸学院姓名学号 实验 实验成绩名称 一、实验目的 (一)利用SPSS对主成分回归进行计算机实现. (二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释. 二、实验内容 以教材例题为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用 三、实验步骤(以文字列出软件操作过程并附上操作截图) 1、数据文件的输入或建立:(文件名以学号或姓名命名) 将表数据输入spss:点击“文件”下“新建”——“数据”见图1: 图1 点击左下角“变量视图”首先定义变量名称及类型:见图2: 图2: 然后点击“数据视图”进行数据输入(图3): 图3
完成数据输入 2、具体操作分析过程: (1)首先做因变量Y与自变量X1-X3的普通线性回归: 在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4): 图4 将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5): 然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9) 其他选项按软件默认。最后点击“确定”,运行线性回归,输出相关结果(见表1-3)
- spss相关分析实验报告
- 相关分析和回归分析SPSS实现
- SPSS相关分析实验报告解析
- spss实验报告线性回归曲线估计
- 【实验报告】SPSS相关分析实验报告
- spss对数据进行相关性分析实验报告
- SPSS的相关分析
- SPSS相关分析实验报告定稿版
- SPSS聚类分析实验报告
- spss实验报告最终版本
- SPSS相关分析实验报告精选
- SPSS相关分析实验报告
- 完整word版,SPSS聚类分析实验报告
- 相关分析和一元线性回归分析SPSS报告
- SPSS相关分析实验报告文档
- spss对数据进行相关性分析实验报告
- SPSS相关分析实验报告.doc
- 第八章SPSS的相关分析和回归分析
- SPSS回归分析实验报告
- SPSS的相关分析实验报告