CDMA容量计算公式A
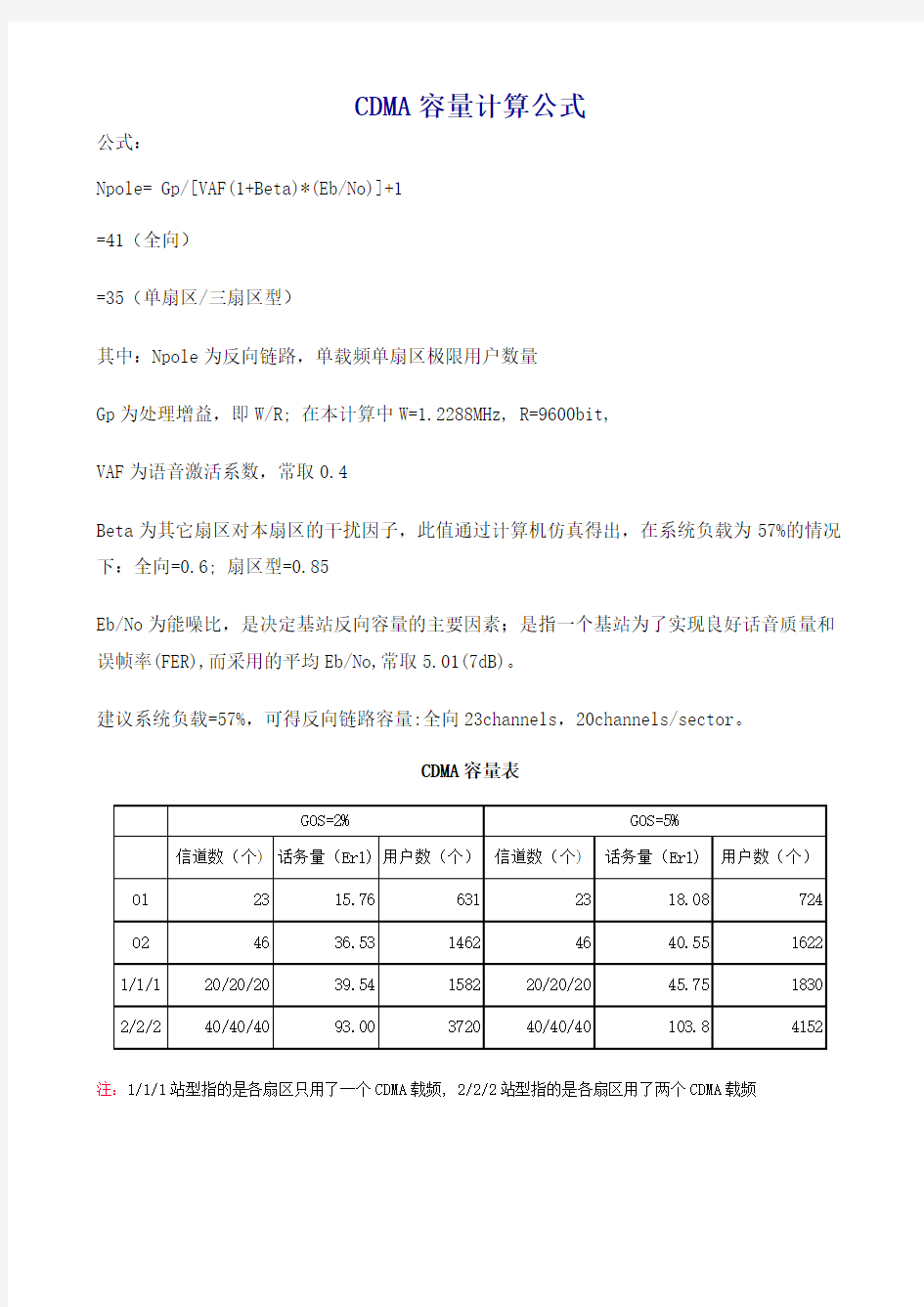

CDMA容量计算公式
公式:
Npole= Gp/[VAF(1+Beta)*(Eb/No)]+1
=41(全向)
=35(单扇区/三扇区型)
其中:Npole为反向链路,单载频单扇区极限用户数量
Gp为处理增益,即W/R; 在本计算中W=1.2288MHz, R=9600bit,
VAF为语音激活系数,常取0.4
Beta为其它扇区对本扇区的干扰因子,此值通过计算机仿真得出,在系统负载为57%的情况下:全向=0.6; 扇区型=0.85
Eb/No为能噪比,是决定基站反向容量的主要因素;是指一个基站为了实现良好话音质量和误帧率(FER),而采用的平均Eb/No,常取5.01(7dB)。
建议系统负载=57%,可得反向链路容量:全向23channels,20channels/sector。
CDMA容量表
注:1/1/1站型指的是各扇区只用了一个CDMA载频, 2/2/2站型指的是各扇区用了两个CDMA载频
GSM容量表
附件:各公司容量计算公式
一、北电
Npole=[W/R*(1/(Eb/No))*(1/VAF)+1]*f*G
=[(1.2288*10^6/9600)*(1/106.5/10)*(1/0.4)+1]*0.65*0.85
=40.1
W:CDMA带宽,为1.2288MHz
R:数据速率,为9600bit/s
VAF: 语音激活系数,为0.4
f: 频率复用因子,为0.65
G: 扇区化因子,为0.85
建议系统负载=50%,可得反向链路容量20channels/sector
二、摩托罗拉
Npole=[W/R*(1/(Eb/(No+Io)adjusted)*(1/VAF)]*(1/(1+beta))*G =[(1.2288*10^6/9600)*(1/106.5/10)*(1/0.4)]*(1/(1+0.7)*0.8 =36(全向)
=29(单扇区/三扇区型)
W:CDMA带宽,为1.2288MHz
R:数据速率,为9600bit/s
VAF: 语音激活系数,为0.4
beta: 外部基站对内部基站的干扰,为0.7
G: 扇区化因子,为0.80
建议系统负载=75%,可得反向链路容量:全向27channels,21channels/sector。
附件二:
基站容量
小区容量目前工程上一般取值为全向24个用户即24个信道(满配置),定向21个,即小区负载达到60%左右,所能容纳用户数如表所示(设定每用户忙时话务量为0.02Erl),由于CDMA 基站扇区间的物理信道资源是一个资源池的概念,所有物理信道可以共享,所以在网络实际运行中,它所能处理的话务量,还要大于设计理论值,这是其它制式不具有的特性。
安防监控硬盘容量计算公式
1080P、720P、4CIF、CIF所需要的理论带宽在视频监控系统中,对存储空间容量的大小需求是与画面质量的高低、及视频线路等都有很大关系。下面对视频存储空间大小与传输带宽的之间的计算方法做以先容。 比特率是指每秒传送的比特(bit)数。单位为bps(BitPerSecond),比特率越高,传送的数据越大。比特率表示经过编码(压缩)后的音、视频数据每秒钟需要用多少个比特来表示,而比特就是二进制里面最小的单位,要么是0,要么是1。比特率与音、视频压缩的关系,简单的说就是比特率越高,音、视频的质量就越好,但编码后的文件就越大;假如比特率越少则情况恰好相反。 码流(DataRate)是指视频文件在单位时间内使用的数据流量,也叫码率,是视频编码中画面质量控制中最重要的部分。同样分辨率下,视频文件的码流越大,压缩比就越小,画面质量就越高。 上行带宽就是本地上传信息到网络上的带宽。上行速率是指用户电脑向网络发送信息时的数据传输速率,比如用FTP上传文件到网上往,影响上传速度的就是“上行速率”。 下行带宽就是从网络上下载信息的带宽。下行速率是指用户电脑从网络下载信息时的数据传输速率,比如从FTP服务器上文件下载到用户电脑,影响下传速度的就是“下行速率”。 不同的格式的比特率和码流的大小定义表: 传输带宽计算: 比特率大小×摄像机的路数=网络带宽至少大小; 注:监控点的带宽是要求上行的最小限度带宽(监控点将视频信息上传到监控中心);监控中心的带宽是要求下行的最小限度带宽(将监控点的视频信息下载到监控中心);例:电信2Mbps的ADSL宽带,50米红外摄像机理论上其上行带宽是512kbps=64kb/s,其下行带宽是2Mbps=256kb/。 例:监控分布在5个不同的地方,各地方的摄像机的路数:n=10(20路)1个监控中心,远程监看及存储视频信息,存储时间为30天。不同视频格式的带宽及存储空间大小计算如下: 地方监控点: CIF视频格式每路摄像头的比特率为512Kbps,即每路摄像头所需的数据传输带宽为
(完整版)样本量计算(DOC)
1.估计样本量的决定因素 1.1资料性质 计量资料如果设计均衡,误差控制得好,样本可以小于30例;计数资料即使误差控制严格,设计均衡,样本需要大一些,需要30-100例。 1.2研究事件的发生率 研究事件预期结局出现的结局(疾病或死亡),疾病发生率越高,所需的样本量越小,反之就要越大。 1.3 1.4 1.5 度为 1.6 1.7 1.8双侧检验与单侧检验 采用统计学检验时,当研究结果高于和低于效应指标的界限均有意义时,应该选择双侧检验,所需 样本量就大;当研究结果仅高于或低于效应指标的界限有意义时,应该选择单侧检验,所需样本量 就小。当进行双侧检验或单侧检验时,其α或β的Ua?界值通过查标准正态分布的分位数表即可得到。
2.样本量的估算 由于对变量或资料采用的检验方法不同,具体设计方案的样本量计算方法各异,只有通过查阅资料,借鉴他人的经验或进行预实验确定估计样本量决定因素的参数,便可进行估算。 护理中的量性研究可以分为3种类型:①描述性研究:如横断面调查,目的是描述疾病的分布情况或现况调查;②分析性研究:其目的是分析比较发病的相关因素或影响因素;③实验性研究:即队列研究或干预实验。研究的类型不同,则样本量也有所不同。 2.1描述性研究 例. =0.1, 2.2 2.2.1探索有关变量的影响因素研究 有关变量影响因素研究的样本量大多是根据统计学变量分析的要求,样本数至少是变量数的5-10倍。例如,如果研究肺结核患者生存质量及影响因素,首先要考虑影响因素有几个,然后通过文献回顾,可知约有12个预测影响变量,如年龄、性别、婚姻、文化程度、家庭月收入、医疗付费方式、病程、排菌、喀血、结核中毒症状、心理健康、社会支持,那么研究的变量就可以在60-120例。这是一种较为简便的估算样本量的方法,在获得相关文献支持下,最好根据公式计算,计量
等额本息和等额本金计算公式
等额本息和等额本金计算公式 等额本金: 本金还款和利息还款: 月还款额=当月本金还款+当月利息式1 其中本金还款是真正偿还贷款的。每月还款之后,贷款的剩余本金就相应减少: 当月剩余本金=上月剩余本金-当月本金还款 直到最后一个月,全部本金偿还完毕。 利息还款是用来偿还剩余本金在本月所产生的利息的。每月还款中必须将本月本金所产生的利息付清: 当月利息=上月剩余本金×月利率式2 其中月利率=年利率÷12。据传工商银行等某些银行在进行本金等额还款的计算方法中,月利率用了一个挺孙子的算法,这里暂且不提。 由上面利息偿还公式中可见,月利息是与上月剩余本金成正比的,由于在贷款初期,剩余本金较多,所以可见,贷款初期每月的利息较多,月还款额中偿还利息的份额较重。随着还款次数的增多,剩余本金将逐渐减少,月还款的利息也相应减少,直到最后一个月,本金全部还清,利息付最后一次,下个月将既无本金又无利息,至此,全部贷款偿还完毕。 两种贷款的偿还原理就如上所述。上述两个公式是月还款的基本公式,其他公式都可由此导出。下面我们就基于这两个公式推导一下两种还款方式的具体计算公式。 1. 等额本金还款方式 等额本金还款方式比较简单。顾名思义,这种方式下,每次还款的本金还款数是一样的。因此: 当月本金还款=总贷款数÷还款次数 当月利息=上月剩余本金×月利率 =总贷款数×(1-(还款月数-1)÷还款次数)×月利率
当月月还款额=当月本金还款+当月利息 =总贷款数×(1÷还款次数+(1-(还款月数-1)÷还款次数)×月利率) 总利息=所有利息之和 =总贷款数×月利率×(还款次数-(1+2+3+。。。+还款次数-1)÷还款次数) 其中1+2+3+…+还款次数-1是一个等差数列,其和为(1+还款次数-1)×(还款次数-1)/2=还款次数×(还款次数-1)/2 :总利息=总贷款数×月利率×(还款次数+1)÷2 由于等额本金还款每个月的本金还款额是固定的,而每月的利息是递减的,因此,等额本金还款每个月的还款额是不一样的。开始还得多,而后逐月递减。 等额本息还款方式: 等额本金还款,顾名思义就是每个月的还款额是固定的。由于还款利息是逐月减少的,因此反过来说,每月还款中的本金还款额是逐月增加的。 首先,我们先进行一番设定: 设:总贷款额=A 还款次数=B 还款月利率=C 月还款额=X 当月本金还款=Yn(n=还款月数) 先说第一个月,当月本金为全部贷款额=A,因此: 第一个月的利息=A×C 第一个月的本金还款额 Y1=X-第一个月的利息
房贷等额本息还款公式推导(详细)
等额本息还款公式推导 设贷款总额为A,银行月利率为β,总期数为m(个月),月还款额设为X,则各个月所欠银行贷款为: 第一个月A 第二个月A(1+β)-X 第三个月(A(1+β)-X)(1+β)-X=A(1+β)2-X[1+(1+β)]第四个月((A(1+β)-X)(1+β)-X)(1+β)-X =A(1+β)3-X[1+(1+β)+(1+β)2] … 由此可得第n个月后所欠银行贷款为 A(1+β)n –X[1+(1+β)+(1+β)2+…+(1+β)n-1]= A(1+β)n –X [(1+β)n-1]/β 由于还款总期数为m,也即第m月刚好还完银行所有贷款,因此有 A(1+β)m –X[(1+β)m-1]/β=0 由此求得
X = Aβ(1+β)m /[(1+β)m-1] ======================================================= ===== ◆关于A(1+β)n –X[1+(1+β)+(1+β)2+…+(1+β)n-1]= A(1+β)n –X[(1+β)n-1]/β的推导用了等比数列的求和公式 ◆1、(1+β)、(1+β)2、…、(1+β)n-1为等比数列 ◆关于等比数列的一些性质 (1)等比数列:An+1/An=q, n为自然数。 (2)通项公式:An=A1*q^(n-1); 推广式:An=Am·q^(n-m); (3)求和公式:Sn=nA1(q=1) Sn=[A1(1-q^n)]/(1-q) (4)性质: ①若m、n、p、q∈N,且m+n=p+q,则am·an=ap*aq; ②在等比数列中,依次每k项之和仍成等比数列. (5)“G是a、b的等比中项”“G^2=ab(G≠0)”. (6)在等比数列中,首项A1与公比q都不为零. ◆所以1+(1+β)+(1+β)2+…+(1+β)n-1 =[(1+β)n-1]/β 等额本金还款不同等额还款 问:等额本金还款是什么意思?与等额还款相比是否等额本金还款更省钱?
样本量计算方法
样本量及其计算依据: 根据现有文献[Gerald Holtmann,Nicholas Talley,Tobias Liebregts,Birgit Adam,Christopher Parow.A placebo-controlled trial of itopride in functional dyspepsia.The New England Journal of MEDICINE 2006;(8):832-840],功能性消化不良患者接受伊托必利50mg组治疗后,其NDI改善值的均数为18.0,本研究期望针刺本经取穴组治疗功能性消化不良的NDI改善值的均数为15.0,本研究共设了6个组别,检验水准α=0.05,检验效能1-β=0.90,采用多个样本均数比较的样本含量估计公式(王家良主编《临床流行学》.上海.上海科学技术出版社,2001.P142)进行样本量的估算,公式如下: k ψ2(Εs j2/k) n= j=1 k = Ε( X j- x ) 2/(k-l) j=1 通过公式计算,每组所需样本数n=77例,按15%的脱失率计算,每个组应不少于89例,6组应不少于534例。 样本量及其计算依据: 若分为三组或三组以上,采用多个样本均数比较的样本含量估计公式(王家良主编《临床流行学》.上海.上海科学技术出版社,2001.P142)进行样本量的估算,公式如下: k ψ2(Εs j2/k) n=
k = Ε(?X j- x ) 2/(k-l) k为研究所用的组数,?X j, s i各为每组的均数与标准差的估计值,x=Ε?X j/k,ψ为界值,可通过查阅ψ值表得到。
样本量计算(DOC)
1.估计样本量的决定因素 1.1 资料性质 计量资料如果设计均衡,误差控制得好,样本可以小于30例; 计数资料即使误差控制严格,设计均衡, 样本需要大一些,需要30-100例。 1.2 研究事件的发生率 研究事件预期结局出现的结局(疾病或死亡),疾病发生率越高,所需的样本量越小,反之就要越大。 1.3 研究因素的有效率 有效率越高,即实验组和对照组比较数值差异越大,样本量就可以越小,小样本就可以达到统计学的显著性,反之就要越大。 1.4 显著性水平 即假设检验第一类(α)错误出现的概率。为假阳性错误出现的概率。α越小,所需的样本量越大,反之就要越小。α水平由研究者具情决定,通常α取0.05或0.01。 1.5 检验效能 检验效能又称把握度,为1-β,即假设检验第二类错误出现的概率,为假阴性错误出现的概率。即在特定的α水准下,若总体参数之间确实存在着差别,此时该次实验能发现此差别的概率。检验效能即避免假阴性的能力,β越小,检验效能越高,所需的样本量越大,反之就要越小。β水平由研究者具情决定,通常取β为0.2,0.1或0.05。即1-β=0.8,0.1或0.95,也就是说把握度为80%,90%或95%。 1.6 容许的误差(δ) 如果调查均数时,则先确定样本的均数( )和总体均数(m)之间最大的误差为多少。容许误差越小,需要样本量越大。一般取总体均数(1-α)可信限的一半。 1.7 总体标准差(s) 一般因未知而用样本标准差s代替。 1.8 双侧检验与单侧检验 采用统计学检验时,当研究结果高于和低于效应指标的界限均有意义时,应该选择双侧检验,所需样本量就大; 当研究结果仅高于或低于效应指标的界限有意义
等额本息法及等额本金法两种计算公式.doc
精品文档 等本息法和等本金法的两种算公式 一: 按等额本金还款 法:贷款额为: a, 月利率为: i , 年利率为: I , 还款月数: n, an 第 n 个月贷款剩余本金: a1=a, a2=a-a/n, a3=a-2*a/n ...次类推 还款利息总和为Y 每月应还本金: a/n 每月应还利息: an*i 每期还款 a/n +an*i 支付利息 Y=( n+1)*a*i/2 还款总额 =( n+1)*a*i/2+a 等本金法的算等本金(减法):算公式: 每月本金=款÷期数 第一个月的月供 =每月本金+款×月利率 第二个月的月供 =每月本金+(款-已本金)×月利率 申10 万 10 年个人住房商性款,算每月的月供款?(月利率: 4.7925 ‰)算果: 每月本金: 100000÷120= 833 元 第一个月的月供:833+ 100000×4.7925 ‰=1312.3 元 第二个月的月供:833+( 100000- 833)×4.7925 ‰= 1308.3 元 如此推?? 二 : 按等本息款法:款 a,月利率 i ,年利率 I ,款月数n,每月款 b,款利息和 Y 1: I =12×i 2: Y=n×b- a 3:第一月款利息:a×i 第二月款利息:〔a-( b- a×i )〕×i =( a×i -b)×( 1+ i ) ^1 +b 第三月款利息:{ a-( b- a×i )-〔 b-( a×i - b)×( 1+ i ) ^1 -b〕}×i =( a×i -b)×( 1+i ) ^2 + b 第四月款利息:=( a×i - b)×( 1+ i ) ^3 + b 第 n 月款利息:=(a×i - b)×( 1+ i ) ^( n- 1)+ b 求以上和:Y=( a×i -b)×〔( 1+ i ) ^n- 1〕÷i + n×b 4:以上两Y 相等求得 月均款 :b = a×i ×( 1+ i ) ^n ÷〔( 1+ i )^n - 1〕 支付利息 :Y = n×a×i ×( 1+i ) ^n ÷〔( 1+ i ) ^n - 1〕- a 款 :n ×a×i ×( 1+ i )^n ÷〔( 1+ i ) ^n- 1〕 注:a^b 表示 a 的 b 次方。 等本息法的算 ----- 例如下: 如款 21 万, 20 年,月利率 3.465 ‰按照上 面的等本息公式算 月均款 :b = a×i ×( 1+ i ) ^n ÷〔( 1+ i )^n - 1〕即: =1290.11017 即每个月款1290 元。 。 1欢迎下载
t检验计算公式
t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ -= 。 如果样本是属于大样本(n >30)也可写成: X t μ -= 。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数; X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.63X t μ --= = = 第三步 判断 因为,以0.05为显著性水平,119df n =-=,查t 值表,临界值 0.05(19)2.093t = ,而样本离差的t = 1.63小与临界值 2.093。所以,接受原假设, 即进步不显著。
2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过0r =。 相关样本的t 检验公式为: t = 在这里,1X ,2X 分别为两样本平均数; 1 2 X σ,2 2X σ分别为两样本方差; γ为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为79.5和72分,标准差分别为9.124,9.940。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设0H ∶1μ=2μ 第二步 计算t 值 X X t -= =3.459。 第三步 判断 根据自由度19df n =-=,查t 值表0.05(9) 2.262t =,0.01(9) 3.250t =。由于实际计算出来的t =3.495>3.250=0.01(9)t ,则0.01P <,故拒绝原假设。 结论为:两次测验成绩有及其显著地差异。 由以上可以看出,对平均数差异显著性检验比较复杂,究竟使用Z 检验还是使用t 检验必须根据具体情况而定,为了便于掌握各种情况下的Z 检验或t 检验,
样本量计算
样本量计算 调查研究中样本量的确定 在社会科学研究中,研究者常常会遇到这样得问题:“要掌握总体(population)情况,到底需要多少样本量(sample)?”,或者说“我要求调查精度达到95%,需要多少样本量?”。对此,我往往感到难以回答,因为要解决这个问题,需要考虑的因素是多方面的:研究的对象,研究的主要目的,抽样方法,调查经费…。本文将根据自己的经验,探讨在调查研究中确定调查所需样本量的一些基本方法,相信这些方法对于其他的社会调查研究也有一定的借鉴意义。 确定样本量的基本公式 在简单随机抽样的条件下,我们在统计教材中可以很容易找到确定调查样本量的公式: Z2 S2 n = ------------ (1) d2 其中: n代表所需要样本量 Z:置信水平的Z统计量,如95%置信水平的Z统计量为1.96,99%的Z为2.68。 S:总体的标准差; d :置信区间的1/2,在实际应用中就是容许误差,或者调查误差。 对于比例型变量,确定样本量的公式为: Z2 ( p ( 1-p)) n = ----------------- (2) d2 其中: n :所需样本量 z:置信水平的z统计量,如95%置信水平的Z统计量为1.96,99%的为2.68
p:目标总体的比例期望值 d:置信区间的半宽 关于调查精度 通常我们所说的调查精度可能有两种表述方法:绝对误差数与相对误差数。如对某市的居民进行收入调查,要求调查的人均收入误差上下不超过50元,这是绝对数表示法,这个绝对误差也就是公式(1)中置信区间半宽d。 而相对误差则是绝对误差与样本平均值的比值。例如我们可能要求调查收入与真实情况的误差不超过1%。假定调查城市的真实人均收入为10000元,则相对误差的绝对数是100元。 公式的应用方法 对于公式的应用,一些参数是我们可以事先确定的:Z值取决于置信水平,通常我们可以考虑95%的置信水平,那么Z=1.96;或者99%,Z=2.68。然后可以确定容许误差d(或者说精度),即我们可以根据实际情况指定置信区间的半宽度d。因此,公式应用的关键是如何确定总体的标准差S。如果我们可以估计出总体的方差(标准差),那么我们可以根据公式计算出样本量: 例如:要了解该城市的居民收入,假定我们知道该市居民收入的标准差为1500,要求的调查误差不超过100元,则在95%的置信水平下,所需的样本量为 n=1.962*15002/1002=8,643,600/10,000=864 即需要调查的样本量为864个。 最大样本量 以上公式只是理论上的,在实际调查中确定合理的样本量,必须考虑多方面的因素。 首先,由于人们通常缺乏对标准差的感性认识,因此对标准差的估计往往是最难的。总体的标准差是123,还是765?如果没有一点对样本的先验知识,那么对标准差的估计是不可能的。好在我们通常能对变量的平均值进行估计,如我们通过历史资料估计该地区目前的年人均收入大致为10,000元,那么根据统计学知识,我们引入变异系数的概念: 变异系数V=标准差S/平均值X<= 1 因此,我们知道人均收入的标准差应该小于平均值,就是说标准差应该在10000以下。当然,这对于我们确定样本量还不能起太大的作用。然而如果我们采用相对误差表述的精度,对公
视频存储容量的计算
视频存储总容量的计算 视频存储容量的计算公式如下: 容量=码流/8 X视频路数X监控天数X 24小时X 3600秒 注:码流是以Mbps或Kbps为单位,码流除以8是把码流从bit转换为byte,结果相应的是MB或KB 按计算公式,以一个中小规模的例子计算: 500路监控路数,2Mbps D1格式,数据存储30天,需要的存储容量: 2Mbps/8 X 500 路X 30 天X 24 小时X 3600 秒/1024/1024 ?300TB 存储空间单位换算:1TB = 1024GB = 1024 X 1024MB = 1024 X 1024 X 1024KB = 1,073,741,824Byte 硬盘容量单位换算:1TB = 1000GB = 1000 X 1000MB = 1000 X 1000 X 1000KB = 1,000,000,000Byte
基本的算法是: 【码率】(kbps )=【文件大小(字节)】X8/【时间(秒)】/1024 码流(Data Rate )是指视频文件在单位时间内使用的数据流量,也叫码率,是 他是视频编码中画面质量控制中最重要的部分。 同样分辨率下,视频文件的码流 越大,压缩比就越小,画面质量就越高。 所以应该是一样的,只是称谓不同 分薪率耒示静的尺寸犬小(或廉素埶重)I 用于设養录蟻的囹禄尺寸?正 如前面所谬 在监^申常用的曲粹有QOF 、CIFs HD1s 2CF ,DCIF. 4CIF 和D1.720P. 1060P?几和 分莽聿是决走傥率(码率〉的主叢因靑,不同的 分笹至要采用不同的位華,它们之问的关粟如下罔所示' P>p 計 : > 10M 图棘廉里 压翳码奉 倍输希竞(平均 Q ) 录蟻文件尺寸上瞑 兆学和 小时3&) 「 512Kbps 540Kbps ^225 352&28* 384Kbps 400Kbps <169 晋通 256KDP5 280Kbps 5112 DCF 最堺 1.2Mbps ULI&pS ^540 528*384 7C0KDPS 730Kt )DS 1333 普通 512Kbps 540 Kbps ^225 D1 2Mbps 2.2Mt )p£ iQOO 704^576 1.75Mbps 1.0Mt )ps ^?ea 普通 1.5Mbps 1.7 Mbps <675 720P 最毎 10M&D3 11Mbps 1260*720 6Mbps 6.6 Mbps ^2700 晋通 2Mbps 2.2tflt )ps £900 分赫輩、咼車、帯宽及埶榻重耐昵表《囹像師至:乃帧电审柔件下) I SIJk JGfiR LL1 1 JM
磁盘存储容量计算
存储系统计算总结 一.磁盘存储容量计算 磁盘容量有两种指标,一种是非格式化容量,指一个磁盘所能存储的总位数;另一种是格式化容量,指各扇区中数据区容量总和。 公式有: 记录密度(存储密度):一般用磁道密度和位密度来表示。 磁道密度:指沿磁盘半径方向,单位长度内磁道的条数。 (1)总磁道数=记录面数×磁道密度×(外直径-内直径)÷2 (2)非格式化容量=位密度×3.14×最内圈直径×总磁道数 (3)格式化容量=每道扇区数×扇区容量×总磁道数 (4)平均数据传输速率=最内圈直径×3.14×位密度×盘片转速 或: 非格式化容量=面数×(磁道数/面)×内圆周长×最大位密度 格式化容量=面数×(磁道数/面)×(扇区数/道)×(字节数/扇区) 例1:假设一个硬盘有3个盘片,共4个记录面,转速为7200r/min,盘面有效记录区域 的外直径为30cm ,内直径为10cm ,记录位密度为250b/mm ,磁道密度为8道/mm , 每磁道分16个扇区,每扇区512字节,试计算该磁盘的非格式化容量,格式化容量 和数据传输率。 答: 非格式化容量=最大位密度×最内圈周长×总磁道数 最内圈周长=100*3.1416=314.16mm 每记录面的磁道数=(150-50)×8=800道; 因此,每记录面的非格式化容量=314.16×250×800/8=7.5M 格式化容量=每道扇区数×扇区容量×总磁道数=16×512×800×4/1024/1024=25M 硬盘平均数据传输率公式: 平均数据传输率=每道扇区数×扇区容量×盘片转速=16×512×7200/60=960kb/s 二.数据线和地址线的计算: 的位数,这里算出来是11位;4是一个存储单元的位数,也就是数据线的位数,所以这个芯片的地址线11位,数据线4位。 三.存储容量(1字节=8位二进制信息)及换算: 例:CPU 地址总线为32根则可以寻址322=4G 的存储空间 1KB=102B=1024Byte 1MB=202B=1024KB 1GB=302B=1024MB 1TB=402B=1024GB 1PB=502B=1024TB 1EB=602B=1024PB 四.用存储器芯片构成半导体存储器(主存储器组成) 用现成的集成电路芯片构成一个一定容量的半导体存储器,大致要完成以下四项工作: 1、根据所需要的容量大小,确定所需芯片的数目 2、完成地址分配,设计片号信号译码器 3、实现总线(DBUS ,ABUS ,CBUS )连接 4、解决存储器与CPU 的速度匹配问题 下面通过一个简单例子,说明如何用现成芯片来构成一个存储器。 扇区 磁道
怎样确定统计量的样本容量
样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。
等额本息还款法
一、按揭贷款等额本息还款计算公式 1、计算公式 每月还本付息金额=[本金×月利率×(1+月利率)还款月数]/(1+月利率)还款月数-1] 其中:每月利息=剩余本金×贷款月利率 每月本金=每月月供额-每月利息 计算原则:银行从每月月供款中,先收剩余本金利息,后收本金;利息在月供款中的比例中虽剩余本金的减少而降低,本金在月供款中的比例因而升高,但月供总额保持不变。 2、商业性房贷案例 贷款本金为300000元人民币 还款期为10年(即120个月) 根据5.51%的年利率计算,月利率为4.592‰ 代入等额本金还款计算公式计算: 每月还本付息金额=[300000×4.592‰×(1+月利率)120]/[(1+月利率)120-1] 由此,可计算每月的还款额为3257.28元人民币 二、按揭贷款等额本金还款计算公式 1、计算公式 每月还本付息金额=(本金/还款月数)+(本金-累计已还本金)×月利率 每月本金=总本金/还款月数 每月利息=(本金-累计已还本金)×月利率 计算原则:每月归还的本金额始终不变,利息随剩余本金的减少而减少 2、商业性房贷案例 贷款本金为300000元人民币 还款期为10年(即120个月) 根据5.51%的年利率计算,月利率为4.592‰ 代入按月递减还款计算公式计算: (第一个月)还本付息金额=(300000/120)+ (300000-0)×4.592‰ 由此,可计算第一个月的还款额为3877.5元人民币 (第二个月) 还本付息金额=(300000/120)+ (300000-2500)×4.592‰ 由此,可计算第一个月的还款额为3866.02元人民币 (第二个月) 还本付息金额=(300000/120)+ (300000-5000)×4.592‰
样本量计算(DOC)
1. 估计样本量的决定因素 1.1 资料性质 计量资料如果设计均衡 ,误差控制得好 ,样本可以小于 30例; 计数资料即使误差控制严格,设计均衡, 样本需要大一些 ,需要30-100 例。 1.2 研究事件的发生率研究事件预期结局出现的结局(疾病或死亡),疾病发生率越高,所需的样本量越小,反之就要越大。 1.3 研究因素的有效率 有效率越高,即实验组和对照组比较数值差异越大,样本量就可以越小,小样本就可以达到统计学的显著性,反之就要越大。 1.4 显著性水平 即假设检验第一类(a)错误出现的概率。为假阳性错误出现的概率。a越小,所需的样本量越大,反之就要越小。a水平由研究者具情决定,通常a取0.05 或 0.01 。 1.5 检验效能 检验效能又称把握度,为1-B,即假设检验第二类错误出现的概率,为假阴性错误出现的概率。即在特定的a水准下,若总体参数之间确实存在着差别,此时该次实验能发现此差别的概率。检验效能即避免假阴性的能力,B越小,检验效能越高,所需的样本量越大,反之就要越小。B水平由研究者具情决定,通常取 B为0.2,0.1或0.05。即1—B =0.8,0.1或0.95,也就是说把握度为80% 90%或95%。 1.6容许的误差(S) 如果调查均数时,则先确定样本的均数()和总体均数(m)之间最大的误差为多少。容许误差越小,需要样本量越大。一般取总体均数(1— a )可信限的一半。 1.7 总体标准差(s) 一般因未知而用样本标准差 s 代替。 1.8 双侧检验与单侧检验 采用统计学检验时 ,当研究结果高于和低于效应指标的界限均有意义时 , 应该选择双侧检验 , 所需样本量就大 ; 当研究结果仅高于或低于效应指标的界限有意义
抽样调查的样本容量的确定方法
抽样调查的样本容量的确定方法 摘要:确定样本容量是抽样调查中重要的环节,影响到抽样估计的精确度和调查的成本和效益。单位标志变异程度、抽样极限误差、抽样推断的可靠度、抽样类型和方法等影响到样本容量地确定。样本容量的确定可以根据由抽样误差、抽样极限误差和概率度推算出来的公式计算,也可以根据建立在过去抽取满足统计方法要求的样本量所累积下来的经验法则来确定。 关键词:样本容量;抽样调查;抽样误差;极限误差 抽样调查是根据随机原则,从总体中抽取部分实际数据构成样本,同时运用概率估计方法,依据样本信息推断总体数量特征的一种非全面统计调查。根据抽选样本的方法,抽样调查可以分为等概率抽样和非概率抽样两类。等概率抽样又称为随机抽样,是按照概率论和数理统计的原理,从调查研究的总体中,根据随机原则来抽选样本,并从数量上对总体的某些特征做出估计推断,对推断出可能出现的误差可以从概率意义上加以控制。样本是从总体中抽出的部分单位的集合,样本中所包含的单位数被称为样本容量,一般用n表示。确定样本容量是制定抽样调查方案中的一个非常重要的环节。 1.确定样本容量的必要性 1.1样本容量大小影响抽样估计的精确度 抽样估计的精确度是指样本的统计量与其所代表的总体值的接近程度。调查结果相对于总体真实值的精确度与样本容量直接相关。样本容量越大,抽样误差相对就会减少,估计精度就会提高;若样本容量太小,抽样误差就会增大,从而影响抽样估计的精确度。 1.2样本容量大小影响抽样调查的成本和效益 样本量的设计通常受到研究经费及调查时间的限制。根据数理统计规律,样本量增加呈直线递增的情况下(样本量增加一倍,成本也增加一倍),而抽样误差只是样本量相对增长速度的平方根递减。若样本容量过大,调查单位增多,不仅增加人力、财力和物力的耗费,增加调查费用,而且还影响到抽样调查的时效性,从而不能充分发挥抽样调查的优越性。 因此,为节省调查费用,体现出抽样调查的优越性,在确定样本容量时,应在满足抽样调查对估计数据的精确度的前提下,尽量减少调查单位数,确保必要的抽样数目。 2.影响必要样本容量的主要因素 影响样本容量的因素是多方面的,在抽样调查总体、调查费用和调查时间既定的情况下,为确定最佳的样本容量,应首先分析影响样本容量的因素。从理论上说,影响样本容量的因素有以下几个方面: 2.1单位标志变异程度 或成数方差P(1-P)的大小来表示。在其他单位标志变异程度一般用方差2
磁盘存储容量计算
磁盘存储容量计算 Revised by Petrel at 2021
存储系统计算总结 一.磁盘存储容量计算 磁盘容量有两种指标,一种是非格式化容量,指一个磁盘所能存储的总位数;另一种是格式化容量,指各扇区中数据区容量总和。 公式有: 记录密度(存储密度):一般用磁道密度和位密度来表示。 磁道密度:指沿磁盘半径方向,单位长度内磁道的条数。 (1)总磁道数=记录面数×磁道密度×(外直径-内直径)÷2 (2)非格式化容量=位密度×3.14×最内圈直径×总磁道数 (3)格式化容量=每道扇区数×扇区容量×总磁道数 (4)平均数据传输速率=最内圈直径×3.14×位密度×盘片转速 或: 非格式化容量=面数×(磁道数/面)×内圆周长×最大位密度 格式化容量=面数×(磁道数/面)×(扇区数/道)×(字节数/扇区) 例1:假设一个硬盘有3个盘片,共4个记录面,转速为7200r/min,盘面有效记录区域的外直径为30cm ,内直径为10cm ,记录位密度为250b/mm ,磁道密度为8道/mm ,每磁道分16个扇区,每扇区512字节,试计算该磁盘的非格式化容量,格式化容量和数据传输率。 答: 非格式化容量=最大位密度×最内圈周长×总磁道数 扇区 磁道
最内圈周长=100*3.1416=314.16mm 每记录面的磁道数=(150-50)×8=800道; 因此,每记录面的非格式化容量=314.16×250×800/8=7.5M 格式化容量=每道扇区数×扇区容量×总磁道数=16×512×800×4/1024/1024=25M 硬盘平均数据传输率公式: 平均数据传输率=每道扇区数×扇区容量×盘片转速=16×512×7200/60=960kb/s 二.数据线和地址线的计算: 例:如果是2K*4的芯片,2K是容量,由地址线决定,计算方法:2n=容量,n 就是地址线的位数,这里算出来是11位;4是一个存储单元的位数,也就是数据线的位数,所以这个芯片的地址线11位,数据线4位。 三.存储容量(1字节=8位二进制信息)及换算: 2=4G的存储空间 例:CPU地址总线为32根则可以寻址32 1KB=102B=1024Byte1MB=20 2B=1024KB 1GB=30 2B=1024GB 2B=1024MB1TB=40 1PB=50 2B=1024TB1EB=60 2B=1024PB 四.用存储器芯片构成半导体存储器(主存储器组成) 用现成的集成电路芯片构成一个一定容量的半导体存储器,大致要完成以下四项工作: 1、根据所需要的容量大小,确定所需芯片的数目 2、完成地址分配,设计片号信号译码器 3、实现总线(DBUS,ABUS,CBUS)连接 4、解决存储器与CPU的速度匹配问题 下面通过一个简单例子,说明如何用现成芯片来构成一个存储器。 五.主存储器的地址编码:
-临床试验样本量的估算
临床试验样本量的估算 样本量的估计涉及诸多参数的确定,最难得到的就是预期的或者已知的效应大小(计数资料的率差、计量资料的均数差值),方差(计量资料)或合并的率(计数资料各组的合并率),一般需通过预试验或者查阅历史资料和文献获得,不过很多时候很难得到或者可靠性较差。因此样本量估计有些时候不是想做就能做的。SFDA的规定主要是从安全性的角度出发,保证能发现多少的不良反应率;统计的计算主要是从power出发,保证有多少把握能做出显著来。 但是中国的国情?有多少厂家愿意多做? 建议方案里这么写: 从安全性角度出发,按照SFDA××规定,完成100对有效病例,再考虑到脱落原因,再扩大20%,即120对,240例。 或者:本研究为随机双盲、安慰剂平行对照试验,只有显示试验药优于安慰剂时才可认为试验药有效,根据预试验结果,试验组和对照组的有效率分别为65.0%和42.9%,则每个治疗组中能接受评价的病人样本数必须达到114例(总共228例),这样才能在单侧显著性水平为5%、检验功效为90%的情况下证明试验组疗效优于对照组。假设因调整意向性治疗人群而丢失病例达10%,则需要纳入病人的总样本例数为250例。 非劣性试验(α=0.05,β=0.2)时:
计数资料: 平均有效率(P)等效标准(δ) N= 公式:N=12.365×P(1-P)/δ2 计量资料: 共同标准差(S)等效标准(δ) N= 公式:N=12.365× (S/δ)2 等效性试验(α=0.05,β=0.2)时: 计数资料: 平均有效率(P)等效标准(δ) N= 公式:N=17.127×P(1-P)/δ2 计量资料: 共同标准差(S)等效标准(δ) N= 公式:N=17.127× (S/δ)2 上述公式的说明: 1) 该公式源于郑青山教授发表的文献。 2) N 是每组的估算例数N1=N2,N1 和N2 分别为试验药和参比药的例数; 3) P 是平均有效率,
样本量的确定方法.
如对你有帮助,请购买下载打赏,谢谢!样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。
视频监控存储空间计算方法
视频监控存储空间计算方法在视频监控系统中,对存储空间容量的大小需求是与画面质量的高低、及视频线路等都有很大关系。下面对视频存储空间大小与传输带宽的之间的计算方法做以介绍。 比特率是指每秒传送的比特(bit)数。单位为bps(BitPerSecond),比特率越高,传送的数据越大。比特率表示经过编码(压缩)后的音、视频数据每秒钟需要用多少个比特来表示,而比特就是二进制里面最小的单位,要么是0,要么是1。比特率与音、视频压缩的关系,简单的说就是比特率越高,音、视频的质量就越好,但编码后的文件就越大;如果比特率越少则情况刚好相反。 码流(DataRate)是指视频文件在单位时间内使用的数据流量,也叫码率,是视频编码中画面质量控制中最重要的部分。同样分辨率下,视频文件的码流越大,压缩比就越小,画面质量就越高。 上行带宽就是本地上传信息到网络上的带宽。上行速率是指用户电脑向网络发送信息时的数据传输速率,比如用FTP上传文件到网上去,影响上传速度的就是“上行速率”。 下行带宽就是从网络上下载信息的带宽。下行速率是指用户电脑从网络下载信息时的数据传输速率,比如从FTP服务器上文件下载到用户电脑,影响下传速度的就是“下行速率”。 不同的格式的比特率和码流的大小定义表: 传输带宽计算: 比特率大小×摄像机的路数=网络带宽至少大小; 注:监控点的带宽是要求上行的最小限度带宽(监控点将视频信息上传到监控中心);监控中心的带宽是要求下行的最小限度带宽(将监控点的视频信息下载 到监控中心);例:电信2Mbps的ADSL宽带,理论上其上行带宽是 512kbps=64kb/s,其下行带宽是2Mbps=256kb/s 例:监控分布在5个不同的地方,各地方的摄像机的路数:n=10(20路)1 个监控中心,远程监看及存储视频信息,存储时间为30天。不同视频格式的带宽及存储空间大小计算如下: 地方监控点: CIF视频格式每路摄像头的比特率为512Kbps,即每路摄像头所需的数据传输带宽为512Kbps,10路摄像机所需的数据传输带宽为: 512Kbps(视频格式的比特率)×10(摄像机的路数)≈5120Kbps=5Mbps(上行 带宽) 即:采用CIF视频格式各地方监控所需的网络上行带宽至少为5Mbps; D1视频格式每路摄像头的比特率为1.5Mbps,即每路摄像头所需的数据传输带宽为1.5Mbps,10路摄像机所需的数据传输带宽为: 1.5Mbps(视频格式的比特率)×10(摄像机的路数)=15Mbps(上行带宽) 即:采用D1视频格式各地方监控所需的网络上行带宽至少为15Mbps; 720P(100万像素)的视频格式每路摄像头的比特率为2Mbps,即每路摄像头所需的数据传输带宽为2Mbps,10路摄像机所需的数据传输带宽为:2Mbps(视频格式的比特率)×10(摄像机的路数)=20Mbps(上行带宽) 即:采用720P的视频格式各地方监控所需的网络上行带宽至少为20Mbps;