第十章 spss教程之分类分析

第十章分类分析
第一节 K-Means Cluster过程
10.1.1 主要功能
10.1.2 实例操作
第二节 Hierarchical Cluster过程
10.2.1 主要功能
10.2.2 实例操作
第三节 Discriminant过程
10.3.1 主要功能
10.3.2 实例操作
人们认识事物时往往先把被认识的对象进行分类,以便寻找其中同与不同的特征,因而分类学是人们认识世界的基础科学。在医学实践中也经常需要做分类的工作,如根据病人的一系列症状、体征和生化检查的结果,判断病人所患疾病的类型;或对一系列检查方法及其结果,将之划分成某几种方法适合用于甲类病的检查,另几种方法适合用于乙类病的检查;等等。统计学中常用的分类统计方法主要是聚类分析与判别分析。
聚类分析是直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。判别分析则先根据已知类别的事物的性质,利用某种技术建立函数式,然后对未知类别的新事物进行判断以将之归入已知的类别中。聚类分析与判别分析有很大的不同,聚类分析事先并不知道对象类别的面貌,甚至连共有几个类别也不确定;判别分析事先已知对象的类别和类别数,它正是从这样的情形下总结出分类方法,用于对新对象的分类。
第一节 K-Means Cluster过程
10.1.1 主要功能
调用此过程可完成由用户指定类别数的大样本资料的逐步聚类分析。所谓逐步聚类分析就是先把被聚对象进行初始分类,然后逐步调整,得到最终分类。
返回目录返回全书目录
10.1.2 实例操作
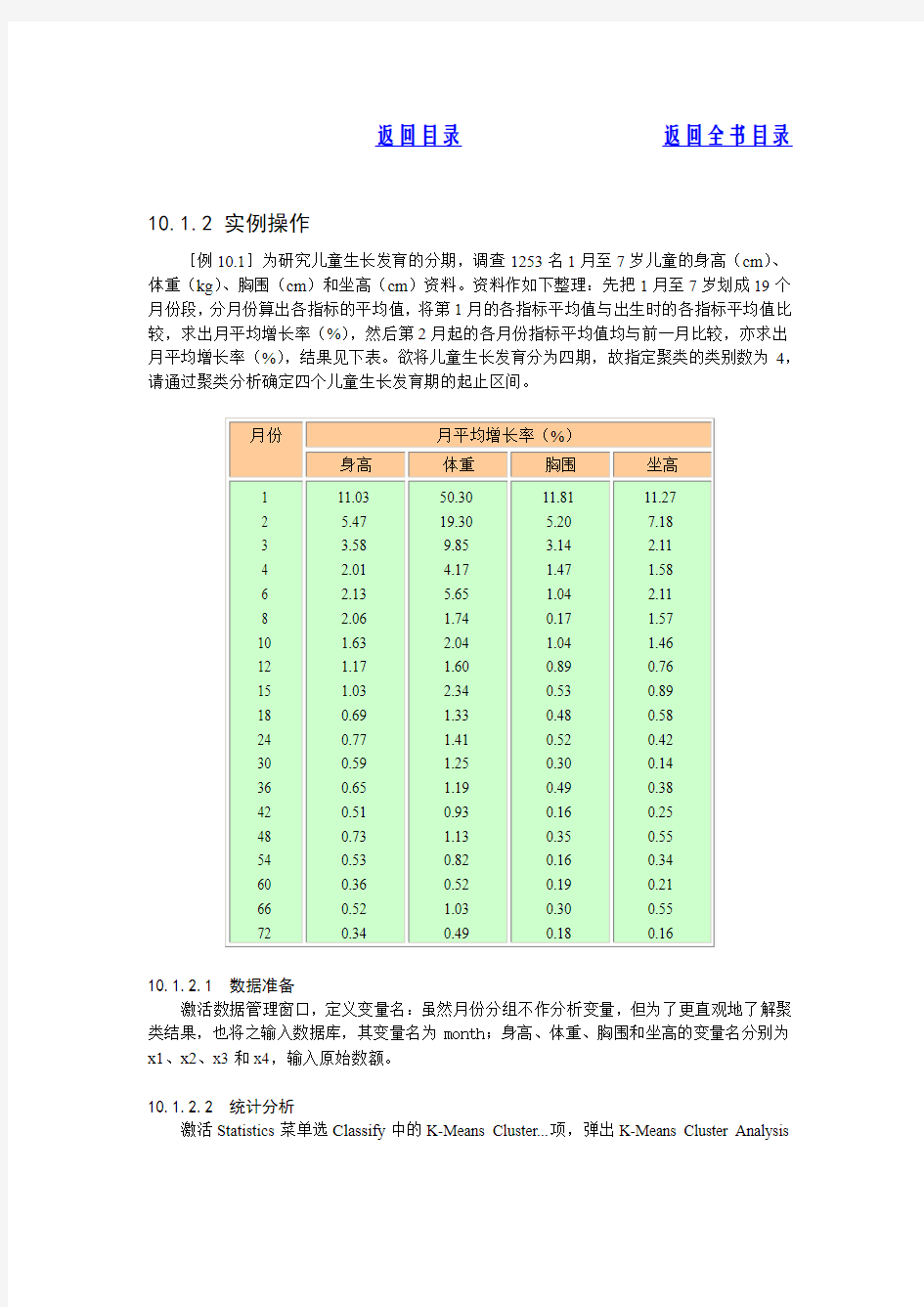
[例10.1]为研究儿童生长发育的分期,调查1253名1月至7岁儿童的身高(cm)、体重(kg)、胸围(cm)和坐高(cm)资料。资料作如下整理:先把1月至7岁划成19个月份段,分月份算出各指标的平均值,将第1月的各指标平均值与出生时的各指标平均值比较,求出月平均增长率(%),然后第2月起的各月份指标平均值均与前一月比较,亦求出月平均增长率(%),结果见下表。欲将儿童生长发育分为四期,故指定聚类的类别数为4,请通过聚类分析确定四个儿童生长发育期的起止区间。
10.1.2.1 数据准备
激活数据管理窗口,定义变量名:虽然月份分组不作分析变量,但为了更直观地了解聚类结果,也将之输入数据库,其变量名为month;身高、体重、胸围和坐高的变量名分别为x1、x2、x3和x4,输入原始数额。
10.1.2.2 统计分析
激活Statistics菜单选Classify中的K-Means Cluster...项,弹出K-Means Cluster Analysis
对话框(如图10.1示)。从对话框左侧的变量列表中选x1、x2、x3、x4,点击 钮使之进入Variables框;在Number of Clusters(即聚类分析的类别数)处输入需要聚合的组数,本例为4;在聚类方法上有两种:Iterate and classify指先定初始类别中心点,而后按K-means 算法作叠代分类,Classify only指仅按初始类别中心点分类,本例选用前一方法。
图10.1 逐步聚类分析对话框
为在原始数据库中逐一显示分类结果,点击Save...钮弹出K-Means Cluster:Save New Variables对话框,选择Cluster membership项,点击Continue钮返回K-Means Cluster Analysis 对话框。
本例还要求对聚类结果进行方差分析,故点击Options...钮弹出K-Means Cluster:来Options对话框,在Statistics栏中选择ANOV A table项,点击Continue钮返回K-Means Cluster Analysis对话框,再点击OK钮即完成分析。
10.1.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
首先系统根据用户的指定,按4类聚合确定初始聚类的各变量中心点,未经K-means 算法叠代,其类别间距离并非最优;经叠代运算后类别间各变量中心值得到修正。
之后对聚类结果的类别间距离进行方差分析,方差分析表明,类别间距离差异的概率值均<0.001,即聚类效果好。这样,原有19类(即原有的19个月份分组)聚合成4类,第一类含原有1类,第二类含原有1类,第三类含原有2类,第四类含原有15类。具体结果系统以变量名QCL_1存于原始数据库中。
在原始数据库(图10.2)中,我们可清楚地看到聚类结果;参照专业知识,将儿童生长发育分期定为:
第一期,出生后至满月,增长率最高;
第二期,第2个月起至第3个月,增长率次之;
第三期,第3个月起至第8个月,增长率减缓;
第四期,第8个月后,增长率显著减缓。
返回目录返回全书目录第二节 Hierarchical Cluster过程
10.2.1 主要功能
调用此过程可完成系统聚类分析。在系统聚类分析中,用户事先无法确定类别数,系统将所有例数均调入内存,且可执行不同的聚类算法。系统聚类分析有两种形式,一是对研究对象本身进行分类,称为Q型举类;另一是对研究对象的观察指标进行分类,称为R型聚类。
返回目录返回全书目录
10.2.2 实例操作
[例10.2]29名儿童的血红蛋白(g/100ml)与微量元素(μg/100ml)测定结果如下表。由于微量元素的测定成本高、耗时长,故希望通过聚类分析(即R型指标聚类)筛选代表性指标,以便更经济快捷地评价儿童的营养状态。
1 2 3 4 5 6 7 8 9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29 54.8
9
72.4
9
53.8
1
64.7
4
58.8
43.6
7
54.8
9
86.1
2
60.3
5
54.0
4
61.2
3
60.1
7
69.6
9
72.2
8
55.1
3
70.0
8
63.0
5
48.7
5
52.2
8
52.2
1
49.7
1
61.0
2
30.86
42.61
52.86
39.18
37.67
26.18
30.86
43.79
38.20
34.23
37.35
33.67
40.01
40.12
33.02
36.81
35.07
30.53
27.14
36.18
25.43
29.27
28.79
29.17
29.99
29.29
31.93
32.94
28.55
448.70
467.30
425.61
469.80
456.55
395.78
448.70
440.13
394.40
405.60
446.00
383.20
416.70
430.80
445.80
409.80
384.10
342.90
326.29
388.54
331.10
258.94
292.80
292.60
312.80
283.00
344.20
312.50
294.7
0.012
0.008
0.004
0.005
0.012
0.001
0.012
0.017
0.001
0.008
0.022
0.001
0.012
0.000
0.012
0.012
0.000
0.018
0.004
0.024
0.012
0.016
0.048
0.006
0.006
0.016
0.000
0.064
0.00
5
1.010
1.640
1.220
1.220
1.010
0.594
1.010
1.770
1.140
1.300
1.380
0.914
1.350
1.200
0.918
1.190
0.853
0.924
0.817
1.020
0.897
1.190
1.320
1.040
1.030
1.350
0.689
1.150
0.838
10.2.2.1 数据准备
激活数据管理窗口,定义变量名:钙、镁、铁、锰、铜和血红蛋白的变量名分别为x1、x2、x3、x4、x5、x6,之后输入原始数据。
10.2.2.2 统计分析
激活Statistics菜单选Classify中的Hierarchical Cluster...项,弹出Hierarchical Cluster Analysis对话框(图10.3)。从对话框左侧的变量列表中选x1、x2、x3、x4、x5、x6,点击 钮使之进入Variable(s)框;在Cluster处选择聚类类型,其中Cases表示观察对象聚类,Variables表示变量聚类,本例选择Variables。
图10.3 系统聚类分析对话框
点击Statistics...钮,弹出Hierarchical Cluster Analysis: Statistics对话框,选择Distance matrix,要求显示距离矩阵,点击Continue钮返回Hierarchical Cluster Analysis对话框(图10.4)。
图10.4 系统聚类方法选择对话框
本例要求系统输出聚类结果的树状关系图,故点击Plots...钮弹出Hierarchical Cluster Analysis:Plots对话框,选择Dendrogram项,点击Continue钮返回Hierarchical Cluster Analysis 对话框。
点击Method...钮弹出Hierarchical Cluster Analysis:Method对话框,系统提供7种聚类方法供用户选择:
Between-groups linkage:类间平均链锁法;
Within-groups linkage:类内平均链锁法;
Nearest neighbor:最近邻居法;
Furthest neighbor:最远邻居法;
Centroid clustering:重心法,应与欧氏距离平方法一起使用;
Median clustering:中间距离法,应与欧氏距离平方法一起使用;
Ward's method:离差平方和法,应与欧氏距离平方法一起使用。
本例选择类间平均链锁法(系统默认方法)。在选择距离测量技术上,系统提供8种形式供用户选择:
Euclidean distance:Euclidean距离,即两观察单位间的距离为其值差的平方和的平方根,该技术用于Q型聚类;
Squared Euclidean distance:Euclidean距离平方,即两观察单位间的距离为其值差的平方和,该技术用于Q型聚类;
Cosine:变量矢量的余弦,这是模型相似性的度量;
Pearson correlation:相关系数距离,适用于R型聚类;
Chebychev:Chebychev距离,即两观察单位间的距离为其任意变量的最大绝对差值,该技术用于Q型聚类;
Block:City-Block或Manhattan距离,即两观察单位间的距离为其值差的绝对值和,适用于Q型聚类;
Minkowski:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的平方根;p由用户指定
Customized:距离是一个绝对幂的度量,即变量绝对值的第p次幂之和的第r次根,p 与r由用户指定。
本例选用Pearson correlation,点击Continue钮返回Hierarchical Cluster Analysis对话框,再点击OK钮即完成分析。
10.2.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
共29例样本进入聚类分析,采用相关系数测量技术。先显示各变量间的相关系数,这对于后面选择典型变量是十分有用的。然后显示类间平均链锁法的合并进程,即第一步,X3与X6被合并,它们之间的相关系数最大,为0.863431;第二步,X1与X5合并,其间相关系数为0.624839;第三步,X2与第一步的合并项被合并,它们之间的相关系数为0.602099;第四步,它们与第二步的合并项再合并,其间相关系数为0.338335;第五步,与最后一个变量X4合并,这个相关系数最小,为-0.054485。
按类间平均链锁法,变量合并过程的冰柱图如下。先是X3与X6合并,接着X1与X5合并,然后X3、X6与X2合并,接着再与X1、X5合并,最后加上X4,六个变量全部合并。
下面用更为直观的聚类树状关系图表示,即X1、X2、X3、X5、X6先聚合后与X4再聚合。这表明,在评价儿童营养状态时,可在微量元素钙、镁、铁、铜和血红蛋白5个指标中选择一个,再加上微量元素锰即可,其效果与六个指标都用是基本等价的,但更经济更迅速。
微量元素钙、镁、铁、铜和血红蛋白聚合成一类,在这5个指标中如何选择一个典型指标呢?先按下式计算类中每一变量与其余变量的相关指数(即相关系数的平方)的均值,而后把该值最大的变量作为典型指标。
= (式中m为类中变量个数)
本例相关指数的均值依次为:
= = 0.1947
= = 0.3388
= = 0.3272
= = 0.2164
= = 0.2851 故选择镁(变量X2)典型指标。
返回目录返回全书目录第三节 Discriminant过程
10.3.1 主要功能
调用此过程可完成判别分析。判别分析目前在医学中得以广泛应用,不仅在于它所建立的判别式可用于临床辅助诊断,而且判别分析可分析出各种因素对特定结果的作用力大小,故亦可用于病因学或疾病预后的推测。
返回目录返回全书目录
10.3.2 实例操作
[例10.3]为研究舒张期血压和血浆胆固醇对冠心病的作用,某医师测定了50-59岁冠心病人15例和正常人16例的舒张压和胆固醇指标,结果如下,试作判别分析,建立判别函数以便在临床中用于筛选冠心病人。
10.3.2.1 数据准备
激活数据管理窗口,舒张压、胆固醇的变量名分别以x1、x2表示,将冠心病人资料和正常人资料合并,一同输入。而后,再定义一变量名为result,用于区分冠心病人资料和正常人资料,即冠心病人资料的result值均为1,正常人资料的result值均为2。
10.3.2.2 统计分析
激活Statistics菜单选Classify中的Discriminant...项,弹出Discriminant Analysis对话框(图10.5)。从对话框左侧的变量列表中选result,点击 钮使之进入Grouping Variable框,并点击Define Range...钮,在弹出的Discriminant Analysis:Define Range对话框中,定义判别原始数据的类别区间,本例为两类,故在Minimum处输入1、在Maximum处输入2,点击Continue钮返回Discriminant Analysis对话框。再从对话框左侧的变量列表中选x1、x2,点击 钮使之进入Independents框,作为判别分析的基础数据变量。
图10.5 判别分析对话框
系统提供两类判别方式供选择,一是Enter Independent together,即判别的原始变量全部进入判别方程;另一是Use stepwise method,即采用逐步的方法选择变量进入方程。对于
后者,系统有5种逐步选择方式:
Wilks' lambda:按统计量Wilks λ最小值选择变量;
Unexplained variance:按所有组方差之和的最小值选择变量;
Mahalanobis' distance:按相邻两组的最大Mahalanobis距离选择变量;
Smallest F ratio:按组间最小F值比的最大值选择变量;
Rao's V:按统计量Rao V最大值选择变量。
本例由于变量数仅为2个,倾向让两个变量均进入方程,故选用Enter Independent together判别方式。
点击Statistics...钮,弹出Discriminant Analysis: Statistics对话框,在Descriptive栏中选Means项,要求对各组的各变量作均数与标准差的描述;在Function Coefficients栏中选Unstandardized项,要求显示判别方程的非标准化系数。之后,点击Continue钮返回Discriminant Analysis对话框。
点击Classify...钮,弹出Discriminant Analysis: Classification对话框,在Plot栏选Combined groups项,要求作合并的判别结果分布图;在Display栏选Results for each case项,要求对原始资料根据建立的判别方程作逐一回代重判别,同时选Summary table项,要求对这种回代判别结果进行总结评价。之后,点击Continue钮返回Discriminant Analysis对话框。
点击Save...钮,弹出Discriminant Analysis: Save New Variables对话框,选Predicted group membership项要求将回代判别的结果存入原始数据库中。点击Continue钮返回Discriminant Analysis对话框,之后再点击OK钮即完成分析。
10.3.2.3 结果解释
在结果输出窗口中将看到如下统计数据:
首先,系统提示将判别回代的结果以变量名DIS_1存于原始数据库中。
接着系统显示数据按变量RESULT分组,共31个样本作为判别基础数据进入分析,其中第一组15例,第二组16例。同时,分组给出各变量的均数(means)与标准差(standard deviations)。
下面为典型判别方程的方差分析结果,其特征值(Eigenvalue)即组间平方和与组内平方和之比为1.2392,典型相关系数(Canonical Corr)为0.7439,Wilks λ值为0.446597,经χ2检验,χ2为22.571,P<0.0001。
用户可通过判别方程的标准化系数,确定各变量对结果的作用大小。如本例舒张压(X1)的标准化系数(0.88431)大于胆固醇(X2)的标准化系数(0.82306),因而舒张压对冠心病的影响作用大于胆固醇。考察变量作用大小的另一途径是使用变量与函数间的相关系数,本例显示X1的变量与函数间的相关系数为0.62454,X2为0.54396,同样表明舒张压对冠心病的影响作用大于胆固醇。
根据系统显示的非标准化判别方程系数,得到判别方程为:
D = 0.6379195X1 + 0.8001452X2 - 10.7532968
依此方程,病人组的中心得分点为1.11198,正常人组的中心得分点为-1.04248。本例为二类判别,二类判别以0为分界点,若将某人的舒张压和胆固醇值代入判别方程,求出的判别分>0的为冠心病人,判别分<0的为正常人。
下面为原始数据逐一回代的判别结果显示。其中病人组有3人被错判(编号为1、6、7,打**者),正常人组有3人被错判(编号为17、18、25,打**者)。接着用分布图的形式显示判别结果,图中1代表病人,2代表正常人,每四个1或2代表一个人;图中可见,有三个病人跨过0界进入负值区,被错判为正常人,也有三个正常人跨过0界进入正值区,被错判为病人。最后系统对回代判别的情况作评价,即病人组判别正确率为80.0%,正常人组为81.3%,总判别正确率为80.65%。
系统将判别回代的结果以dis_1为变量名存入原始数据库中,如下图所示。用户可通过翻动原始数据库详细查阅。
SPSS多元线性回归分析实例操作步骤
SPSS统计分析 多元线性回归分析方法操作与分析 实验目得: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率与房屋空置率作为变量,来研究上海房价得变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)与房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19、0 操作过程: 第一步:导入Excel数据文件 1.open datadocument——open data——open; 2、Opening excel data source——OK、
第二步: 1、在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise、 进入如下界面: 2、点击右侧Statistics,勾选RegressionCoefficients(回归系数)选项组中得Estimates;勾选Residuals(残差)选项组中得Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearitydiagnotics;点击Continue、
3、点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中得Standardized Resi dual Plots(标准化残差图)中得Histogram、Normal probability plot;点击Continue、 4、点击右侧Save,勾选Predicted Vaniues(预测值)与Residu als(残差)选项组中得Unstandardized;点击Continue、
统计分析软件SPSS详细教程
10.11统计分析软件&SPSS建立数据 目录 10.11统计分析软件&SPSS建立数据 (1) 10.25数据加工作图 (1) 11. 08绘图解答&描述性分析: (3) 2.描述性统计分析: (4) 四格表卡方检验:(检验某个连续变量的分布是否与某种理论分布一致,如是否符合正态分布) (7) 第七章非参数检验 (10) 1.单样本的非参数检验 (11) (1)卡方检验 (11) (2)二项分布检验 (12) 2.两独立样本的非参数检验 (13) 3.多独立样本的非参数检验 (16) 4.两相关样本的非参数检验 (16) 5.多相关样本的非参数检验 (18) 第五章均值检验与T检验 (20) 1.Means过程(均值检验)( (20) 4. 单样本T检验 (21) 5. 两独立样本T检验 (22) 6.两配对样本T检验 (23) 第六章方差分析 (25) 单因素方差分析: (25) 多因素方差分析: (29) 10.25数据加工作图 1.Excel中随机取值:=randbetween(55,99) 2.SPSS中新建数据,一列40个,正态分布随机数:先在40那里随便输入一个数表示选择40个可用的,然后按一下操作步骤: 3.排序:个案排秩
4.数据选取:数据-选择个案-如果条件满足: 计算新变量: 5.频次分析:分析-统计描述-频率
还原:个案-全部 6.加权: 还原 7.画图: 11. 08绘图解答&描述性分析:1.课后题:长条图
2.描述性统计分析: (1)频数分析:
(2)描述性分析: 描述性统计分析没有图形功能,也不能生成频数表,但描述性分析可以将原始数据转换成标准化得分,并以变量形式存入数据文件中,以便后续分析时应用。 操作: 分析—描述性分析:然后对结果进行筛选,去掉异常值,就得到标准化的数据: 任何形态的数据经过Z标准化处理之后就会是正态分布的<—错误!标准化是等比例缩放的,不会改变数据的原始分布状态, (3)探索分析:(检验是否是正态分布:茎叶图、箱图) 实例:
SPSS多元线性回归分析实例操作步骤
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK.
第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.
SPSS统计分析练习及答案
SPSS 统计分析练习题目 -2012-10-26 学号:________________________ 姓名:___________________________ (注:将本文件以学号+姓名.doc 的形式另存为一个文件,例2008144154葛爽.doc ,然后以附件形式发送至 all689@https://www.wendangku.net/doc/1f3055419.html, ,时间截止到2012年10月31日。没有指明数据文件名称的题目需自行在SPSS 中建立数据文件并录入相应数据,回答问题时应将SPSS 中的主要输出结果粘贴于答案中。) 1.一所国际新闻学校每年从各大高校中招募刚刚毕业的本科生参加培训,进而作为记者参加新闻工作。大多数刚刚毕业的学生以前没有任何做记者的经验,所以在正式成为一名记者之前,必须进行一段时间的学习,作为职业的预备课程。该国际新闻学校于是设计了两种培训方案: 方案A :学生参加为期15周的全天课程听课学习,随后参加预备课程考试; 方案B :学生直接先参加6个月的记者实习,再进行为期15周的全天课程听课学习,最后进行预备课程考试。 为了评估两种方案各自的有效性,学校随机选出了20名学生参加实验。事前还根据他们的文学等相关学科的成绩对这20人进行了分组,20人分成10组,每组中2人的成绩相近,然后随机地将2人分配去参加方案A 和方案B 的培训。 下表是这20人预备课程本学期的成绩单: 1 2 3 4 5 6 7 8 9 10 A 50 68 72 54 42 60 56 72 63 61 B 62 62 58 74 60 66 64 64 78 66 请问上面的数据是否证明了先参加实践对提高平均测试分数的效果显著? Independent Samples Test 1.843.1911.54518.140.60006239921373013731.5455.331.143.6000623993098710987 Equal varia Equal varia assumed X F Sig.vene's Test f ality of Varian t df g. (2-taile Mean ifferenc td. Erro ifferenc Lower Upper 5% Confiden nterval of the Difference t-test for Equality of Means 因p=0.140>0.05,故不能证明先参加实践对提高平均测试分数的效果显著。 2.早在1990年,美国巴维利亚的6个省报道了他们的婴儿死亡率(每1000名活着出生的婴儿的死亡数)以及母乳喂养率(母乳喂养婴儿的比例)的数据如下: 省号码 死亡率(每1000名婴儿中的死亡人数) 母乳喂养率(%) 1 250 60 2 320 30 3 170 90 4 300 60 5 270 40
SPSS多元线性回归分析教程.doc
线性回归分析的SPSS操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1.数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav): 图7-8:回归分析数据输入 2.用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1)操作 ①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
图7-9 线性回归分析主对话框 ②请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。 ③用户在进行回归分析时,还可以选择是否输出方程常数。单击Options…按钮,打开它的对话框,可以看到中间有一项Include constant in equation可选项。选中该项可输出对常数的检验。在Options对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程的准则,这里我们采用系统的默认设置,如图7-11所示。设置完成后点击Continue返回主对话框。 ④在主对话框点击OK得到程序运行结果。
SPSS如何进行线性回归分析操作 精品
SPSS如何进行线性回归分析操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。 也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 用SPSS进行回归分析,实例操作如下: 1.单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9 所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
2.请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。
SPSS统计分析教程独立样本T检验
独立样本T检验 下面我们要用SPSS来做成组设计两样本均数比较的t检验,选择Analyze==>Compare Means==>Independent-Samples T test,系统弹出两样本t检验对话框如下: 将变量X选入test框内,变量 group选入grouping框内,注意这时 下面的Define Groups按钮变黑,表示 该按钮可用,单击它,系统弹出比较组 定义对话框如右图所示: 该对话框用于定义是哪两组相比,在两 个group框内分别输入1和2,表明是 变量group取值为1和2的两组相比。 然后单击Continue按钮,再单击OK 按钮,系统经过计算后会弹出结果浏览 窗口,首先给出的是两组的基本情况描 述,如样本量、均数等(糟糕,刚才的 半天工夫白费了),然后是t检验的结 果如下: Levene's Test for Equality of Variances t-test for Equality of Means F Sig. t df Sig. (2-tailed) Mean Difference Std. Error Difference 95% Confidence Interval of the Difference Lower Upper X Equal variances .032 .860 2.524 22 .019 .4363 .1729 7.777E-02 .7948
差是否齐,这里的戒严结果为F = 0.032,p = 0.860,可见在本例中方差是齐的;第二部分则分别给出两组所在总体方差齐和方差不齐时的t检验结果,由于前面的方差齐性检验结果为方差齐,第二部分就应选用方差齐时的t检验结果,即上面一行列出的t= 2.524,ν=22,p=0.019。从而最终的统计结论为按α=0.05水准,拒绝H0,认为克山病患者与健康人的血磷值不同,从样本均数来看,可认为克山病患者的血磷值较高。
线性回归分析的SPSS操作
第六节线性回归分析的SPSS操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1.数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav): 图7-8:回归分析数据输入 2.用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1)操作 ①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
图7-9 线性回归分析主对话框 ②请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。 ③用户在进行回归分析时,还可以选择是否输出方程常数。单击Options…按钮,打开它的对话框,可以看到中间有一项Include constant in equation可选项。选中该项可输出对常数的检验。在Options对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程的准则,这里我们采用系统的默认设置,如图7-11所示。设置完成后点击Continue返回主对话框。
SPSS教程中文完整版
SPSS统计与分析 统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。现代的数据分析工 作如果离开统计软件几乎是无法正常开展。在准确理解和掌握了各种统计方法原理 之后,再来掌握几种统计分析软件的实际操作,是十分必要的。 常见的统计软件有SAS,SPSS,MINITAB,EXCEL 等。这些统计软件的功能和作用大同小异,各自有所侧重。其中的SAS 和SPSS 是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。特别是SPSS,其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操 作管理和开放的数据接口以及灵活而美观的统计图表制作。SPSS 在各类院校以及科研机构中更为流行。 SPSS(Statistical Product and Service Solutions,意为统计产品与服务解决方案)。自20 世纪60 年代SPSS 诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的SPSS for Windows 大同小异,在本试验课程中我们选择PASW Statistics 18.0 作为统计分析应用试验活动的工具。 1.SPSS 的运行模式 SPSS 主要有三种运行模式: (1)批处理模式 这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上[SPSS for Windows]→[Production Mode Facility]程序运行。 (2)完全窗口菜单运行模式 这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单 易用。 (3)程序运行模式 这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。这种模式要求掌握SPSS 的语句或 脚本语言。本试验指导手册为初学者提供入门试验教程,采用“完全窗口菜单运行模式”。 2.SPSS 的启动 (1)在windows[开始]→[程序]→[PASW],在它的次级菜单中单击“SPSS 12.0 for Windows”即可启动SPSS 软件,进入SPSS for Windows 对话框,如图1.1, 图 1.2 所示。
SPSS统计分析方法及应用教学大纲
《SPSS统计软件》课程教学大纲 一、说明 (一)课程定义: 本课程是网络与新媒体专业的选修课程。SPSS统计软件应用课程,是以计算机科学为支持,将统计软件为运用工具,用所学习的统计学理论与方法为指导,系统介绍对社会经济现象数据的搜集、整理、分析等综合技能。 开设本门课程,能更好的帮助学生理解和掌握统计学的理论及方法,注重学生的实际操作与应用能力的培养。通过该课程的学习,使学生掌握spss统计软件,为其以后的学习和工作打好基础。 (二)编写依据: 本课程大纲根据武汉体育学院体育科技学院人文社科系网络与新媒体专业人才培养方案(2018版)编写。 (三)目的任务: 通过SPSS软件实验教学,培养学生根据实际问题建立SPSS数据文件、利用SPSS软件提供的各种统计功能进行数据的整理与分析,并结合相关的专业知识对分析结果给出解释,为学生以后的工作打下坚实的基础。要求学生课前做好实验准备,课中积极接受和沟通,课后认真总结并写好实验报告。 (四)学时数与学分数: 本课程教学总学时为36课时,2学分。具体学时分配参照下表。 (五)适用对象: 网络与新媒体专业大三学生。 (六)课程编码: KY1810A01
二、教学内容与学时分配 三、教学内容与知识点 第一章SPSS统计分析软件概述 第一节SPSS使用基础 知识点:SPSS软件的基本窗口、退出。 第二节 SPSS的基本运行方式 知识点:窗口菜单方式、程序运行方式、混合运行方式。第二章SPSS数据文件的建立和管理 第一节 SPSS数据文件 知识点:SPSS数据文件的特点、基本组织方法。 第二节 SPSS数据的结构和定义方法
- SPSS经典基础教程(全)
- SPSS入门教程
- spss统计分析基础教程PPT课件
- spss统计分析及应用教程 6课件
- 张文彤,邝春伟著 《SPSS统计分析基础教程》第2版 样章
- SPSS统计分析方法及应用教学大纲
- SPSS统计分析练习及答案
- 第二章SPSS基本统计分析
- 张文彤SPSS统计分析基础教程数据9_11课
- SPSS统计分析基础教程(PPT430)
- spss统计分析基础教程
- 张文彤SPSS统计分析基础教程数据9-11课
- SPSS入门教程
- SPSS统计与分析教程--中文完整版
- SPSS统计分析基础入门
- SPSS统计分析基础教程
- SPSS统计分析—描述性统计分析共37页
- SPSS统计分析软件入门教程
- SPSS_入门教程资料
- spss统计分析基础教程