Metallicity and mean age across M33

a r X i v :0709.2949v 1 [a s t r o -p h ] 19 S e p 2007
2Cioni,Irwin,Ferguson et al.
numerous intermediate-age stars in the central7.6′of the galaxy down to K~17?18.Several years later([10])reaching K~22detected young, intermediate-age and old stars in the central22′′.Wide-?eld relatively shal-low observations(K s~16)by[2]claimed the existence of arcs of metal poor C stars in the outer parts of M33.
2Observations,analysis&results
New NIR observations of M33have been obtained from UKIRT as part of a programme to survey luminous red stars in LG galaxies(PI Irwin).UKIRT data combine wide-?eld and good sensitivity improving considerably on former studies.A mosaic of4WFCAM tiles covering~3deg2was observed with an average seeing of1.07′′±0.06′′.This allowed to reach sources as faint as K s=18.32with S/N=10including most intermediate-age AGB stars.The data was dereddened assuming E(B?V)=0.07and using the[5]reddening law such that the absorption in each wave band is A J=0.06,A H=0.04and
A K
s=0.02.
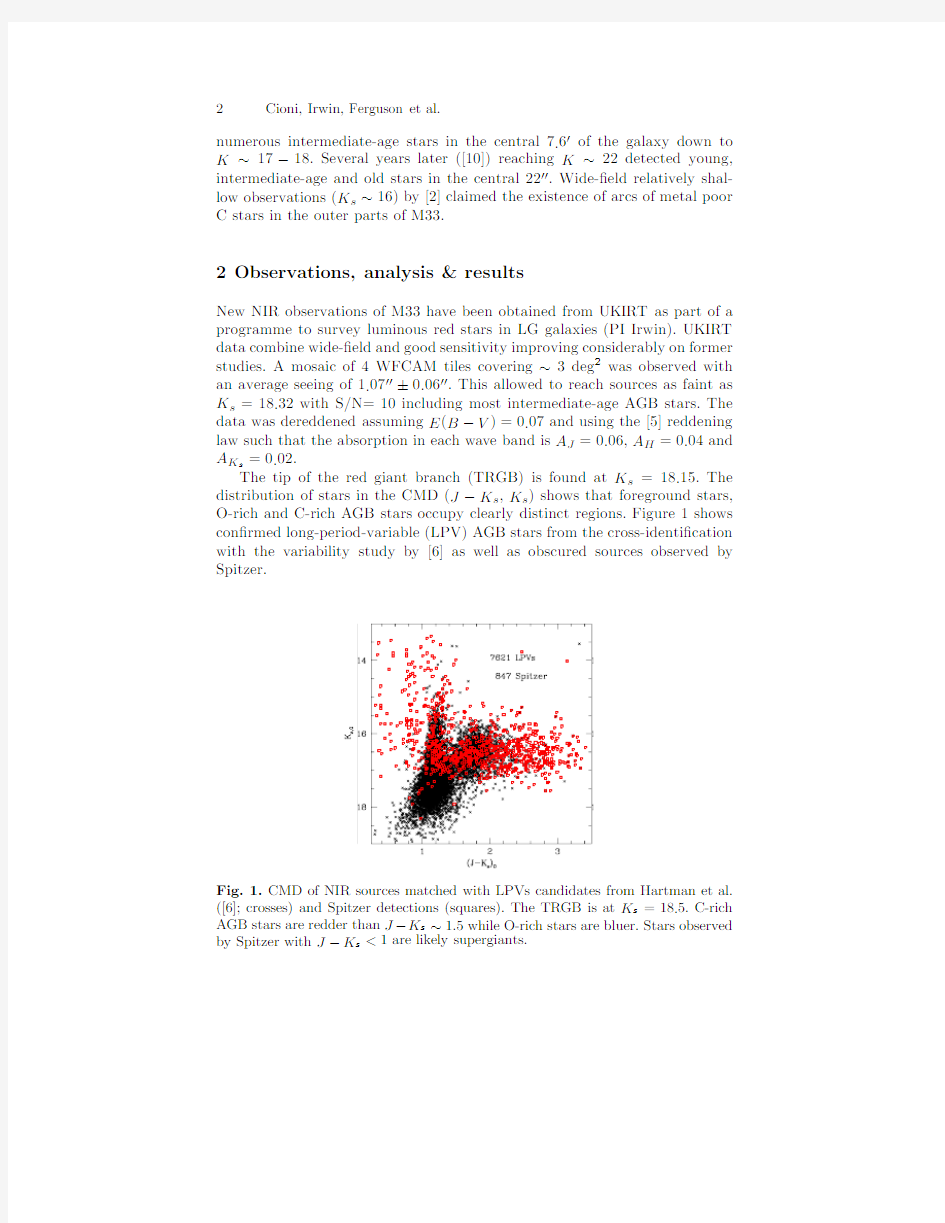
The tip of the red giant branch(TRGB)is found at K s=18.15.The distribution of stars in the CMD(J?K s,K s)shows that foreground stars, O-rich and C-rich AGB stars occupy clearly distinct regions.Figure1shows con?rmed long-period-variable(LPV)AGB stars from the cross-identi?cation with the variability study by[6]as well as obscured sources observed by Spitzer.
Fig.1.CMD of NIR sources matched with LPVs candidates from Hartman et al. ([6];crosses)and Spitzer detections(squares).The TRGB is at K s=18.5.C-rich AGB stars are redder than J?K s~1.5while O-rich stars are bluer.Stars observed by Spitzer with J?K s<1are likely supergiants.
Metallicity and mean age across M333 The spatial distribution of supergiant stars is clumpy and extends asym-metrically to the NE while AGB stars trace a smoother distribution with hints of the major galaxy spiral arms.The ratio between C-and O-rich AGB stars(the C/M ratio)also outlines a ring-like feature and suggests a metallic-ity spread of[Fe/H]=0.6dex across the galaxy,using the[1]calibration,in agreement with the results by[9].
2.1Structure&Extinction
By subdividing the galaxy disk into4concentric ellipses and8sectors we in-vestigated the orientation as well as the contribution by di?erential extinction within the galaxy,if any.The peak of the magnitude and colour di?erences from the mean,for C stars,describe a sinusoidal pattern which indicates that stars in the NW of the galaxy are fainter than stars in the SE of it.This sinusoid is consistent with the distance moduli distribution derived by[7]in 10di?erent regions scattered within M33suggesting that it is almost entirely
a structure rather then an extinction e?ect.
2.2Mean age and metallicity
The K s magnitude distribution of stars within each sector of each ellipse has been?tted with theoretical distributions spanning a range of mean ages (2?10.6Gyr)and mean metallicities(Z=0.0005?0.016).The theoretical models used to create the distributions are those by[4].This method was ?rst used by[3]to investigate the stellar population of the Large Magellanic Cloud.
Maps of the best?t mean metallicity versus mean age and combined maps of best?t mean age and metallicity have been created separately for C-rich and O-rich AGB stars.These show an inhomogeneous distribution of age and metallicity.Note that relative values are much more signi?cant than absolute values which can be model dependent.
The very central region of the galaxy or regions around it appear metal rich compared to the overall disk.In particular,C stars trace a disk/halo population which is metal poor([Fe/H]≤?1.6dex)while the nucleus and other regions around it are as metal rich as[Fe/H]~?1.2dex.There is an outer thick ring of stars on average6Gyr old or older.O-rich AGB stars also suggest an old(6?8.5Gyr)and metal poor([Fe/H]≤0.5dex)outer ring while the centre of the galaxy is as young(1?5Gyr)and metal rich([Fe/H]≥0.3 dex).Although trends are the same for both C-rich and O-rich AGB stars, the latter show higher metallicity values but very similar ages.
3Conclusions&Future studies
The K s method is an e?cient way to constraint the parameters of a galaxy stellar population using bright IR targets like AGB stars.The existence of a
4Cioni,Irwin,Ferguson et al.
Fig.2.Spatial distribution of the mean age of the stellar population of M33(top), of the metallicity(middle)and of the statistical probability that expresses the con?-dence level of the previous distributions.These distributions have been constructed from the comparison between the observed K s magnitude distribution of C-rich(top) and O-rich(bottom)AGB stars selected from the CMD.Darker regions correspond to higher numbers.North is up and East is left.
metallicity and age gradient throughout M33is con?rmed.The C/M ratio, mean age and metallicity show much more structure/substructures.The SE of the galaxy is closer to us;the position angle of bright/faint stars is in the direction of the galaxy warp.Many of the detected AGB stars are LPVs.
More galaxies have been observed within the same programme and will be soon analysed.Theoretical models are already good enough to?t entirely CMDs instead of just magnitude distributions.The study of galaxies well beyond the LG has to wait next generation facilities like JWST and E-ELT. References
1.P.Battinelli,S.Demers,A&A434,657(2005)
2. D.L.Block,K.C.Freeman,T.H.Jarret,et al.A&A425,L437(2004)
3.M.-R.L.Cioni,L.Girardi,P.Marigo,H.J.Habing,A&A,448,77(2006a)
4.L.Girardi,A.Bressan,G.Bertelli,C.Chiosi,A&AS,141,371(2000)
5.I.Glass,M.Schultheis,MNRAS345,39(2003)
6.J.D.Hartman,D.Bersier,K.Z.Stanek,et al.,MNRAS371,1405(2006)
7.M.Kim,E.Kim,M.G.Lee,et al.,AJ123,244(2002)
8.I.S.McLean,T.Liu,ApJ456,499(1996)
9.J.F.Rowe,H.B.Richer,J.P.Brewer,et al.,AJ129,729(2005)
10. A.W.Stephens,J.A.Frogel,AJ124,2023(2002)
11.S.van den Berg;The Galaxies of the Local Group,Cambridge Astrophysics
Series35
stata语法解释
Tab1-4 一、tabstat fpm fpm_hat , by(pop_cat) stat(mean count) format(%9.2f) 1、命令tabstat --汇总统计表(主要用于描述性统计) 2、语法:tabstat varlist [if] [in] [weight] [, options] 3、fpm fpm_hat:这两个是输出组;by(pop_cat):变量组; stat(mean count):stat()展示统计结果,mean count 非遗漏观测计数的平均 值;format(%9.2f):设置变量的输出格式(%9.2f:字符串数据格式) Tab5-6 一、xi: reg fpm fpm_hat pop pop_2 pop_3 i.term i.regions,r cluster(id_city) 1、命令regress--线性回归(简单线性回归)xi: reg生成虚拟变量回归 2、语法:regress depvar [indepvars] [if] [in] [weight] [, options] 3、depvar为被解释变量:fpm; indepvars为解释变量:pm_hat pop pop_2 pop_3 i.term i.regions 二、foreach与forevalue区别: 对foreach的几种具体形式进行讲解。 —①foreachlnamein anylist{ —该种形式允许一般形式的列表(list),列表中的各个元素用空格分开。 —例如, —foreach x in mpg weight-turn { —summarize `x' —} —这时,循环会执行两次,即令局部宏x依次为mpg和weight-turn,来计算其描述统计量。— —②foreachlnameof local lmacname { —或 foreachlnameof global gmacname { —这里,第一种是对局部宏lmacname中的各项进行循环,第二种是对全局宏gmacname中的各项进行循环。因为很多时候,我们事先并不知道具体的要循环的元素,而是将这些元素存储在宏中,所以这种形式很常见。此外,在所有的循环方式中,这两种方式的执行速度最快。 —③foreachlnameof varlistvarlist{ —这里,of和第一个varlist是命令格式的一部分,第二个varlist是具体的变量列表。该种形式表示我们按照变量的方式来对第二个varlist进行解读。例如,我们输入下面的语句:—foreachx of varlistmpg weight-turn { —summarize `x' —} —这里,循环会执行四次,依次对mpg、weight、length和turn进行。这里,weight-turn表示从weight到turn的变量,对于“usaauto.dta”的数据,即包括变量weight、length和turn。— —④foreachlnameof newlistnewvarlist{ —这里,foreach…of newlist…是命令格式的一部分,lname是局部宏的名称,newvarlist是新变量列表。Stata会检查指定的新变量名是否有效,但Stata并不自动将其生成。例如,我们
传统meanshift跟踪算法流程
传统meanshift 跟踪算法实现流程 一、 Meanshift 算法流程图 视频流 手动选定跟踪目标 提取目标灰度加权直方图特征hist1 提取候选目 标区域 提取候选目标的灰度加权直方图特征hist2 均值漂移得到均值漂移向量及新的候选区域位 置 是否满足迭代结束条件 第二帧之后图像 第一帧图像 得到当前帧目标位置 是 否 图1 meanshift 流程图 二、 各模块概述 1、 手动选定目标区域:手动框出目标区域,并把该区域提取出来作为目标模板 区域; 2、 提取目标灰度加权直方图特征hist1; 2.1构造距离权值矩阵m_wei ; 使用Epanechnikov 核函数构造距离加权直方图矩阵:设目标区域中像素
点(,)i j 到该区域中心的距离为dist ,则 _(,)1/m wei i j dist h =-,这里h 是核函数窗宽,h 为目标区域中离区域中心 最远的像素点到中心的距离:若所选目标区域为矩形区域,区域的半宽度为 x h ,半高度为y h ,则22()x y h sqrt h h =+; 2.2得到归一化系数C ; 1/C M =,其中M 是m_wei 中所有元素值之和; 2.3计算目标的加权直方图特征向量hist1; 若图像为彩色图像,则把图像的,,r g b 分量归一化到[0,15]之间(分量值与16取余,余数即为归化后的分量值),然后为不同的分量值赋予不同的权值得到每个像素点的特征值_q temp : _256*16*q t e m p r g b = ++ 对于像素点(,)i j ,设其特征值为_q temp ,则另 1(_1)1(_1)_(,)hist q temp hist q temp m wei i j +=++; 若图像是灰度图像,则直接利用每个像素的灰度值作为每个像素的特征值,然后统计得到hist1; 把一维数组hist1归一化:11*hist hist C =;归一化后的数组hist1即为目标的加权直方图特征向量; 3、 从第二帧开始的图像,通过迭代的方式找到该帧图像中目标的位置; 3.1提取候选目标区域:以上一帧图像中目标的位置或上一次迭代得到的目标位置为中心提取出目标模板区域大小的区域; 3.2提取候选目标区域的加权直方图特征向量hist2:提取方法同步骤2.3; 计算候选目标区域的特征值矩阵_1q temp : _1 (,)256*(,) 16*(,)q t e m p i j r i j g i j b i j =++; 3.3均值漂移到新的目标区域; 3.3.1计算候选目标区域相对于目标区域的均值漂移权值w : ( 1()/2()),2(2w s q r t h i s t i h i s t i h i s t =≠ 2() 0h i s t i =时,()0;w i = 3.3.2 根据每个像素点所占的均值漂移权值计算漂移矩阵xw : 11(_1(,)1)*[(1),(2)]a b i j xw xw w q temp i j i y j y ===++--∑∑ 3.3.2得到权值归一化后的均值漂移向量Y :
mean 的14种用法解释
mean 的14种用法解释 vt. 意味;想要;意欲 过去式 meant 过去分词 meant 现在分词 meaning ] 1、mean vt. 表示…的意思;意思是; If you can bear with me a little longer, you will see what I mean. 如果你能再容忍我一会儿,你就会明白我的意思了。Don't juggle with words any more. I know what you mean. 不要再玩文字游戏了,我知道你是什么意思。 She never meant anything of the sort.她决没有那种意思。What does this word mean?这个词是什么意思? So what does this all mean? 那么这都意味着什么呢? I mean, what is this? 我的意思是这是什么? They do not know what the words mean. 他们不知道这些字的意思是什么。 Yeah I see what you mean. 是的,我明白你的意思。 I mean I like both of the companies. 我的意思是这两家公司我都喜欢。
I mean this one, not that one.我指的是这个, 不是那个。 I mean business.我是当真的。 He means this house for his daughter.他预定把这栋房子给女儿。 2、意味着;即是: Money means nothing to her.她视金钱如粪土。 Health means everything.健康就是一切。 The dark clouds mean rain.乌云意味着要下雨。 His promotion means a raise in salary.他的提升意味着要增加薪水。 What does all this mean to you? 这一切对你意味着什么? 3、意指;意谓: What do / did you mean by...?该句型的意思是“你(做…)……是什么意思?” Whom did she mean by them? 她说的“他们”是指谁? What does he mean by cancelling his performance?他取消演出是什么意思? What do you mean by acting like this? 你这样做是什么意思? What do you mean by saying that?你那样说是什么意思? What does that word mean? (=What is meant by that word?)那个词作什么解释?
mean-shift算法概述
Mean Shift 概述 Mean Shift 简介 Mean Shift 这个概念最早是由Fukunaga 等人[1]于1975年在一篇关于概率密度梯度函数的估计中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift 是一个名词,它指代的是一个向量,但随着Mean Shift 理论的发展,Mean Shift 的含义也发生了变化,如果我们说Mean Shift 算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束. 然而在以后的很长一段时间内Mean Shift 并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift 的重要文献[2]才发表.在这篇重要的文献中,Yizong Cheng 对基本的Mean Shift 算法在以下两个方面做了推广,首先Yizong Cheng 定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng 还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift 的适用范围.另外Yizong Cheng 指出了Mean Shift 可能应用的领域,并给出了具体的例子. Comaniciu 等人[3][4]把Mean Shift 成功的运用的特征空间的分析,在图像平滑和图像分割中Mean Shift 都得到了很好的应用. Comaniciu 等在文章中证明了,Mean Shift 算法在满足一定条件下,一定可以收敛到最近的一个概率密度函数的稳态点,因此Mean Shift 算法可以用来检测概率密度函数中存在的模态. Comaniciu 等人[5]还把非刚体的跟踪问题近似为一个Mean Shift 最优化问题,使得跟踪可以实时的进行. 在后面的几节,本文将详细的说明Mean Shift 的基本思想及其扩展,其背后的物理含义,以及算法步骤,并给出理论证明.最后本文还将给出Mean Shift 在聚类,图像平滑,图像分割,物体实时跟踪这几个方面的具体应用. Mean Shift 的基本思想及其扩展 基本Mean Shift 给定d 维空间d R 中的n 个样本点i x ,i=1,…,n,在x 点的Mean Shift 向量的基本形式定义为: ()()1 i h h i x S M x x x k ∈≡ -∑ (1) 其中,h S 是一个半径为h 的高维球区域,满足以下关系的y 点的集合,
基于meanshift的目标跟踪算法——完整版
基于Mean Shift的目标跟踪算法研究 指导教师:
摘要:该文把Itti视觉注意力模型融入到Mean Shift跟踪方法,提出了一种基于视觉显著图的Mean Shift跟踪方法。首先利用Itti视觉注意力模型,提取多种特征,得到显著图,在此基础上建立目标模型的直方图,然后运用Mean Shift方法进行跟踪。实验证明,该方法可适用于复杂背景目标的跟踪,跟踪结果稳定。 关键词:显著图目标跟踪Mean Shift Mean Shift Tracking Based on Saliency Map Abstract:In this paper, an improved Mean Shift tracking algorithm based on saliency map is proposed. Firstly, Itti visual attention model is used to extract multiple features, then to generate a saliency map,The histogram of the target based on the saliency map, can have a better description of objectives, and then use Mean Shift algorithm to tracking. Experimental results show that improved Mean Shift algorithm is able to be applied in complex background to tracking target and tracking results are stability. 1 引言 Mean Shift方法采用核概率密度来描述目标的特征,然后利用Mean Shift搜寻目标位置。这种方法具有很高的稳定行,能够适应目标的形状、大小的连续变化,而且计算速度很快,抗干扰能力强,能够保证系统的实时性和稳定性[1]。近年来在目标跟踪领域得到了广泛应用[2-3]。但是,核函数直方图对目标特征的描述比较弱,在目标周围存在与目标颜色分布相似的物体时,跟踪算法容易跟丢目标。目前对目标特征描述的改进只限于选择单一的特征,如文献[4]通过选择跟踪区域中表示目标主要特征的Harris点建立目标模型;文献[5]将初始帧的目标模型和前一帧的模型即两者的直方图分布都考虑进来,建立混合模型;文献[6]提出了以代表图像的梯度方向信息的方向直方图为目标模型;文献[7-8]提出二阶直方图,是对颜色直方图一种改进,是以颜色直方图为基础,颜色直方图只包含了颜色分布信息,二阶直方图在包含颜色信息的前提下包含了像素的均值向量和协方差。文献[9]提出目标中心加权距离,为离目标中心近的点赋予较大的权值,离目标中心远的点赋予较小的权值。文献[4-9]都是关注于目标和目标的某一种特征。但是使用单一特征的目标模型不能适应光线及背景的变化,而且当有遮挡和相似物体靠近时,容易丢失目标;若只是考虑改进目标模型,不考虑减弱背景的干扰,得到的效果毕竟是有限的。 针对上述问题,文本结合Itti 提出的视觉注意模型[5],将自底向上的视觉注意机制引入到Mean Shift跟踪中,提出了基于视觉显著图的Mean Shift跟踪方法。此方法在显著图基础上建立目标模型,由此得到的目标模型是用多种特征来描述的,同时可以降低背景对目标的干扰。 2 基于视觉显著图的Mean Shift跟踪方法
mean的现在分词
mean的现在分词 mean的现在分词现在分词: meaning meaning常见用法n.意思,意义; 含义; 意图; adj.有意思的; 意味深长的; vt.意味(mean的现在分词); 意思是; 1. politicians have debased the meaning of the word "freedom" 政客们贬低了“自由”一词的意义。 2. art has real meaning when it helps people to understand themselves. 当艺术有助于人们了解自身的时候才有真正的意义。 3. people use scientific terms with no clear idea of their meaning. 人们使用科学术语,但并非很清楚其含义。 4. she understood his meaning, if not his words, and took his advice. 她即便没听懂他的话,也明白了他的意思,并且接受了他的建议。 5. i have been working on exploding the myth of fixity of meaning. 我一直在致力于推翻有关意义恒定性的谬谈。
6. the television headlines seemed to wash over her without meaning anything. 电视节目的大标题一闪而过,似乎没有引起她的丝毫注意。 7. unsure of the meaning of this remark, ryle chose to remain silent. 由于不确定这句话究竟是什么意思,赖尔选择了保持沉默。 8. i hadn't a clue to the meaning of "activism" 我根本不明白activism的意思。 9. "morris" is an english corruption of "moorish", meaning north african. morris在英语中是moorish的变体,意思是“北非的”。 10. the meaning of that was lost on me. 那意思我没听懂。 mean词语用法v. mean的基本意思是“表示…的意思”,指某一动作或某件事物(如字母、信号等)具有某种意思,这一事物与其现在所表达意思是相同的。mean也可指“本意是,原意为”,指某一件事物最初的意思,这个意思与其现在所表示的意思可能不同。mean还可指“有某种重要性”。 mean多用作及物动词,其后可接名词、代词、动名词、动词不定式或that/wh-从句作宾语,有时还可接双宾语。mean也可接由动词不定式或“to be/as+ n. ”充当补足语的复合宾语。mean 偶尔也可用作不及物动词。 mean作“打算,企图”解时,要搭用动词不定式作宾语,此时如
mean的用法与搭配
mean后接不定式与接动名词 ■mean to do sth 的意思是:打算(想要)做某事。此时的主语只能是“人”。如: I had meant to leave on Sunday.我本打算周日走。 I mean to stay here for a long time.我打算在这儿呆很久。 I mean to get to the top by sunrise. 我打算在日出时到达山顶。Do forgive me—I didn’t mean to interrupt.真对不起——我不是有意打扰你。 Don’t give me then cold shoulder; I don’t mean to make you angry. 你别冷落我,我不是存心惹你生气的。 To mean to do something and to actually do something are two different things. 打算做一件事和实际上做一件事完全是两回事。 I meant to send the mover yesterday, but forgot. 本来我昨天就想派人把东西送来,可是我给忘了。 I had meant to come, but something happened. 我本想来,但有事就没有来。 mean通常不与否定的动词不定式搭配。如: I did not mean to hurt you.我并不是故意得罪你。 (不说:I meant not to hurt you.) I meant no harm to you.我对你并无恶意。 (不说:I meant not to harm you.)
t检验u检验卡方检验F检验方差分析
统计中经常会用到各种检验,如何知道何时用什么检验呢,根据结合自己的工作来说一说:t检验有单样本t检验,配对t检验和两样本t检验。 单样本t检验:是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。 配对t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。 u检验:t检验和就是统计量为t,u的假设检验,两者均是常见的假设检验方法。当样本含量n较大时,样本均数符合正态分布,故可用u检验进行分析。当样本含量n小时,若观察值x符合正态分布,则用t检验(因此时样本均数符合t分布),当x为未知分布时应采用秩和检验。 F检验又叫方差齐性检验。在两样本t检验中要用到F检验。 从两研究总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。若两总体方差相等,则直接用t检验,若不等,可采用t'检验或变量变换或秩和检验等方法。 其中要判断两总体方差是否相等,就可以用F检验。 简单的说就是检验两个样本的方差是否有显着性差异这是选择何种T检验(等方差双样本检验,异方差双样本检验)的前提条件。 在t检验中,如果是比较大于小于之类的就用单侧检验,等于之类的问题就用双侧检验。
卡方检验 是对两个或两个以上率(构成比)进行比较的统计方法,在临床和医学实验中应用十分广泛,特别是临床科研中许多资料是记数资料,就需要用到卡方检验。 方差分析 用方差分析比较多个样本均数,可有效地控制第一类错误。方差分析(analysis of variance,ANOVA)由英国统计学家R.A.Fisher首先提出,以F命名其统计量,故方差分析又称F检验。 其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。我们要学习的主要内容包括 单因素方差分析即完全随机设计或成组设计的方差分析(one-way ANOVA): 用途:用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。在实验研究中按随机化原则将受试对象随机分配到一个处理因素的多个水平中去,然后观察各组的试验效应;在观察研究(调查)中按某个研究因素的不同水平分组,比较该因素的效应。 两因素方差分析即配伍组设计的方差分析(two-way ANOVA): 用途:用于随机区组设计的多个样本均数比较,其统计推断是推断各样本所代表的各总体均数是否相等。随机区组设计考虑了个体差异的影响,可分析处理因素和个体差异对实验效应的影响,所以又称两因素实验设计,比完全随机设计的检验效率高。该设计是将受试对象先按配比条件配成配伍组(如动物实验时,可按同窝别、同性别、体重相近进行配伍),每个配伍组有三个或三个以上受试对象,再按随机化原则分别将各配伍组中的受试对象分配到各个处理组。值得注意的是,同一受试对象不同时间(或部位)重复多次测量所得到的资料称为重复测量数据(repeated measurement data),对该类资料不能应用随机区组设计的两因素方差分析进行处理,需用重复测量数据的方差分析。 方差分析的条件之一为方差齐,即各总体方差相等。因此在方差分析之前,应首先检验各样本的方差是否具有齐性。常用方差齐性检验(test for homogeneity of variance)推
Mean过程和T检验过程
一、Means过程 1.简单介绍 Means过程计算指定变量的综合描述计量,包括均值、标准差、总和、观测量数、方差等一系列单变量描述统计。当观测量按一个分类变量分组时,Means 过程可以进行分组计算。例如,要计算某地区高考的数学成绩,Sex变量把考生分为男生和女生两组,Means过程可以分别计算男女生的数学成绩。Means过程还可以给出方差分析表和线性检验结果。 使用Means过程求若干组的描述统计量的目的在于比较,因此必须求均值。这是与Descriptive过程不同之处。 2.完全窗口分析 Means过程的大部分功能可以完全由窗口实现,这给用户带来了很大的方便。 (1)Means主对话框 按Analyze →Compare Means →Means的顺序单击,即可打开“Means”主对话框,如图1所示。 图1 Means主对话框 (2)Dependent框 该框中的变量作为因变量,通常认为受自变量影响或决定,因此被用来预测或建模。 要从源变量框中选取变量进入该框,只需选中所要选取的变量,然后按向右的箭头即可。 (3)Independent框 该框中的变量是自变量,又被称为预测变量或解释变量。要运行Means过程,该框中必须至少有一个变量。要从源变量框中选取变量进入该框,同样只需激活所要选取的变量,然后按向右的箭头即可。 选中变量进入该框后,可以看到上方的【Next】按钮有效,单击该按钮进入下一层,在下一层的自变量将再细分样本。要回到上一层,单击【Previous】按钮即可。 (4)Options 对话框 单击Options按钮,即可打开“Options”对话框,如图2所示。
mean shift及其改进算法图像跟踪原理和应用
mean shift及其改进算法图像跟踪原理和应用Mean Shift 简介 Mean Shift 这个概念最早是由Fukunaga等人[1]于1975年在一篇关于概率密度梯度函数的估计中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift是一个名词,它指代的是一个向量,但随着Mean Shift理论的发展,Mean Shift的含义也发生了变化,如果我们说Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束. 然而在以后的很长一段时间内Mean Shift并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift的重要文献才发表.在这篇重要的文献中,Yizong Cheng对基本的Mean Shift算法在以下两个方面做了推广,首先Yizong Cheng定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift的适用范围.另外Yizong Cheng 指出了Mean Shift可能应用的领域,并给出了具体的例子. Comaniciu等人把Mean Shift成功的运用的特征空间的分析,在图
像平滑和图像分割中Mean Shift 都得到了很好的应用. Comaniciu 等在文章中证明了,Mean Shift 算法在满足一定条件下,一定可以收敛到最近的一个概率密度函数的稳态点,因此Mean Shift 算法可以用来检测概率密度函数中存在的模态. Comaniciu 等人还把非刚体的跟踪问题近似为一个Mean Shift 最优化问题,使得跟踪可以实时的进行. 在后面的几节,本文将详细的说明Mean Shift 的基本思想及其扩展,其背后的物理含义,以及算法步骤,并给出理论证明.最后本文还将给出Mean Shift 在聚类,图像平滑,图像分割,物体实时跟踪这几个方面的具体应用. Mean Shift 的基本思想及其扩展 基本Mean Shift 给定d 维空间d R 中的n 个样本点i x ,i=1,…,n,在x 点的Mean Shift 向量的基本形式定义为: ()()1 i h h i x S M x x x k ∈≡ -∑ (1) 其中,h S 是一个半径为h 的高维球区域,满足以下关系的y 点的集合, ()() (){ } 2:T h S x y y x y x h ≡--≤ (2) k 表示在这n 个样本点i x 中,有k 个点落入h S 区域中.
mean用法
mean用法 一.mean用作动词 1.mean的基本意思是“表示…的意思”,指某一动作或某件事物(如字母、信号等)具有某种意思,这一事物与其现在所表达意思是相同的。mean也可指“本意是,原意为”,指某一件事物最初的意思,这个意思与其现在所表示的意思可能不同。mean还可指“有某种重要性”。 2.mean多用作及物动词,其后可接名词、代词、动名词、动词不定式或that/wh-从句作宾语,有时还可接双宾语。mean也可接由动词不定式或“to be/as+ n. ”充当补足语的复合宾语。mean偶尔也可用作不及物动词。 3.mean作“打算,企图”解时,要搭用动词不定式作宾语,此时如以非谓语动词作主语,则该主语须用动名词。作“意味着”解,则要搭用动名词作宾语,此时如以非谓语动词作主语,则该主语须用动词不定式。 4.mean常用于过去完成时或一般过去时表示“希望”“预料”“打算”未能完成或未能实现。用于过去完成时时,多半搭用动词不定式的一般时态; 用于一般过去时则可搭用动词不定式的完成时,也可搭用一般时。
二.mean用作形容词 1.mean用作形容词时的意思是“吝啬的,自私的”,指对属于自己的东西格外的小气,不想让别人得到,或做事情只想到自己,而不替他人着想。mean也可指做事情采取不正当的或有损他人利益的手段,即“卑鄙的,不善良的”; 。mean还可指某人或某事处于不高不低(或不长不短)的水平,即“中间的,平均的”。 2.mean引申可指“难看的,劣质的,简陋的”“低劣的,平庸的”“出身微贱的,社会地位低下的”等。 3.mean可用来修饰人或具体的事物,也可以修饰抽象的事物。用作表语时,可接介词短语或动词不定式。 三.mean用作名词 1.mean用作名词时的意思是“中间,中庸”,指某事处于中间状态。也可表示“平均数,平均值”,指将两个或两个以上不同的数字相加,然后用相加后的总和再除以相加的数字的个数所得到的数。 2.mean作“中间”解时,通常后接介词between表示“在…两者之间的折中办法”。
MeanShift-图像分割方法
摘要 在图像处理和计算机视觉里,图像分割是一个十分基础而且很重要的部分,决定了最终分析结果的好坏。图像分割问题的典型定义就是如何在图像处理过程中将图像中的一致性区域和感兴趣对象提取出来。 MeanShift 图像分割方法是一种统计迭代的核密度估计方法。MeanShift算法以其简单有效而被广泛应用,但该方法在多特征组合方面和数据量较大的图像处理上仍存在不足之处,本文针对这些问题对该算法的结构进行了优化。本文利用图像上下文信息对图像进行了区域合并以此来对输入数据进行了压缩;并实现特征空间中所有特征量的优化组合。 最后,总结了本文的研究成果。下一步需要深入的研究工作有:(1)考虑分割的多尺度性,实现基于Mean Shift算法的多尺度遥感图像分割;(2)考虑利用Gabor滤波器来提取纹理特征,或将更多的特征如形状等特征用于MeanShift遥感图像分割中。 关键词: Mean Shift, 图像分割, 遥感图像, 带宽
ABSTRACT mage segmentation is very essential and critical to image processing and computer vision, which is one of the most difficult tasks in image processing, and determines the quality of the final result of analysis. In image segmentation problem, the typical goal is to extract continuous regions and interest objects in the case of image processing. The Mean Shift algorithm for segmentation is a statistical iterative algorithm based on kernel density estimation. Mean Shift algorithm has been widely applied for its simplicity and efficiency. But the algorithm has some deficiencies in feature combination and image processing for large data. According to the deficiencies of the Mean Shift algorithm, this paper optimizes the structure of the algorithm for segmentation. Firstly, this paper introduces a method of data compressing by merging the nearest points with similar properties into consistency regions. Secondly, We optimize the combination of features. At last, after concluding all research work in this paper, further work need to be in-depth studied: (1) Consider multi-scale factors of remote sensing, and realize multi-scale remote sensing image segmentation based on Mean Shift algorithm. (2) Consider extracting textures features by using Gabor filter, or use more features such as shape features to segment remote sensing images based on Mean Shift algorithm. KEY WORDS: Mean Shift, image segmentation, remote sensing images, bandwidth,
经典Mean Shift算法介绍
经典Mean Shift算法介绍 1无参数密度估计 (1) 2核密度梯度估计过程 (3) 3算法收敛性分析 (4) 均值漂移(Mean Shift)是Fukunaga等提出的一种非参数概率密度梯度估计算法,在统计相似性计算与连续优化方法之间建立了一座桥梁,尽管它效率非常高,但最初并未得到人们的关注。直到1995年,Cheng改进了Mean Shift算法中的核函数和权重函数,并将其应用于聚类和全局优化,才扩大了该算法的适用范围。1997年到2003年,Comaniciu等将该方法应用到图像特征空间的分析,对图像进行平滑和分割处理,随后他又将非刚体的跟踪问题近似为一个Mean Shift最优化问题,使得跟踪可以实时进行。由于Mean Shift算法完全依靠特征空间中的样本点进行分析,不需要任何先验知识,收敛速度快,近年来被广泛应用于模式分类、图像分割、以及目标跟踪等诸多计算机视觉研究领域。 均值漂移方法[4]是一种最优的寻找概率密度极大值的梯度上升法,提供了一种新的目标描述与定位的框架,其基本思想是:通过反复迭代搜索特征空间中样本点最密集的区域,搜索点沿着样本点密度增加的方向“漂移”到局部密度极大点。基于Mean Shift方法的目标跟踪技术采用核概率密度来描述目标的特征,由于目标的直方图具有特征稳定、抗部分遮挡、计算方法简单和计算量小的特点,因此基于Mean Shift的跟踪一般采用直方图对目标进行建模;然后通过相似性度量,利用Mean Shift搜寻目标位置,最终实现目标的匹配和跟踪。均值漂移方法将目标特征与空间信息有效地结合起来,避免了使用复杂模型描述目标的形状、外观及其运动,具有很高的稳定性,能够适应目标的形状、大小的连续变换,而且计算速度很快,抗干扰能力强,在解决计算机视觉底层任务过程中表现出了良好的鲁棒性和较高的实时处理能力。 1无参数密度估计 目标检测与跟踪过程中,必须用到一定的手段对检测与跟踪的方法进行优化,将目标的表象信息映射到一个特征空间,其中的特征值就是特征空间的随机变量。假定特征值服从已知函数类型的概率密度函数,由目标区域内的数据估计密度函数的参数,通过估计的参数得到整个特征空间的概率密度分布。参数密度估计通过这个方法得到视觉处理中的某些参数,但要求特征空间服从已知的概率
STATA 第四章 t检验和单因素方差分析命令输出结果说明
第四章 t检验和单因素方差分析命令与输出结果说明 ·单因素方差分析 单因素方差分析又称为Oneway ANOVA,用于比较多组样本的均数是否相同,并假定:每组的数据服从正态分布,具有相同的方差,且相互独立,则无效假设。 :各组总体均数相同。 原假设:H 在STATA中可用命令: oneway 观察变量分组变量[, means bonferroni] 其中子命令bonferroni是用于多组样本均数的两两比较检验。 例:测定健康男子各年龄组的淋巴细胞转化率(%),结果见表,问:各组的淋巴细胞转化率的均数之间的差别有无显著性? 健康男子各年龄组淋巴细胞转化率(%)的测定结果: 11-20 岁组:58 61 61 62 63 68 70 70 74 78 41-50 岁组:54 57 57 58 60 60 63 64 66 61-75 岁组:43 52 55 56 60 用变量x 表示这些淋巴细胞转化率以及用分组变量group=1,2,3分别表示 则用 STATA 命令: oneway x group, mean bonferroni | Summary of x group | Mean ① -------------+------------ 1 | 66.5 2 | 59.888889 3 | 53.2 ------+------------ Total | 61.25 ②
Analysis of Variance Source SS df MS F Prob > F ------------------------------------------------------------------------------- Between groups 616.311111③ 2 ④ 308.155556⑤ 9.77⑥ 0.0010⑦Within groups 662.188889⑧ 21⑨ 31.5328042⑴ ------------------------------------------------------------------------------- Total 1278.50 23 55.586956 (2)Bartlett's test for equal variances:chi2(2) = 2.1977 (3)Prob>chi2=0.333 Comparison of x by group (Bonferroni) Row Mean- | Col Mean | 1 2 -------------- --|-------------------------------------- 2 | -6.61111 (4) | 0.054 (5) | 3 | -13.3 (6) -6.68889(8) | 0.001 (7) 0.134 (9) ①对应三个年龄组的淋巴细胞转化率的均数;②三组合并在一起的总的样本 均数;③组间离均差平方和;④组间离均差平方和的自由度;⑤组间均方和(即: ⑤=③/④);⑧组内离均差平方和;⑨组内离均差平方和的自由度;(1)组内均 方和(即:(1)=⑧/⑨);⑥为F 统计值(即为⑤/(1));⑦为相应的p值;(2) 为方差齐性的Bartlett检验;(3)方差齐性检验相应的p值;(4)第二组的淋 巴细胞转化率样本均数—第一组的淋巴细胞转化率的样本均数的差;(5)第二和 第一组均数差的显著性检验所对应p 值;(6)第三组的淋巴细胞转化率样本均数—第一组的淋巴细胞转化率的样本均数的差;(7)第三和第一组均数差的显著 性检验所对应的 p 值;(8)第三组的淋巴细胞转化率样本均数—第二组的淋巴 细胞转化率的样本均数的差;(9)第三和第二组均数差的显著性检验所对应的p 值。 由上述结果可知:三组方差无显著地齐性,因此若三组数据近似服从正态 分布,无效假设Ho检验所对应的p值<0.01,可以认为这三组均数有显著差异。 由 Bonferroni统计检验结果表明:第一组淋巴细胞转化率显著地高于第三组淋 巴细胞转化率(p<0.005),其它各组之间均数无显著性差异。
初中英语-mean用法总结
mean用法总结,mean的用法及短语有哪些 mean用法总结 1. mean doing sth. mean doing sth. 的意思是“意味着(必须要做某事或导致某种结果)”,其主语通常是指事物的词。例如: Being a student means studying hard. 作为一个学生,(意味着)你要努力学习。 Success means working hard. 成功意味着工作努力。 【误】Success means to work hard. 2. mean to do sth. mean to do sth. 的意思是“打算或企图做某事”, 其主语通常是表示人的名词或代词,其过去完成式表示“本来打算做某事”。例如: What do you mean to do with it? 你打算把它怎样处理? We mean to call on you tomorrow. 我们打算明天看望你。 He had meant to leave on Sunday, but has stayed on. 他本来想星期天走的,但又留了下来。 【误】We mean calling on you tomorrow. don't mean to do sth. 是其否定式,通常表示“无意做某事”。例如: John really upset Granny,but I'm sure he did not mean to. 约翰真让奶奶心烦,不过我相信他是无意的。 3. mean sb. to do sth. mean sb. to do sth.的意思是“打算让某人做某事”。例如: I mean you to work as our spokesman. 我想请你当我们的代言人。 Do you really mean him to believe that your plan was right? 你真打算让他相信你的计划是对的吗? 4. mean后接名词、副词或从句
- 医学统计学t检验和方差分析
- 最新sas第九章 t检验和方差分析
- T检验及其与方差分析的区别
- T检验及其与方差分析的区别
- 第5章 SPSS均值比较T检验和方差分析
- t检验与方差分析
- t检验和方差分析的前提条件及应用误区
- t检验与方差分析(1)
- t检验u检验卡方检验F检验方差分析
- T检验及其与方差分析的区别.docx
- 第5章 SPSS均值比较、T检验和方差分析
- t检验与单因素方差分析
- STATA 第四章 t检验和单因素方差分析命令输出结果说明
- t检验、卡方检验、方差分析
- t检验和方差分析的前提条件及应用误区
- t检验与单因素方差分析
- spsst检验与方差分析
- SPSS t检验和方差分析1
- T检验与单因素方差分析
- 线性回归的方差分析和回归系数的t检验