spss拟合
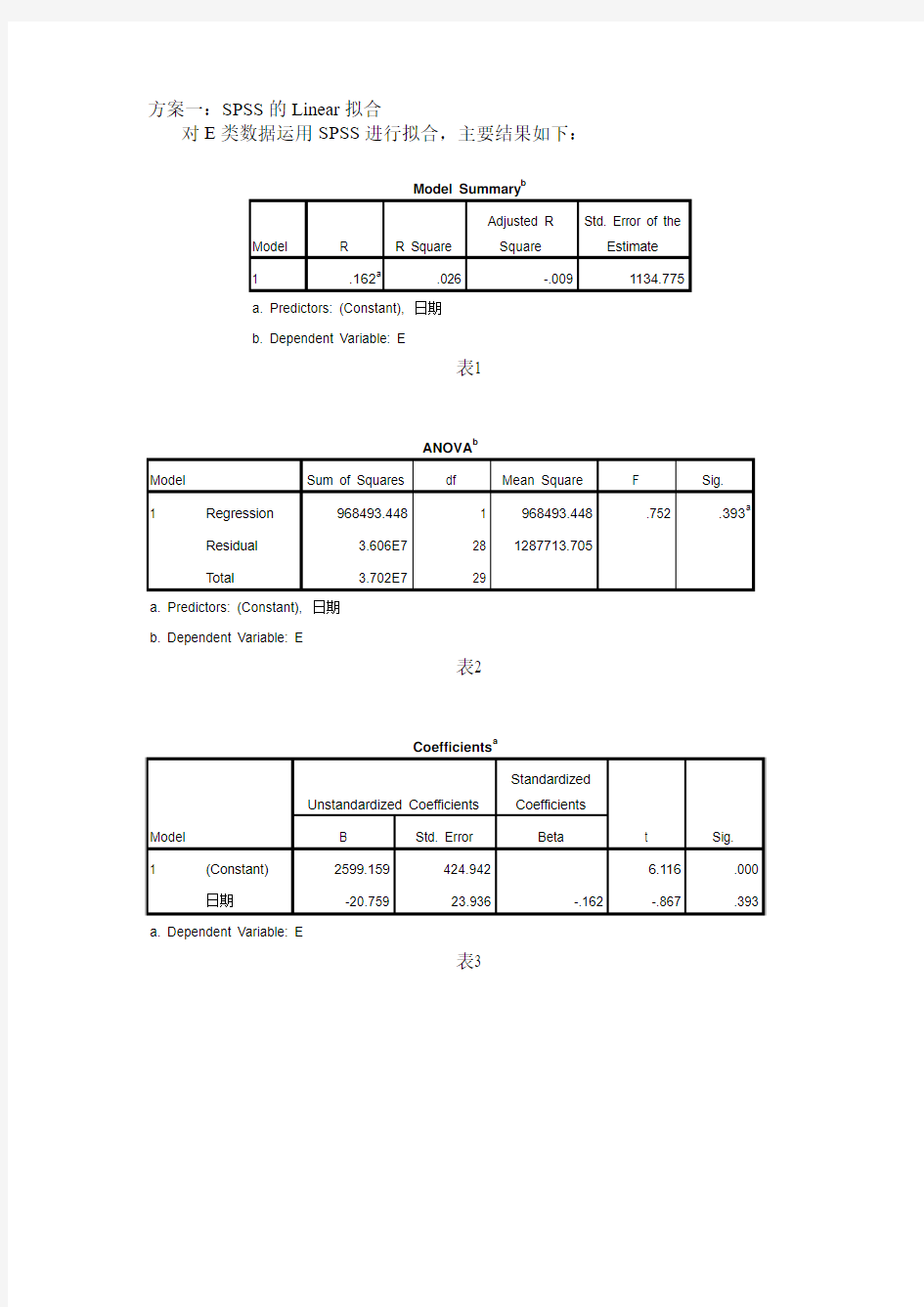

方案一:SPSS的Linear拟合
对E类数据运用SPSS进行拟合,主要结果如下:
表1
表2
表3
图1
根据以上结果可建立回归模型。
根据多元回归模型:e x b x b x b b y k k ++++= 2210 把图3中非标准化回归系数(Unstandardized Coefficients )栏中的“B ”列系数代入上式得预报方程:
2599159759.20+-=∧
x y
预测值的标准差可用剩余军方估计:77.113451287713.70±==∧y
s
通过SPSS 软件预测出其后7天的申请量为:
7月1日:1955.641379310345 7月2日:1934.8827586206899 7月3日:1914.1241379310347 7月4日:1893.3655172413796 7月5日:1872.6068965517243 7月6日:1851.8482758620692
7月7日:1831.089655172414
回归方程的显著性检验:
从表1模型摘要表(Model Summary )和表2方差分析表(ANOV A )中得知:R 方衡量方差拟合优度为0.162,系统自动检验的显著性水平(Sig )为0.393,F 统计量为0.752。然而对于回归模型,R 方衡量方差拟合优度越大越好,一般地,大于0.8说明方差对样本点的拟合效果很好,0.5-0.8之间也可以接受,但是本题中的R 方衡量方差拟合优度为0.162,远小于0.5;除此之外,系统自动检验的显著性水平(Sig )远远超过了0.05(0.01 附件2:(此附录可有可无) F(2) F(3) F的未来七天申请量的的预测值分别为: 3372.154022988506;3368.536002966259;3364.917982944012;3361.2999629217647;3357.681942899518;3354.063922877271;3350.445902855024 G(1) G(2) G(3) G的未来七天申请量的的预测值分别为: 5693.413793103448;5766.853********;5840.292992213571;5913.732591768632;5987.172191323693;6060.611790878755;6134.0513******** H(1) H(2) H(3) G的未来七天申请量的的预测值分别为: 3324.9402298850573;3350.5148683722655;3376.0895068594737;3401.6641453466814;3427.2387838338896;3452.8134223210973;3478.3880608083055 曲线拟合与回归分析 1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下: (1)说明两变量之间的相关方向; (2)建立直线回归方程; (3)计算估计标准误差; (4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。 解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。 用spss回归有: (2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示: =x .0+ y . 567 395 896 (3)、用spss回归知标准误差为80.216(万元)。 (4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。 另外,用MATLAP也可以得到相同的结果: 程序如下所示: function [b,bint,r,rint,stats] = regression1 x = [318 910 200 409 415 502 314 1210 1022 1225]; y = [524 1019 638 815 913 928 605 1516 1219 1624]; X = [ones(size(x))', x']; [b,bint,r,rint,stats] = regress(y',X,0.05); display(b); display(stats); x1 = [300:10:1250]; y1 = b(1) + b(2)*x1; figure;plot(x,y,'ro',x1,y1,'g-'); industry = ones(6,1); construction = ones(6,1); industry(1) =1022; construction(1) = 1219; for i = 1:5 industry(i+1) =industry(i) * 1.045; construction(i+1) = b(1) + b(2)* construction(i+1); end display(industry); display( construction); end 运行结果如下所示:b = 395.5670 0.8958 stats = 1.0e+004 * 0.0001 0.0071 0.0000 1.6035 industry = 1.0e+003 * 1.0220 1.0680 1.1160 1.1663 1.2188 1.2736 SPSS 10.0高级教程十二:多元线性回归与曲线拟合 2009年,国内生物医药的突破之年。不仅有干细胞发现的新突破,还有转基因作物政策的新举措。 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §10.1Linear过程 10.1.1 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。 例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响? 显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 10.1.1.1 界面详解 在菜单中选择Regression==>liner,系统弹出线性回归对话框如下: 除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。 【Dependent框】 用于选入回归分析的应变量。 【Block按钮组】 由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。下面的例子会讲解其用法。 【Independent框】 用于选入回归分析的自变量。 【Method下拉列表】 用于选择对自变量的选入方法,有Enter(强行进入法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)五种。该选项对当前Independent框中的所有变量均有效。 目录 一、SPSS界面介绍 (2) 1、如何打开文件 (2) 2、如何在SPSS中打开excel表 (3) 3、数据视图界面 (3) 4、变量视图界面 (4) 二、如何用SPSS进行频数分析 (11) 三、如何用SPSS进行多变量分析 (15) 四、如何对多选题进行数据分析 (18) 1、对多选题进行变量集定义 (18) 2、对多选题进行频数分析 (21) 3、对多选题进行多变量交互分析 (24) 五、如何就SPSS得出的表在excel中作图 (27) 一、SPSS界面介绍 提前说明:第一,我这里用的是SPSS 20.0 中文汉化版。第二,我教的是傻瓜操作,并不涉及理论讲解,具体的为什么和用什么理论公式来解释请认真去听《社会统计学》的课程。第三,因为是根据我自己的操作和理解来写的,所以可能有些地方显的不那么科学,仍然要说请大家认真去听《社会统计学》的课程,那个才是权威的。 1、如何打开文件 这个东西打开之后界面是这样的: 我们打开一个文件: 要提的一点就是,SPSS保存的数据拓展名是.sav: 2、如何在SPSS中打开excel表 在上图的下拉箭头里找到excel这个选项: 然后你就能找到你要打开的excel表了。 3、数据视图界面 我现在打开了一个数据库。 可以看到左下角这个地方有两个框,两个是可以互相切换的,跟excel切换表一样,跟excel切换表一样: 现在的页面是数据视图,也就是说这一页都是原始数据,这里的一行就是一张问卷,一列就是一个问题,白框里的1234代表的是选项。这个表当时录数据的时候为了方便看,是把ABCD都转换成了1234,所以显示的是1234,当然直接录ABCD也可以,根据具体情况看怎么录,只要能看懂。 多选题的录入全部都是细化到每个选项,比如第四题,选项A选了就是“是”,没选就是 利用S P S S拟合非线性回归模型 利用SPSS拟合非线性回归模型 ——以S型曲线为例 1.原始数据 下表给出了某地区1971—2000年的人口数据(表1)。试用SPSS软件对该地区的人口变化进行曲线拟合,并对今后10年的人口发展情况进行预测。 表1 某地区人口变化数据 年份时间变量t=年份-1970 人口y/人 1971133 815 1972233 981 1973334 004 1974434 165 1975534 212 1976634 327 1977734 344 1978834 458 1979934 498 19801034 476 19811134 483 19821234 488 19831334 513 19841434 497 19851534 511 19861634 520 19871734 507 19881834 509 19891934 521 19902034 513 19912134 515 19922234 517 19932334 519 19942434 519 19952534 521 19962634 521 19972734 523 1998 28 34 525 1999 29 34 525 2000 30 34 527 根据上表中的数据,做出散点图,见图1。 , 33700 33800 3390034000341003420034300 3440034500346001970197219741976197819801982198419861988199019921994199619982000 年份 人口 图1 某地区人口随时间变化的散点图 从图1可以看出,人口随时间的变化呈非线性过程,而且存在一个与横坐标轴平行的渐近线,近似S 曲线。 下面,我们用SPSS 软件进行非线性回归分析拟合计算。 2.用SPSS 进行回归分析拟合计算 在SPSS 中可以直接进行非线性拟合,步骤如下(假定已经进行了数据输入,关于数据输入方法见SPSS 相关基础 教程): SPSS统计与分析 统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。现代的数据分析工作如果离开统计软件几乎是无法正常开展。在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。 常见的统计软件有 SAS,SPSS,MINITAB,EXCEL 等。这些统计软件的功能和作用大同小异,各自有所侧重。其中的 SAS 和 SPSS 是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。特别是 SPSS,其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操作管理和开放的数据接口以及灵活而美观的统计图表制作。SPSS 在各类院校以及科研机构中更为流行。 SPSS(Statistical Product and Service Solutions,意为统计产品与服务解决方案)。自 20 世纪 60 年代 SPSS 诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的 SPSS for Windows 大同小异,在本试验课程中我们选择 PASW Statistics 作为统计分析应用试验活动的工具。 1. SPSS 的运行模式 SPSS 主要有三种运行模式: (1)批处理模式 这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上[SPSS for Windows]→[Production Mode Facility]程序运行。 (2)完全窗口菜单运行模式 这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单易用。 (3)程序运行模式 这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。这种模式要求掌握 SPSS 的语句或脚本语言。本试验指导手册为初学者提供入门试验教程,采用“完全窗口菜单运行模式”。 2. SPSS 的启动 (1)在 windows[开始]→[程序]→[PASW],在它的次级菜单中单击“SPSS for Windows”即可启动 SPSS 软件,进入 SPSS for Windows 对话框,如图,图所示。 图 SPSS 启动 第一章SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下: 1.将数据输入SPSS,并存盘以防断电。 2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3.按题目要求进行统计分析。 4.保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、 上机操作8 曲线回归估计的SPSS分析 习题:落叶松林单位面积的蓄积量(V)和胸高断面积(D)的测定数据如下表, (1)定义变量:打开SPSS数据编辑器,点击“变量视图”,在名称列下输入“V”、“D”,改“类型”栏均为“数字”,“小数”栏分别保留0位和1位。 (2)输入数据:在“数据视图”模式 下,在各名称列输入相应的数据,如图所 示: 二、分析过程 分析→回归→曲线估计,将“V”添加 到“因变量”中,将“D”添加到“变量” 中,勾选模型中的“二次模型”、“复合”、 “对数”、“立方模型”、“指数”、“幂”、“”、 “Logistic”,→确定。 三、输出结果分析 曲线拟合 MODEL: MOD_1. Dependent variable.. V Method.. LOGARITH(对数曲线模型) Listwise Deletion of Missing Data Multiple R (负相关系数) .97210 R Square(决定系数) .94498 Adjusted R Square .93811 Standard Error 6.59944 Analysis of Variance(方差分析): DF(自由度) Sum of Squares Mean Square(均方) Regression(回归) 1 5984.4787 5984.4787 Residuals(残差) 8 348.4213 43.5527 F = 137.40787 Signif F = .0000 (小于0.05,具有极显著性) -------------------- Variables in the Equation (方程中的变量)-------------------- Variable B(系数) SE B Beta T Sig T(T的显著性水平) D 78.152283 6.667083 .972102 11.722 .0000(小于0.05) (Constant) -77.682919 14.110257 -5.505 .0006(小于0.05)分析可知:蓄积量(V)与胸高段面积(D)的相关性为0.97210,它们的F 检验Sig.<0.01,说明蓄积量(V)与胸高段面积(D)达到极显著水平,即蓄积量(V)与胸高段面积(D)的方程具有统计学意义。胸高段面积(D)的T检验Sig.<0.01,说明胸高段面积(D)前的系数具有统计学意义。其方程如下: V=78.152283*ln(D)-77.682919 【摘要】logistic阻滞增长模型在人口预测中有着广泛应用,应用spss软件能较为简便地进行logistic曲线的拟合。文章介绍了spss拟合logistic人口预测方程的两种方法及其步骤,并通过其结果分析比较二者的优缺点。 【关键词】logistic;spss软件;拟合方法 logistic模型为荷兰数学家及生物学家verhulst.pearl在修正非密度方程时提出,其目的为研究受到生存资源制约的情况下生物种群的增长规律。在logistic模型中,有限空间内种群不能无限增长,而是存在着数量上限。由于自然资源、环境条件等因素对种群的增长起着阻滞作用,并且随着种群数量的增大,阻滞作用逐步增大,即实测增长率是一个减函数,且随着种群数量的增大而减小,当种群数量趋于上限时,种群增长亦趋于稳定。由于logistic 阻滞增长模型所需的数据少,计算简单,对中短期时间内的种群数量预测较为准确,亦常应用于人口预测方面。 一、logistic阻滞增长模型 如上文述,人口增长率为以人口数量x为自变量的函数r(x),这里r(x)为减函数。假设r(x)= r ?sx,s>0,这里r为初始值r(),即当人口无生存环境和资源限制时的固有增长率。当人口数量达到人口最大容量,将有r()=0,此时人口达到稳定状态。由线性关系r()=r-s,可得s=r/。假设x是时间t的函数x(t),从而有解变量可分离方程。 二、spss软件拟合logistic人口阻滞增长模型 通过模型方程(ⅰ)可知,logistic模型拟合的重点为参数和的确定。下采用两种spss 软件的回归拟合方法,利用1990-2010年人口调查数据(如表1)进行人口数量的预测。 (一)非线性回归(nonlinear regression)拟合 在spss(spss19.0)的变量视图中定义两变量人口数量x及年份t,在数据视图中由上而下录入人口数据(如图1所示)。 在菜单栏依次选择分析(analyze)―回归(regression)―非线性估计(nonlinear),打开非线性回归窗口。将年末总人口[x]送入因变量一栏,在模型表达式输入框中输入模型公式 a/(1 +(a / 114333 - 1)* exp(- r *(t - 1990)))(如图2)。此处以a代替人口最大容量,由于时间以1990年为初始年份,原方程中的t转为t-1990。选择“参数”项进行参数a和r初始值的设定(如图3),这里a初始值选择人数中的最大值134091(万人),r 的初始值选择1991年的人口增长率0.013,“使用上一分析的起始值”一栏选中,单击“继续”。单击“保存”项,打开对话框如图4,选中预测值和残差项,便于检验模型方程的拟合效果,选择“继续”返回非线性回归窗口,选择“确定”运行。在输出(output)窗口中,可以得到参数a的迭代计算过程、参数估计等内容。由参数估计得参数估计值,=0.0675。r2=1.000。 (二)曲线估计法 采用spss的曲线估计进行模型拟合,须先求参数。对估计的方法很多,这里采用三点法进行求取。 选择分析(analyze)―回归(regression)―曲线估计(curve estimation),打开曲线估计窗口,将年末总人口[x]和年份[t]分别送入因变量和自变量输入框,在“模型”区选中logistic,在上限一栏填入142515.5576,在“保存”对话框中选中预测值和残差,其他依照默认选择。选择“确定”。 三、对两种方法所得拟合方程的讨论 从可决系数r2来看,两种方法所得拟合方程的r2均得1,则两种方法对logistic人口预测模型的拟合性都很好。分别用两种方法所得方程对2011年和2012年的年末人口数进行 利用SPSS拟合非线性回归模型 ——以S型曲线为例 1.原始数据 下表给出了某地区1971—2000年的人口数据(表1)。试用SPSS软件对该地区的人口变化进行曲线拟合,并对今后10年的人口发展情况进行预测。 表1 某地区人口变化数据 年份时间变量t=年份-1970人口y/人 1971133 815 1972233 981 1973334 004 1974434 165 1975534 212 1976634 327 1977734 344 1978834 458 1979934 498 19801034 476 19811134 483 19821234 488 19831334 513 19841434 497 19851534 511 19861634 520 19871734 507 19881834 509 19891934 521 19902034 513 19912134 515 19922234 517 19932334 519 19942434 519 19952534 521 19962634 521 1997 27 34 523 1998 28 34 525 1999 29 34 525 2000 30 34 527 根据上表中的数据,做出散点图,见图1。, 33700 3380033900340003410034200343003440034500346001970197219741976197819801982198419861988199019921994199619982000 年份 人口 图1 某地区人口随时间变化的散点图 从图1可以看出,人口随时间的变化呈非线性过程,而且存在一个与横坐标轴平行的渐近线,近似S 曲线。 下面,我们用SPSS 软件进行非线性回归分析拟合计算。 2.用SPSS 进行回归分析拟合计算 在SPSS 中可以直接进行非线性拟合,步骤如下(假定已经进行了数据输入,关于数据输入方法见SPSS 相关基础 教程): Analysis->Regression->Cubic,在弹出的对话框(见图一)中选择拟合的变量和自变量,本例分别选择y (人口),t (时间变量)为变量(Dependent )和自变 统计分析软件SPSS操作方法 SPSS for Windows的启动和退出 图2 软件启动 在鼠标顺序单击“开始”——“程序”——“SPSS 10.0 for Windows”——“SPSS 10.0 for Windows”启动条之后,SPSS启动界面如图2所示。 图3 启动界面 如需要退出程序可单击右上角的“×”或左上角“File”下的“Exit”即可退出。如果在本次SPSS期间激活的窗口如DATA窗口、OUTPUT窗口的有关内容已经作为文件存盘,则系统直接退出SPSS系统。否则系统会对各窗口一一提问:是否保存×××窗口的内容。用户可按自己的意愿一一给以回答。随后,结束本次SPSS期间,退出SPSS系统。 菜单及窗口介绍 由图3所示,SPSS软件的主菜单主要包括10项: ①File:文件操作;②Edit:文件编辑;③View:视图;④Data:数据文件建立与编辑;⑤Transform:数据转换;⑥Analyze:统计分析;⑦Graphs:统计图表的建立与编辑;⑧Utilities:实用程序;⑨Window:窗口控制;⑩Help:帮助。 而数据窗口主要包括两部分内容,data view和variable view两个表格,这一点与EXCEL 软件极为相似,data view主要用来显示需要处理的数据,而variable view则用来为数据不同的变量的性质进行设置,如名字name、类型type、宽度width、小数点位数Decimals等。以下为下一级子菜单的介绍。 1 File 鼠标单击“File”后即打开下一级下拉子菜单。共计包括16项。现主要介绍常用的命令。 图4 File子菜单 “New”与“Open”命令分别为新建和打开一个文件(包括数据文件data、程序文件syntax、结果文件output、脚本文件script、其他文件other)。需要注意的是SPSS10.0可以直接打开EXCEL2000和数据库的文件(其他还有systat、文本、Lotus等格式的文件)。 第十章:多元线性回归与曲线拟合―― Regression菜单详解(上) (医学统计之星:张文彤) 上次更新日期: 10.1 Linear过程 10.1.1 简单操作入门 10.1.1.1 界面详解 10.1.1.2 输出结果解释 10.1.2 复杂实例操作 10.1.2.1 分析实例 10.1.2.2 结果解释 10.2 Curve Estimation过程 10.2.1 界面详解 10.2.2 实例操作 10.3 Binary Logistic过程 10.3.1 界面详解与实例 10.3.2 结果解释 10.3.3 模型的进一步优化与简单诊断 10.3.3.1 模型的进一步优化 10.3.3.2 模型的简单诊断 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §10.1Linear过程 10.1.1 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。 例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响? 显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 10.1.1.1 界面详解 第二章 SPSS统计应用 第一节 SPSS基础 SPSS(Statistical Package for the Social Sciences)即社会科学统计软件包,是当今世界上公认的最流行、最强大的三大统计分析软件(SPSS、SAS和BMDP)之一。SPSS从10.0版本开始就基于Microsoft Windows 95操作系统上运行,具有Windows软件的共同特征。由于SPSS具有统计、绘图功能强、使用简单方便等优点。受到广大科研工作者的青睐。 在这里主要以12.0版为基础,介绍SPSS的基本使用方法。 一、SPSS安装和运行 1 SPSS v12.0 安装 打开计算机,启动Windows XP操作系统。 1) 将课程配备的光碟放入光盘驱动器中。 2) 启动Windows资源管理器,双击光盘驱动器图标,在目录窗口中找到“SPSS12 install”文件夹,双击进入该文件夹;找到“setup”应用程序,双击后就启动安装。显示欢迎安装SPSS 12.0版以及版权声明(图2-1),浏览后单击“Next”按钮进入下一个画面。 图2-1 SPSS12.0欢迎窗口 3)同意SPSS12.0软件协议 用户阅读“协议”,同意协议,单击“I accept the terms in license agreement”选项。 否则单击“Cancel”退出安装,如图2-2。 图2-2 软件协议窗口 4)阅读SPSS 12.0 自述文件后,单击“Next”按钮,进入下一个界面。5)填写用户信息。 例如:在用户名“Name:”栏填写: Student 在单位名称“Organization:”栏填写: SWU 如图2-3。单击“Next”按钮,进入下一个界面。 图2-3填写用户信息 5)指定SPSS12.0系统的安装目录(图2-4) 第一章 SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下: 1. 将数据输入SPSS,并存盘以防断电。 2. 进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的 检验方法。 3. 按题目要求进行统计分析。 4. 保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、工具栏。特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。 有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer按钮,即可进入上面的主界面。 1.1.2 定义变量 该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变量代表血磷值,习惯上取名为X,另一个变量代表观察对象是健康人还是克山病人,习惯上取名为GROUP。 对数据的统计分析格式不太熟悉的朋友请先学习统计软件第一课。 选择菜单Data==>Define Variable。系统弹出定义变量对话框如下: 该变量定义对话框在SPSS 10.0版中已被取消,这里的操作只适合9.0~7.0版的用户。 SPSS—非线性回归(模型表达式)案例解析 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型 非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面: 点击确定按钮,得到如下结果: 放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面 在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果: 通过“二次”和“S“ 两个模型的对比,可以看出S 模型的拟合度明显高于“二次”模型的拟合度(0.912 >0.900)不过,几乎接近 接着,我们采用S 模型,得到如下所示的结果: 结果分析: 1:从ANOVA表中可以看出:总体误差= 回归平方和+ 残差平方和(共计:0.782)F统计量为(240.216)显著性SIG为(0.000)由于0.000<0.01 (所以具备显著性,方差齐性相等) 2:从“系数”表中可以看出:在未标准化的情况下,系数为(-0.986)常数项为2.672 所以S 型曲线的表达式为:Y(销售量)=e^(b0+b1/t) = e^(2.672-0.986/广告费用) 当数据通过标准化处理后,常数项被剔除了,所以标准化的S型表达式为:Y(销售量) = e^(-0.957/广告费用) 下面,我们直接采用“非线性”模型来进行操作 第一步:确定“非线性模型” 从绘图中可以看出:广告费用在1千万——4千多万的时候,销售量增加的跨度较大,当广告费用超过“4千多万"的时候,增加幅度较小,在达到6千多万”达到顶峰,之后呈现下降趋势。 从图形可以看出:它符合The asymptotic regression model (渐近回归模型) 表达式为:Y(销售量)= b1 + b2*e∧b3*(广告费用) SPSS数据统计分析与实践主讲:周涛副教授 北京师范大学资源学院 2007-12-18 教学网站:https://www.wendangku.net/doc/103870909.html,/Courses/SPSS 第十八章:曲线拟合(Curve Estimation)Contents: 1. SPSS提供的曲线拟合模型 2. SPSS曲线拟合实例 SPSS Curve Estimation z The Curve Estimation procedure allows you to quickly estimate regression statistics and produce related plots for 11 different models. z Curve Estimation is most appropriate when the relationship between the dependent variable(s) and the independent variable is not necessarily linear. Curve Estimation Data Considerations z Data.The dependent and independent variables should be quantitative. If you select Time instead of a variable from the working data file as the independent variable, the Curve Estimation procedure generates a time variable where the length of time between cases is uniform. z Assumptions. Screen your data graphically to determine how the independent and dependent variables are related (linearly, exponentially, etc.). The residuals of a good model should be randomly distributed and normal. If a linear model is used, the following assumptions should be met. For each value of the independent variable, the distribution of the dependent variable must be normal. The variance of the distribution of the dependent variable should be constant for all values of the independent variable. The relationship between the dependent variable and the independent variable should be linear, and all observations should be independent. S P S S线性回归描述公司内部档案编码:[OPPTR-OPPT28-OPPTL98-OPPNN08] SPSS?高级教程十二:多元线性回归与曲线拟合 2009年,国内生物医药的突破之年。不仅有干细胞发现的新突破,还有转基因作物政策的新举措。 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §Linear过程 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。 例:请分析在数据集Fat 中变量fat对变量spovl的大小有无影响显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 界面详解 在菜单中选择Regression==>liner,系统弹出线性回归对话框如下: 除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。 【Dependent框】 用于选入回归分析的应变量。 【Block按钮组】 由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。下面的例子会讲解其用法。 【Independent框】 用于选入回归分析的自变量。 【Method下拉列表】 用于选择对自变量的选入方法,有Enter(强行进入法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)五种。该选项对当前Independent框中的所有变量均有效。【Selection Variable框】 选入一个筛选变量,并利用右侧的Rules钮建立一个选择条件,这样,只有满足该条件的记录才会进入回归分析。 【Case Labels框】 选择一个变量,他的取值将作为每条记录的标签。最典型的情况是使用记录ID号的变量。 SPSS中文版工具 统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。现代的数据分析工作如果离开统计软件几乎是无常开展。在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。 常见的统计软件有SAS,SPSS,MINITAB,EXCEL等。这些统计软件的功能和作用小异,各自有所侧重。其中的SAS和SPSS是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。特别是SPSS,其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操作管理和开放的数据接口以及灵活而美观的统计图表制作。SPSS在各类院校以及科研机构中更为流行。 SPSS(Statistical Product and Service Solutions,意为统计产品与服务解决方案)。自20世纪60年代SPSS诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的SPSS for Windows小异,在本试验课程中我们选择PASW Statistics 18.0作为统计分析应用试验活动的工具。 1.SPSS的运行模式 SPSS主要有三种运行模式: (1)批处理模式 这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上[SPSS for Windows]→[Production Mode Facility]程序运行。 (2)完全窗口菜单运行模式 这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单易用。 (3)程序运行模式 这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。这种模式要求掌握SPSS的语句或脚本语言。 本试验指导手册为初学者提供入门试验教程,采用“完全窗口菜单运行模式”。2.SPSS的启动 (1)在windows[开始]→[程序]→[PASW],在它的次级菜单中单击“SPSS 12.0 for Windows”即可启动SPSS软件,进入SPSS for Windows对话框,如图1.1,图1.2所示。 SPSS词汇中英文 Absolute deviation, 绝对离差 Absolute number, 绝对数 Absolute residuals, 绝对残差 Acceleration array, 加速度立体阵 Acceleration in an arbitrary direction, 任意方向上的加速度 Acceleration normal, 法向加速度 Acceleration space dimension, 加速度空间的维数Acceleration tangential, 切向加速度 Acceleration vector, 加速度向量 Acceptable hypothesis, 可接受假设 Accumulation, 累积 Accuracy, 准确度 Actual frequency, 实际频数 Adaptive estimator, 自适应估计量 Addition, 相加 Addition theorem, 加法定理 Additivity, 可加性 Adjusted rate, 调整率 Adjusted value, 校正值 Admissible error, 容许误差 Aggregation, 聚集性 Alternative hypothesis, 备择假设 Among groups, 组间 Amounts, 总量 Analysis of correlation, 相关分析 Analysis of covariance, 协方差分析 Analysis of regression, 回归分析 Analysis of time series, 时间序列分析 Analysis of variance, 方差分析 Angular transformation, 角转换 ANOVA (analysis of variance), 方差分析 ANOVA Models, 方差分析模型 Arcing, 弧/弧旋 Arcsine transformation, 反正弦变换 Area under the curve, 曲线面积 AREG , 评估从一个时间点到下一个时间点回归相关时的误差ARIMA, 季节和非季节性单变量模型的极大似然估计Arithmetic grid paper, 算术格纸 Arithmetic mean, 算术平均数 Arrhenius relation, 艾恩尼斯关系 Assessing fit, 拟合的评估 Associative laws, 结合律spss曲线拟合与回归分析
SPSS线性回归描述
SPSS基本操作傻瓜教程
最新利用SPSS拟合非线性回归模型
SPSS教程中文完整版
SPSS简明教程(绝对受用)
曲线回归估计的SPSS分析
LOGISTIC人口预测模型的SPSS拟合方法分析
利用SPSS拟合非线性回归模型
SPSS操作方法
spss之线性回归详解(张文彤)
SPSS教程(完整)
SPSS简明教程实例及方法(相当有用)
SPSS—非线性回归(模型表达式)案例
SPSS曲线拟合
SPSS线性回归描述(终审稿)
SPSS19.0中文版教程
spss统计分析软件词汇中英文
- spss曲线拟合与回归分析
- SPSS在曲线拟合中的
- 回归分析曲线拟合
- SPSS线性回归描述
- SPSS模型拟合运算
- SPSS在曲线拟合中的剖析
- [教材]利用SPSS拟合非线性回归模型
- SPSS曲线回归多元分析等
- spss之线性回归详解(张文彤)
- SPSS曲线回归多元分析等
- Logistic人口预测模型的SPSS拟合方法分析
- spss曲线拟合与回归分析
- spss曲线拟合与回归分析
- SPSS在非线性回归分
- 回归分析的模型SPSS
- SPSS 10.0高级教程十二:多元线性回归与曲线拟合
- 用spss拟合曲线
- SPSS—非线性回归(模型表达式)案例
- spss统计分析软件词汇中英文
- LOGISTIC人口预测模型的SPSS拟合方法分析