二分图匹配(匈牙利算法和KM算法)

前言:
高中时候老师讲这个就听得迷迷糊糊,有一晚花了通宵看KM的Pascal代码,大概知道过程了,后来老师说不是重点,所以忘的差不多了。都知道二分图匹配是个难点,我这周花了些时间研究了一下这两个算法,总结一下
1.基本概念
M代表匹配集合
未盖点:不与任何一条属于M的边相连的点
交错轨:属于M的边与不属于M的边交替出现的轨(链)
可增广轨:两端点是未盖点的交错轨
判断M是最大匹配的标准:M中不存在可增广轨
2.最大匹配,匈牙利算法
时间复杂度:O(|V||E|)
原理:
寻找M的可增广轨P,P包含2k+1条边,其中k条属于M,k+1条不属于M。修改M 为M&P。即这条轨进行与M进行对称差分运算。
所谓对称差分运算,就是比如X和Y都是集合,X&Y=(X并Y)-(x交Y)
有一个定理是:M&P的边数是|M|+1,因此对称差分运算扩大了M
实现:
关于这个实现,有DFS和BFS两种方法。先列出DFS的代码,带注释。这段代码来自中山大学的教材
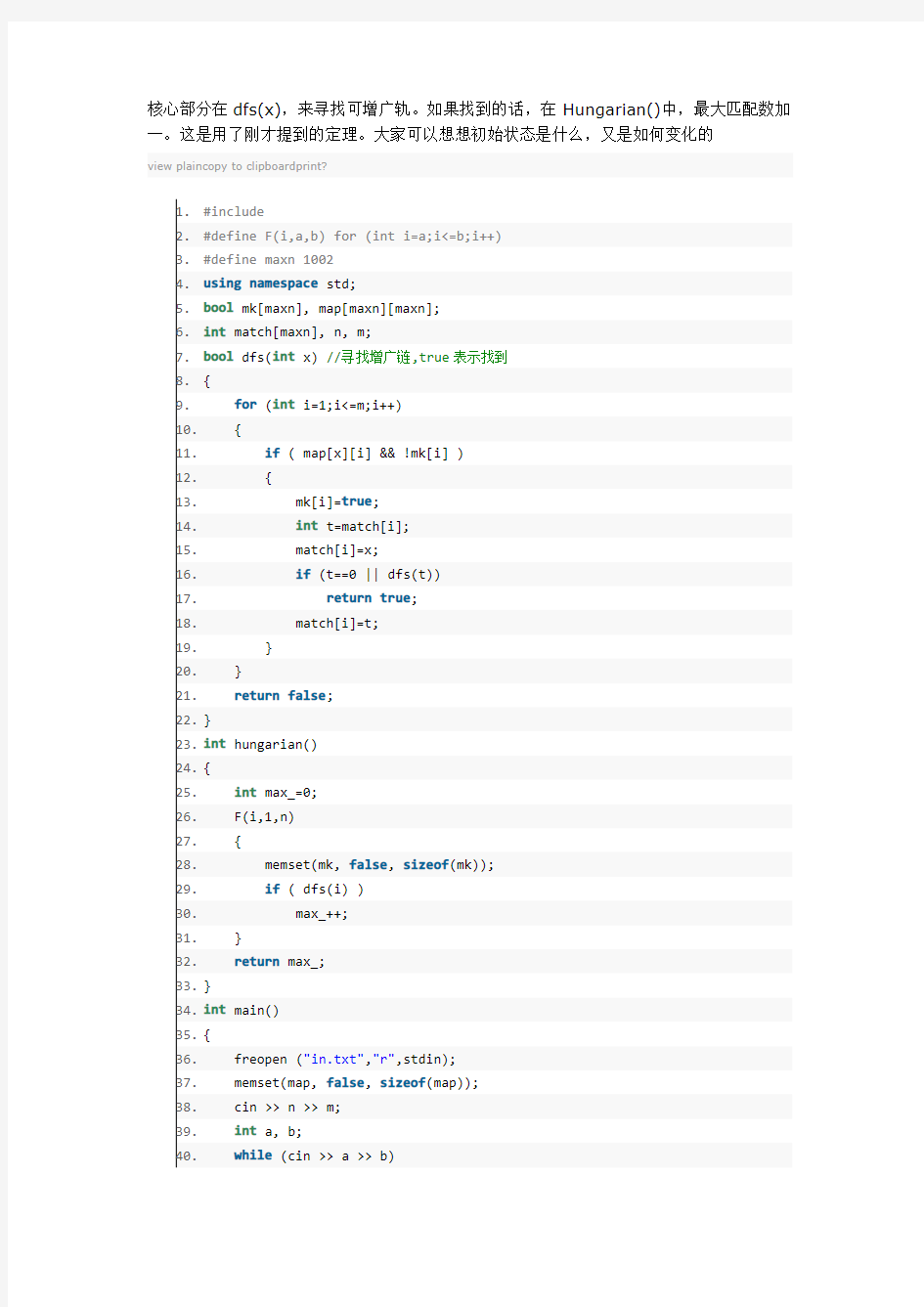
核心部分在dfs(x),来寻找可增广轨。如果找到的话,在Hungarian()中,最大匹配数加一。这是用了刚才提到的定理。大家可以想想初始状态是什么,又是如何变化的
view plaincopy to clipboardprint?
第二种方法BFS,来自我的学长cnhawk
核心步骤还是寻找可增广链,过程是:
1.从左的一个未匹配点开始,把所有她相连的点加入队列
2.如果在右边找到一个未匹配点,则找到可增广链
3.如果在右边找到的是一个匹配的点,则看它是从左边哪个点匹配而来的,将那个点出发的所有右边点加入队列
这么说还是不容易明白,看代码吧
view plaincopy to clipboardprint?
3.最佳匹配
加权图中,权值最大的最大匹配
KM算法:
概念:
f(v)是每个点的一个值,使得对任意u,v C V,f(u)+f(v)>=w[e u,v]集合H:一个边集,使得H中所有u,v满足f(u)+f(v)=w[e u,v]
等价子图:G f(V,H),标有f函数的G图
理论:
对于f和G f,如果有一个理想匹配集合M p,则M p最优。
对于任意匹配集合M,weight(M) KM算法的实质是扩展G f,直到找到理想的匹配集合 伪代码 view plaincopy to clipboardprint? 最后给一个代码,跟伪代码的思路不是很一样。从网上找的 view plaincopy to clipboardprint? Maigo的KM算法讲解(的确精彩) 顶点Yi的顶标为B[i],顶点Xi与Yj之间的边权为w[i,j]。在算法执行过程中的任一时刻,对于任一条边(i,j),A[i]+B[j]>=w[i,j]始终成立。KM 算法的正确性基于以下定理: * 若由二分图中所有满足A[i]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。 这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。 初始时为了使A[i]+B[j]>=w[i,j]恒成立,令A[i]为所有与顶点Xi关联的边的最大权,B[j]=0。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。 我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是X顶点。现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现: 两端都在交错树中的边(i,j),A[i]+B[j]的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。 两端都不在交错树中的边(i,j),A[i]和B[j]都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。 X端不在交错树中,Y端在交错树中的边(i,j),它的A[i]+B[j]的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。 X端在交错树中,Y端不在交错树中的边(i,j),它的A[i]+B[j]的值有所减小。也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。 现在的问题就是求d值了。为了使A[i]+B[j]>=w[i,j]始终成立,且至少有一条边进入相等子图,d应该等于min{A[i]+B[j]-w[i,j]|Xi在交错树中,Yi不在交错树中}。 以上就是KM算法的基本思路。但是朴素的实现方法,时间复杂度为 O(n4)——需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。实际上KM算法的复杂度是可以做到O(n3)的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与A[i]+B[j]-w[i,j]的较小值。这样,在修改顶标时,取所有不在交错树中的Y顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的slack值都减去d。 前言: 高中时候老师讲这个就听得迷迷糊糊,有一晚花了通宵看KM的Pascal代码,大概知道过程了,后来老师说不是重点,所以忘的差不多了。都知道二分图匹配是个难点,我这周花了些时间研究了一下这两个算法,总结一下 1.基本概念 M代表匹配集合 未盖点:不与任何一条属于M的边相连的点 交错轨:属于M的边与不属于M的边交替出现的轨(链) 可增广轨:两端点是未盖点的交错轨 判断M是最大匹配的标准:M中不存在可增广轨 2.最大匹配,匈牙利算法 时间复杂度:O(|V||E|) 原理: 寻找M的可增广轨P,P包含2k+1条边,其中k条属于M,k+1条不属于M。修改M 为M&P。即这条轨进行与M进行对称差分运算。 所谓对称差分运算,就是比如X和Y都是集合,X&Y=(X并Y)-(x交Y) 有一个定理是:M&P的边数是|M|+1,因此对称差分运算扩大了M 实现: 关于这个实现,有DFS和BFS两种方法。先列出DFS的代码,带注释。这段代码来自中山大学的教材 核心部分在dfs(x),来寻找可增广轨。如果找到的话,在Hungarian()中,最大匹配数加一。这是用了刚才提到的定理。大家可以想想初始状态是什么,又是如何变化的 view plaincopy to clipboardprint? 第二种方法BFS,来自我的学长cnhawk 核心步骤还是寻找可增广链,过程是: 1.从左的一个未匹配点开始,把所有她相连的点加入队列 2.如果在右边找到一个未匹配点,则找到可增广链 3.如果在右边找到的是一个匹配的点,则看它是从左边哪个点匹配而来的,将那个点出发的所有右边点加入队列 这么说还是不容易明白,看代码吧 诚信声明 本人声明: 我所呈交的本科毕业设计论文是本人在导师指导下进行的研究工作及取得的研究成果。尽我所知,除了文中特别加以标注和致谢中所罗列的内容以外,论文中不包含其他人已经发表或撰写过的研究成果。与我一同工作的同志对本研究所做的任何贡献均已在论文中作了明确的说明并表示了谢意。本人完全意识到本声明的法律结果由本人承担。 申请学位论文与资料若有不实之处,本人承担一切相关责任。 本人签名:日期:2010 年05 月20日 毕业设计(论文)任务书 设计(论文)题目: 学院:专业:班级: 学生指导教师(含职称):专业负责人: 1.设计(论文)的主要任务及目标 (1) 了解图象匹配技术的发展和应用情况,尤其是基于特征的图象匹配技术的发展和应用。 (2) 学习并掌握图像匹配方法,按要求完成算法 2.设计(论文)的基本要求和内容 (1)查阅相关中、英文文献,完成5000汉字的与设计内容有关的英文资料的翻译。(2)查阅15篇以上参考文献,其中至少5篇为外文文献,对目前国内外图象匹配技术的发展和应用进行全面综述。 (3)学习图象匹配算法,尤其是基于特征的图象匹配算法。 (4)实现并分析至少两种基于特征的图象匹配算法,并分析算法性能。 3.主要参考文献 [1]谭磊, 张桦, 薛彦斌.一种基于特征点的图像匹配算法[J].天津理工大学报,2006, 22(6),66-69. [2]甘进,王晓丹,权文.基于特征点的快速匹配算法[J].电光与控制,2009,16(2), 65-66. [3]王军,张明柱.图像匹配算法的研究进展[J].大气与环境光学学报,2007,2(1), 12-15. 二分图的最大匹配完美匹配和匈牙利算法 匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是二部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。这篇文章讲无权二分图(unweighted bipartite graph)的最大匹配(maximum matching)和完美匹配(perfect matching),以及用于求解匹配的匈牙利算法(Hungarian Algorithm);不讲带权二分图的最佳匹配。二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。准确地说:把一个图的顶点划分为两个不相交集U 和V ,使得每一条边都分别连接U、V 中的顶点。如果存在这样的划分,则此图为一个二分图。二分图的一个等价定义是:不含有「含奇数条边的环」的图。图 1 是一个二分图。为了清晰,我们以后都把它画成图 2 的形式。匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。例如,图3、图4 中红色的边就是图 2 的匹配。我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。例如图 3 中1、4、5、7 为匹配点,其他顶点为未匹配点;1-5、4-7为匹配边,其他边为非匹配边。最大匹配:一个图所有匹配中,所含匹 配边数最多的匹配,称为这个图的最大匹配。图 4 是一个最大匹配,它包含4 条匹配边。完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图 4 是一个完美匹配。显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。但并非每个图都存在完美匹配。举例来说:如下图所示,如果在某一对男孩和女孩之间存在相连的边,就意味着他们彼此喜欢。是否可能让所有男孩和女孩两两配对,使得每对儿都互相喜欢呢?图论中,这就是完美匹配问题。如果换一个说法:最多有多少互相喜欢的男孩/女孩可以配对儿?这就是最大匹配问题。基本概念讲完了。求解最大匹配问题的一个算法是匈牙利算法,下面讲的概念都为这个算法服务。交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫交替路。增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。例如,图5 中的一条增广路如图6 所示(图中的匹配点均用红色标出):增广路有一个重要特点:非匹配边比匹配边多一条。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏匹配的性质。交换后,图中的匹配边数 二分图的最优匹配(KM算法) KM算法用来解决最大权匹配问题:在一个二分图内,左顶点为X,右顶点为Y,现对于每组左右连接XiYj有权wij,求一种匹配使得所有wij的和最大。 基本原理 该算法是通过给每个顶点一个标号(叫做顶标)来把求最大权匹配的问题转化为求完备匹配的问题的。设顶点Xi的顶标为A[ i ],顶点Yj的顶标为B[ j ],顶点Xi与Yj之间的边权为w[i,j]。在算法执行过程中的任一时刻,对于任一条边(i,j),A[ i ]+B[j]>=w[i,j]始终成立。 KM算法的正确性基于以下定理: 若由二分图中所有满足A[ i ]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最大权匹配。 首先解释下什么是完备匹配,所谓的完备匹配就是在二部图中,X点集中的所有点都有对应的匹配或者是 Y点集中所有的点都有对应的匹配,则称该匹配为完备匹配。 这个定理是显然的。因为对于二分图的任意一个匹配,如果它包含于相等子图,那么它的边权和等于所有顶点的顶标和;如果它有的边不包含于相等子图,那么它的边权和小于所有顶点的顶标和。所以相等子图的完备匹配一定是二分图的最大权匹配。 初始时为了使A[ i ]+B[j]>=w[i,j]恒成立,令A[ i ]为所有与顶点Xi关联的边的最大权,B[j]=0。如果当前的相等子图没有完备匹配,就按下面的方法修改顶标以使扩大相等子图,直到相等子图具有完备匹配为止。 我们求当前相等子图的完备匹配失败了,是因为对于某个X顶点,我们找不到一条从它出发的交错路。这时我们获得了一棵交错树,它的叶子结点全部是X顶点。现在我们把交错树中X顶点的顶标全都减小某个值d,Y顶点的顶标全都增加同一个值d,那么我们会发现: 1)两端都在交错树中的边(i,j),A[ i ]+B[j]的值没有变化。也就是说,它原来属于相等子图,现在仍属于相等子图。 2)两端都不在交错树中的边(i,j),A[ i ]和B[j]都没有变化。也就是说,它原来属于(或不属于)相等子图,现在仍属于(或不属于)相等子图。 3)X端不在交错树中,Y端在交错树中的边(i,j),它的A[ i ]+B[j]的值有所增大。它原来不属于相等子图,现在仍不属于相等子图。 4)X端在交错树中,Y端不在交错树中的边(i,j),它的A[ i ]+B[j]的值有所减小。也就说,它原来不属于相等子图,现在可能进入了相等子图,因而使相等子图得到了扩大。(针对之后例子中x1->y4这条边) 现在的问题就是求d值了。为了使A[ i ]+B[j]>=w[i,j]始终成立,且至少有一条边进入相等子图,d应该等于: Min{A[i]+B[j]-w[i,j] | Xi在交错树中,Yi不在交错树中}。 改进 以上就是KM算法的基本思路。但是朴素的实现方法,时间复杂度为O(n4)——需要找O(n)次增广路,每次增广最多需要修改O(n)次顶标,每次修改顶标时由于要枚举边来求d值,复杂度为O(n2)。实际上KM算法的复杂度是可以做到O(n3)的。我们给每个Y顶点一个“松弛量”函数slack,每次开始找增广路时初始化为无穷大。在寻找增广路的过程中,检查边(i,j)时,如果它不在相等子图中,则让slack[j]变成原值与A[ i ]+B[j]-w[i,j]的较小值。这样,在修改顶标时,取所有不在交错树中的Y 顶点的slack值中的最小值作为d值即可。但还要注意一点:修改顶标后,要把所有的不在交错树中的Y顶点的slack值都减去d(因为:d的定义为 min{ (x,y)| Lx(x)+ Ly(y)- W(x,y), x∈ S, y? T } 本文基于相关性分析来实现图像匹配 第一步:读取图像。 分别读取以下两幅相似的图片,显示效果如下: 第二步:选择一副图像的子区域。用户可以通过鼠标选择需要截取的图像部分,用于匹配。随机选取图片的一块区域,如下图: 第三步:使用相关性分析两幅图像 采用协方差的方式计算相关系数,分析图片的相似性。 1.协方差与相关系数的概念 对于二维随机变量(,)X Y ,除了关心它的各个分量的数学期望和方差外,还需要知道这两个分量之间的相互关系,这种关系无法从各个分量的期望和方差来说明,这就需要引进描述这两个分量之间相互关系的数字特征——协方差及相关系数。 若X Y 与相互独立,则()( )0 Y E X EX Y EY σ--???? =≠;若()()0E X EX Y EY --≠????,则表 示X 与Y 不独立,X 与Y 之间存在着一定的关系 设 (,)X Y 是二维随机变量, 则称()()E X EX Y EY --????为X 与Y 的协方差(Covariance ),记为 ()cov ,X Y 或XY σ,即 ()()()cov ,XY X Y E X EX Y EY σ==--???? 若 0X σ≠ 且0Y σ=≠,则称 XY XY X Y σρσσ== 为X 与Y 的相关系数(Correlation Coefficient )。()c o v ,X Y 是 有量纲的量,而XY ρ则是无量纲的量.协方差常用下列公式计算 ()() =-? cov,X Y E XY EX EY 2.用全搜索和协方差计算截取图片与另外一幅图片的各点的相似度。c=normxcorr2(sub_I1(:,:,1),I2(:,:,1)); 第四步:找到整幅图像的偏移。 [max_c,imax]=max(abs(c(:))); [ypeak,xpeak]=ind2sub(size(c),imax(1)); [m,n]=size(sub_I1); xbegin=xpeak-n+1; ybegin=ypeak-m+1; xend=xpeak; yend=ypeak; 从原图像提取匹配到的图像 extracted_I1=I2(ybegin:yend,xbegin:xend,:); 第五步:显示匹配结果。 相关性匹配图: 找出峰值即最相似区域的中心 用改进的匈牙利算法求解运输问题 李雪娇,于洪珍 中国矿业大学信电学院,江苏徐州 (221008) Email :liaohuchushan@https://www.wendangku.net/doc/1612017214.html, 摘 要:本文提出用改进的匈牙利算法求解运输问题。此算法不但可以直接求取最优解,而且在运量受限制的运输问题中有很好的应用。 关键词:改进,匈牙利算法,运输问题,最优解 0. 引言 在现实生活中,我们常常会遇到许多运输问题。运输问题的求解多采用表上作业法。在此方法中,我们需要先利用最小元素法或西北角法求出一组基本可行解,再对此解检验其最优性。若此解非最优解,则又要进行解的改进。这一过程比较麻烦,尤其对一些结构不太大的模型,编程时往往过于繁琐。 同时,经典运输问题在实际应用中有很大的局限性, 对一些运输量受限制或运输能力受限制的运输问题,我们无法用表上作业法直接求取。在此,我们采用改进的匈牙利算法处理这类运输问题。为了便于描述,设物资供应量12[...]m A a a a =,物资需求量12[...]n B b b b =,从到i A j B 的单物的物资运价,最小运输量 (假设m )。 i j C i j L n >1. 匈牙利算法[1][4] 匈牙利算法的基本思想是修改效益矩阵的行和列,使得每行和每列中至少有一个零元素。经过一定的变换,得到不同行、不同列只有一个零元素。从而得到一个与这些零元素相匹配的完全分配方案。这种方法总是在有限步内收敛于一个最优解。该方法的理论基础是:在效益矩阵的任何行或列中,加上或减去一个常数后不会改变最优解的分配。求解步骤如下: 第一步:使指派问题的系数矩阵经变换后,在各行各列中都出现零元素,即从系数矩阵的每行(或列)元素中减去该行(或列)的最小元素。 第二步:寻求找n 个独立的零元素,以得到最优解:(1)从只有一个0元素的行(或列)开始,对这个0元素加圈,记为θ。然后划去此元素所在列(或行)的其他0元素,记作?。反复进行,直到所有的0元素被划完。(2)若仍有没有划圈的0元素,则从剩有0元素最少的行开始,比较这行0元素所在各列中0元素的数目,选择0元素少的那列的0元素加圈θ,然后划掉同行同列的其他0元素,反复进行直到所有的0元素被划掉或圈出。 (3)若元素的数目m 等于矩阵的阶数,那么指派问题的最优解已得到。若m ,则转入下一步。 n n <第三步:作最少的直线覆盖所有0元素,以确定该系数矩阵中能找到最多的独立元素数:若l ,必须再变换当前的系数矩阵,才能找到个独立的0元素,为此转第四步;若l ,而,应回到第二步(2),另行试探。 n 二分图匹配 1.最大匹配(hdu1068) Girls and Boys Time Limit: 20000/10000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Submission(s): 6410 Accepted Submission(s): 2888 Problem Description the second year of the university somebody started a study on the romantic relations between the students. The relation “romantically involved” is defined between one girl and one boy. For the study reasons it is necessary to find out the maximum set satisfying the condition: there are no two students in the set who have been “romantically involved”. The result of the program is the number of students in such a set. The input contains several data sets in text format. Each data set represents one set of subjects of the study, with the following description: the number of students the description of each student, in the following format student_identifier:(number_of_romantic_relations) student_identifier1 student_identifier2 student_identifier3 ... or student_identifier:(0) The student_identifier is an integer number between 0 and n-1, for n subjects. For each given data set, the program should write to standard output a line containing the result. Sample Input 7 0: (3) 4 5 6 1: (2) 4 6 2: (0) 3: (0) 4: (2) 0 1 5: (1) 0 6: (2) 0 1 3 Doctor的图论计划之——二分图最大匹配 第一讲二分图的最大匹配经典之匈牙利算法 二分图,顾名思义就是分成了两个部分的图……很白痴的解释(自己吐槽了先),但吐槽的同时我们也要发现一些二分图的基本性质! 性质1 二分图之所以分成了两个部分,那是因为单独的一个部分中的任意两点不连通! 性质2 二分图匹配——匈牙利算法中我们只需记录集合1到集合2的单向边就可以了(注意看上边的图,箭头是单向的)思考这是为什么! 但是!二分图确实是无向图!!!只不过匈牙利算法只是从一个集合另一个集合走一遍罢了!!!! 性质3 树是一种特殊的二分图! 紫色的结点构成集合1,绿色的结点构成集合2,换句话说,儿子和爸爸打仗时爷爷和 孙子站在同一战线!(也可以认为是儿子和爸妈吵架时总是爷爷奶奶护着,小时候有这样的记忆没有?反正我没有!) PS:树就是无回路懂不? 性质3 对于任意二分图,其包含的环一定全部是偶环!(充要可证) 可以证明,含有奇数条边的环一定有两个在相同集合内的点有边相连! 也就是说——二分图的bfs子树一定不含奇环! 接下来说一下二分图求最大匹配的算法——匈牙利算法 【例1】传说中的多米诺骨牌覆盖问题 在一个n*m的棋盘上,摆放一些1*2大小的多米诺骨牌,但棋盘某些地方是坏 掉的,即不能将骨牌置于这些坏掉的格子上,求最多能摆上的骨牌数量 【例2】传说中的猎人打鸟问题 猎人要在n*n的格子里打鸟,他可以在某一行中打一枪,这样此行中的所有鸟都被 打掉,也可以在某一列中打,这样此列中的所有鸟都打掉.问至少打几枪,才能打光 所有的鸟? 【例3】传说中的搞对象问题 一保守教师想带学生郊游, 却怕他们途中谈恋爱,他认为满足下面条件之一的两 人谈恋爱几率很小: (1)身高差>40 (2) 性别相同(3) 爱好不同类型的音乐(4) 爱好同类型的运动 告诉你每个同学的信息,问老师最多能带多少学生? 这样的问题如何解决?搜索?怎么搜?会不会超时?答案很简单,三道题中的元素都可以用很简单的方式分成两个互不相干的部分,因此可以用二分图匹配来解决这个问题:形象的说,我们规定搞基和百合都是不允许的,已知一群男人和女人,他们可以看做图中的顶点,男人构成了集合A,女人构成了集合B,边表示这名男人和这名女人互相有好感(可以配成一对)不考虑个人因素,现在希望为这些饥渴的男男女女找到最多的配对数(脚踏两只船也是不允许的!)为了解决这样的问题我们才引入了二分图的匹配算法——匈牙利算法! 匈牙利算法是一种用增广路求二分图最大匹配的算法。它由匈牙利数学家Edmonds于1965年提出,因而得名。 如果暴搜的话那么无疑时间复杂度将成为O(2^E)!无法快速实现,于是我们就提出了更为高效的算法,这种算法是从网络流演变而来,但这里我们抛开所有网络流的知识,但从这一算法的角度来进行阐释! 解释一些常用的名词 交错轨:所谓交错轨,还有一种更为文雅的说法叫增广轨,这种说法让人不禁联想到蛋疼的网络流算法,所以我更喜欢用一种与网络流无关的说法来称呼它,下面我们来举几个交错轨的例子: 匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes K?nig和Jen? Egerváry的工作之上创建起来的。 匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。 二分图: 二分图又称作二部图,是图论中的一种特殊模型。设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。图一就是一个二分图。 匈牙利算法: 匈牙利算法是由匈牙利数学家Edmonds于1965年提出,因而得名。匈牙利算法是基于Hall定理中充分性证明的思想,它是一种用增广路径求二分图最大匹配的算法。 Hall定理: 二部图G中的两部分顶点组成的集合分别为X, Y; X={X1, X2, X3,X4, .........,Xm}, Y={y1, y2, y3, y4 , .........,yn}, G中有一组无公共点的边,一端恰好为组成X的点的充分必要条件是:X中的任意k个点至少与Y中的k个点相邻。(1≤k≤m) 匹配: 给定一个二分图G,在G的一个子图M中,M的边集中的任意两条边都不依附于同一个顶点,则称M是一个匹配。图一中红线为就是一组匹配。 未盖点: 设Vi是图G的一个顶点,如果Vi 不与任意一条属于匹配M的边相关联,就称Vi 是一个未盖点。如图一中的a 3、b1。 用匈牙利算法求二分图的最大匹配 什么是二分图,什么是二分图的最大匹配,这些定义我就不讲了,网上随便都找得到。二分图的最大匹配有两种求法,第一种是最大流(我在此假设读者已有网络流的知识);第二种就是我现在要讲的匈牙利算法。这个算法说白了就是最大流的算法,但是它跟据二分图匹配这个问题的特点,把最大流算法做了简化,提高了效率。匈牙利算法其实很简单,但是网上搜不到什么说得清楚的文章。所以我决定要写一下。 最大流算法的核心问题就是找增广路径(augment path)。匈牙利算法也不例外,它的基本模式就是: 初始时最大匹配为空 while 找得到增广路径 do 把增广路径加入到最大匹配中去 可见和最大流算法是一样的。但是这里的增广路径就有它一定的特殊性,下面我来分析一下。 (注:匈牙利算法虽然根本上是最大流算法,但是它不需要建网络模型,所以图中不再需要源点和汇点,仅仅是一个二分图。每条边也不需要有方向。) 图1是我给出的二分图中的一个匹配:[1,5]和[2,6]。图2就是在这个匹配的基础上找到的一条增广路径:3->6->2->5->1->4。我们借由它来描述一下二分图中的增广路径的性质: (1)有奇数条边。 (2)起点在二分图的左半边,终点在右半边。 (3)路径上的点一定是一个在左半边,一个在右半边,交替出现。(其实二分图的性质就决定了这一点,因为二分图同一边的点之间没有边相连,不要忘记哦。) (4)整条路径上没有重复的点。 (5)起点和终点都是目前还没有配对的点,而其它所有点都是已经配好对的。(如图1、图2所示,[1,5]和[2,6]在图1中是两对已经配好对的点;而起点3和终点4目前还没有与其它点配对。) (6)路径上的所有第奇数条边都不在原匹配中,所有第偶数条边都出现在原匹配中。(如图1、图2所示,原有的匹配是[1,5]和[2,6],这两条配匹的边在图2给出的增广路径中分边是第2和第4条边。而增广路径的第1、3、5条边都没有出现在图1给出的匹配中。) (7)最后,也是最重要的一条,把增广路径上的所有第奇数条边加入到原匹配中 图像匹配的主要方法分析 在我国的图像处理中,有很多的关键技术正在不断的发展和创新之中。这些相关技术的发展在很大程度上推动了我国图像处理事业的发展。作为图像处理过程中的关键技术,图像匹配技术正在受到越来越多的关注。文章针对图像匹配的主要方法进行详细的论述,希望通过文章的阐述和分析能够为我国的图像匹配技术的发展和创新贡献微薄力量,同时也为我国图像处理技术的发展贡献力量。 标签:图像处理;图像匹配;特征匹配;方法 在我国的图像处理技术中,图像的匹配技术不仅仅是其中的重要组成部分,同时还是很多图像技术的发展创新的技术基础。例如图像技术中的立体视觉技术;图像技术中的运动分析技术以及图像技术中的数据融合技术等。通过上述内容可以看出,在我国的图像技术中,图像匹配技术具有非常广泛的应用。随着我国的相关技术不断的创新和发展,对于图像匹配技术的要求也是越来越高。这样就要求我国的图像匹配技术有更深层次的研究和发展。我国现阶段的研究主要是针对图像匹配过程中的匹配算法进行研究,希望借助研究能够更加有效的提升在实际的工作应用中的图像质量,同时也能够在很大程度上提升图像处理的图像分别率。文章的主要陈述点是通过图像匹配技术的具体方法进行优点和缺点的分析,通过分析优点和缺点来论述我国图像处理技术中的图像匹配技术的发展方向以及改进措施。近些年出现了很多的图像匹配方法,针对现阶段的新方法以及新的研究思路我们在实际的应用过程中要有一个非常清醒的选择。文章针对这一问题主要有三个内容的阐述。第一个是图像匹配技术的算法融合;第二个是图像匹配技术中的局部特征算法;最后一个是图像匹配技术中的模型匹配具体算法。 1 现阶段在世界范围内较为经典的图像匹配技术的算法 关于现阶段在世界范围内的较为经典的图像匹配技术的算法的阐述,文章主要从两个方面进行分析。第一个方面是ABS图像匹配算法。第二个方面是归一化相互关图像匹配算法。下面进行详细的论述和分析。 (1)算法一:ABS图像匹配算法。ABS图像匹配算法最主要的原理就是要使用模板的图像以及相应的匹配图像的搜索用窗口之间的转换差别来显示两者之间的关联性。图像匹配的大小在数值上等同于模板图像的窗口滑动顺序。窗口的每一次滑动都会引起模板图像的匹配计算。现阶段ABS的算法主要有三个,如下: 在选择上述三种计算方法的过程中要根据实际情况社情相应的阀值,否则会出现很高的失误率。上述的三种算法使用范围较狭窄。只使用与等待匹配的图像在模板影像的计算。 (2)算法二:归一化相互关图像匹配算法。归一化相互关的图像匹配算法在现阶段是较为经典的算法。通常专业的称法为NC算法。此计算方法主要是采 将xyl程序存入M文件,在matlab中先写入邻接矩阵marix,而后再写function [z,ans]=xyl(marix) 回车得出结果 程序文件 xyl.m function [z,ans]=xyl(marix) %输入效率矩阵 marix 为方阵; %若效率矩阵中有 M,则用一充分大的数代替; %输出z为最优解,ans为最优分配矩阵; %////////////////////////////////////////////////// a=marix; b=a; %确定矩阵维数 s=length(a); %确定矩阵行最小值,进行行减 ml=min(a'); for i=1:s a(i,:)=a(i,:)-ml(i); end %确定矩阵列最小值,进行列减 mr=min(a); for j=1:s a(:,j)=a(:,j)-mr(j); end % start working num=0; while(num~=s) %终止条件是“(0)”的个数与矩阵的维数相同 %index用以标记矩阵中的零元素,若a(i,j)=0,则index(i,j)=1,否则index(i,j)=0 index=ones(s); index=a&index; index=~index; %flag用以标记划线位,flag=0 表示未被划线, %flag=1 表示有划线过,flag=2 表示为两直线交点 %ans用以记录 a 中“(0)”的位置 %循环后重新初始化flag,ans flag = zeros(s); ans = zeros(s); %一次循环划线全过程,终止条件是所有的零元素均被直线覆盖, %即在flag>0位,index=0 while(sum(sum(index))) %按行找出“(0)”所在位置,并对“(0)”所在列划线, %即设置flag,同时修改index,将结果填入ans for i=1:s t=0; 二分图最大匹配算法 令G = (X,*,Y)是一个二分图,其中,X = {x1,x2,...xm}, Y = {y1,y2,...yn}。令M为G中的任一个匹配。 1)讲X的所有不与M的边关联的顶点标上(@),并称所有的顶点为未被扫描的。转到2)。2)如果在上一步没有新的标记加到X的顶点上,则停止。否则转到3)。 3)当存在X被标记但未被扫描的顶点时,选择一个被标记但未被扫描的X的顶点,比如,xi,用(xi)标记Y的所有顶点,这些顶点被不属于M且尚未标记的边连到xi .现在,顶点xi 是被扫描的。如果不存在被标记但未被扫描的顶点,则转到4)。 4)如果在步骤3)没有新的标记被标到Y的顶点上,则停止。否则,转到5)。 5)当存在Y被标记但未被扫描的顶点时,选择Y的一个被标记但未被扫描的顶点,比如yi,用(yi)标记X的顶点,这些顶点被属于M且尚未标记的边连到yi.现在,顶点yi是被扫描的。如果不存在被标记但未被扫描的顶点,则转到2)。 也可以叙述为: [ZZ]匈牙利算法 关键在于匈牙利算法的递归过程中有很多重复计算的节点,而且这种重复无法避免,他不能向动态规划一样找到一个“序”将递归改为递推。 算法中的几个术语说明: 1。二部图: 如果图G=(V,E)的顶点集何V可分为两个集合X,Y,且满足X∪Y = V, X∩Y=Φ,则G称为二 部图; 图G的边集用E(G)表示,点集用V(G)表示。 2。匹配: 设M是E(G)的一个子集,如果M中任意两条边在G中均不邻接,则称M是G的一个匹配。M中的 —条边的两个端点叫做在M是配对的。 3。饱和与非饱和: 若匹配M的某条边与顶点v关联,则称M饱和顶点v,并且称v是M-饱和的,否则称v 是M-不 饱和的。 4。交互道: 若M是二分图G=(V,E)的一个匹配。设从图G中的一个顶点到另一个顶点存在一条道路,这条道路是由属于M的边和不属于M的边交替出现组成的,则称这条道路为交互道。 5。可增广道路: 若一交互道的两端点为关于M非饱和顶点时,则称这条交互道是可增广道路。显然,一条边的两端点非饱和,则这条边也是可增广道路。 6。最大匹配: 如果M是一匹配,而不存在其它匹配M',使得|M'|>|M|,则称M是最大匹配。其中|M|表 图的匹配 一、什么是图的匹配 1.图的定义 无向图:无向图G 是指非空有限集合V G ,和V G 中某些元素的无序对的集合E G ,构成的二元组(V G ,E G )。V G 称为G 的顶点集,其中的元素称为G 的顶点。E G 称为G 的边集,其中的元素称为G 的边。在不混淆的情况下,有时记V =V G ,E =E G 。如果V ={v 1,…,v n },那么E 中的元素e 与V 中某两个元素构成的无序对(v i ,v j )相对应,记e =v i v j ,或e =v j v i 。在分析问题时,我们通常可以用小圆圈表示顶点,用小圆圈之的连线表示边。 二分图:设G 是一个图。如果存在V G 的一个划分X ,Y ,使得G 的任何一条边的一个端点在X 中,另一个端点在Y 中,则称G 为二分图,记作G =(X ,Y ,E)。如果G 中X 的每个顶点都与Y 的每个顶点相邻,则称G 为完全二分图。 2.匹配的相关概念 设G =(V ,E)是一个图,E M ?,如果M 不含环且任意两边都不相邻,则称M 为G 的一个匹配。G 中边数最多的匹配称为G 的最大匹配。 对于图G =(V ,E),在每条边e 上赋一个实数权w(e)。设M 是G 的一个匹配。定义∑∈=m e e w M w )()(,并称之为匹配M 的权。G 中权最大的匹配称为G 的最大权匹配。如果 对一切,e ∈E ,w(e)=1,则G 的最大权匹配就是G 的最大匹配。 设M 是图G=(V ,E)的一个匹配,v i ∈V 。若v i 与M 中的边相关联,则称v i 是M 饱和点,否则称v i 为M 非饱和点。 如果G 中每个顶点都是M 饱和点,则称M 为G 的完美匹配。 设M 是G 的一个匹配,P 是G 的一条链。如果P 的边交替地一条是M 中的边,一条不是M 中的边,则称P 为M 交错链。类似地,我们可以定义G 的交错圈。易知,G 的交错圈一定是偶圈。 一条连接两个不同的M 非饱和点的M 交错链称为M 增广链。 两个集合S 1与S 2的“异或”操作S 1⊕S 2是指集合S 1⊕S 2=(S 1∩S 2)\(S 1∪S 2) 容易看出,设M 是G 的匹配,P 是G 中的M 增广链、则M ⊕P 也是G 的匹配,而且1+=⊕M P M 。 图表 1 “异或”操作 可以证明,G 中匹配M 是最大匹配当且仅当G 中没有M 增广链。 匈牙利算法(Edmonds算法)步聚: (1)首先用(*)标记X中所有的非M顶点,然后交替进行步骤(2),(3)。 (2)选取一个刚标记(用(*)或在步骤(3)中用(y i)标记)过的X中顶点,例如顶点x ,如果x i与y为同一非匹配边的两端点,且在本步骤中y尚未被标记过,则用(x i)i 去标记Y中顶点y。重复步骤(2),直至对刚标记过的X中顶点全部完成一遍上述过程。 (3)选取一个刚标记(在步骤(2)中用(x i)标记)过的Y中结点,例如y i,如果y i与x为 同一匹配边的两端点,且在本步骤中x尚未被标记过,则用(y i)去标记X中结点x。 重复步骤(3),直至对刚标记过的Y中结点全部完成一遍上述过程。 (2),(3)交替执行,直到下述情况之一出现为止: (I)标记到一个Y中顶点y,它不是M顶点。这时从y出发循标记回溯,直到(*)标 记的X中顶点x,我们求得一条交替链。设其长度为2k+1,显然其中k条是匹配 边,k+1条是非匹配边。 (II)步骤(2)或(3)找不到可标记结点,而又不是情况(I)。 (4)当(2),(3)步骤中断于情况(I),则将交替链中非匹配边改为匹配边,原匹配边改为非 匹配边(从而得到一个比原匹配多一条边的新匹配),回到步骤(1),同时消除一切现有 标记。 (5)对一切可能,(2)和(3)步骤均中断于情况(II),或步骤(1)无可标记结点,算法终止 (算法找不到交替链). 以上算法说穿了,就是从二分图中找出一条路径来,让路径的起点和终点都是还没有匹配过的点,并且路径经过的连线是一条没被匹配、一条已经匹配过交替出现。找到这样的路径后,显然路径里没被匹配的连线比已经匹配了的连线多一条,于是修改匹配图,把路径里所有匹配过的连线去掉匹配关系,把没有匹配的连线变成匹配的,这样匹配数就比原来多1个。不断执行上述操作,直到找不到这样的路径为止。 下面给出此算法的一个例子: 一共有RecuCal.m LockMap.m BuildMatrix.m Edmonds.m GUI1.m 这几个文件,我把它们合到一块粘上去了,你再把他们分开保存就可以了. 其中前三个文件都是为建立邻接矩阵服务的,Edmonds.m是匈牙利算法的主文件,GUI1.m只是调用Edmonds.m做个界面而已。 调用关系是GUI1.m调用Edmonds.m;Edmonds.m调用BuildMatrix.m和LockMap.m ;LockMap.m调用RecuCal.m 最后运行GUI1.m就ok了 #LockMap.m function [LMA, LMB] = LockMap(n, m) % LOCKMAP - 求解满足条件锁并设置相应的映射 % 输入参数:n 表槽数,m 表高度数。 % 输出参数:LMA,LMB 分别为二维矩阵表示自然数到满足条件锁之间的映射。 global jiA ouB ary A B mm N N = n; mm = m; jiA=0; ouB=0; A=[]; B=[]; ary = zeros(1, n); RecuCal(n); LMA=A; LMB=B; [lena, n] = size(LMA); [lenb, n] =size(LMB); if lena>lenb temp = LMA; LMA=LMB;LMB=temp; temp = lena;lena=lenb;lenb=temp; end #RecuCal.m function RecuCal(n) % RECUCAL - 递归函数 global jiA ouB ary A B mm N if n ==1 for k=1:mm % 调用递归函数时要用到的变量所以 % 设为全局 ary(1) = k; Max = max(ary); Min = min(ary); num = 0; neighbor = 0; for i=1:N num = num + (Max-ary(i))*(ary(i)-Min); 电话拨号数图的匹配算法研究和高效实现 摘要:该文首先对拨号数图匹配的规则语法进行了分类讲解,通过对规则语法的分析,给出了数图匹配的算法分析,并以伪代码的形式进行了算法实现。整个算法过程包含规则预处理和拨号匹配两个过程,该文对算法实现的流程图进行了详细的描述。 关键词:voip;数图(digitmap);超越匹配(over matched)中图分类号:tp312 文献标识码:a 文章编号:1009-3044(2013)04-0807-04 research & efficient implementation of digitmap matching algorithm wang xiao-lan (electromechanical department, suzhou institute of trade&commerce, suzhou 215009, china) abstract: the digitmap matching rules was classified and discussed in this paper. by analyzing the rules, the digitmap matching algorithm is illustrated and implemented in the form of pseudo-code. the whole process of algorithm holds two phases: rules preprocessing and digit matching. further more, this paper described in details the flow chart of implementation of the algorithm. key words: voip; digitmap; over matched 网络技术与多媒体技术的发展,促进了通信技术的综合化、数字Ku二分图最大权匹配(KM算法)hn
二分图匹配(匈牙利算法和KM算法)
基于特征的图像匹配算法毕业设计论文(含源代码)
二分图的最大匹配完美匹配和匈牙利算法
算法学习:图论之二分图的最优匹配(KM算法)
图像匹配搜索算法
用改进的匈牙利算法求解运输问题
二分图匹配
二分图的最大匹配经典之匈牙利算法
匈牙利算法
用匈牙利算法求二分图的最大匹配
图像匹配的主要方法分析
可以直接用的匈牙利算法
图论二分图最大匹配算法
图的匹配——匈牙利算法与KM算法
匈牙利算法
二分图最大匹配算法的应用及Matlab实现+++
电话拨号数图的匹配算法研究和高效实现
- 二分图匹配(匈牙利算法)
- 二分图最大匹配及其应用
- 二分图(匈牙利,KM算法详解)
- 二分图匹配(匈牙利算法和KM算法)
- 二分图匹配算法及其应用【开题报告】
- 二分图(匈牙利,KM算法详解)
- 二分图及二分图匹配
- 二分图最大匹配
- 二分图最大匹配算法的应用及Matlab实现
- 主要定理二分图的最大匹配算法二分图的带权重的最大匹配
- Ku二分图最大权匹配(KM算法)hn
- 二分图匹配――匈牙利算法和KM算法简介.
- 二分图最大匹配算法的应用及Matlab实现(举例)
- Ku二分图最大权匹配(KM算法)hn
- 二分图及匹配算法
- 二分图相关问题
- 二分图的匹配和图论
- 二分图匹配匹配
- 经典算法之二分图
- 二分图最大匹配问题(贪心算法)