试验设计与数据处理课后习题

试验设计与数据处理课后习题
机械工程6120805019 李东辉第三章
3-7
分别使用金球和铂球测定引力常数(单位:)
1. 用金球测定观察值为 6.683,6.681, 6.676, 6.678, 6.679, 6.672
2. 用铂球测定观察值为 6.661, 6.661,6.667, 6.667, 6.664
设测定值总体为N(u,)试就1,2两种情况求u的置信度为0.9的置信区间,并求的置信度为0.9的置信区间。
用sas分析结果如下:
第一组:
第二组:
3-13
下表分别给出两个文学家马克吐温的8篇小品文以及斯诺特格拉斯的10篇小品文中由3个字母组成的词的比例:
马克吐温:0.225 0.262 0.217 0.240 0.230 0.229 0.235 0.217
斯诺特格拉斯:0.209 0.205 0.196 0.210 0.202 0.207 0.224 0.223 0.220 0.201
设两组数据分别来自正态总体,且两个总体方差相等,两个样本相互独立,问两个作家所写的小品文中包含由3个字母组成的词的比例是否有显著差异(a=0.05)
取假设H0:u1-u2≤0和假设H1:u1-u2>0用sas分析结果如下:
Sample Statistics
Group N Mean Std. Dev. Std. Error
----------------------------------------------------
x 8 0.231875 0.0146 0.0051
y 10 0.2097 0.0097 0.0031
Hypothesis Test
Null hypothesis: Mean 1 - Mean 2 = 0
Alternative: Mean 1 - Mean 2 ^= 0
If Variances Are t statistic Df Pr > t
----------------------------------------------------
Equal 3.878 16 0.0013
Not Equal 3.704 11.67 0.0032
由此可见p值远小于0.05,可认为拒绝原假设,即认为2个作家所写的小品文中由3个字母组成的词的比例均值差异显著。
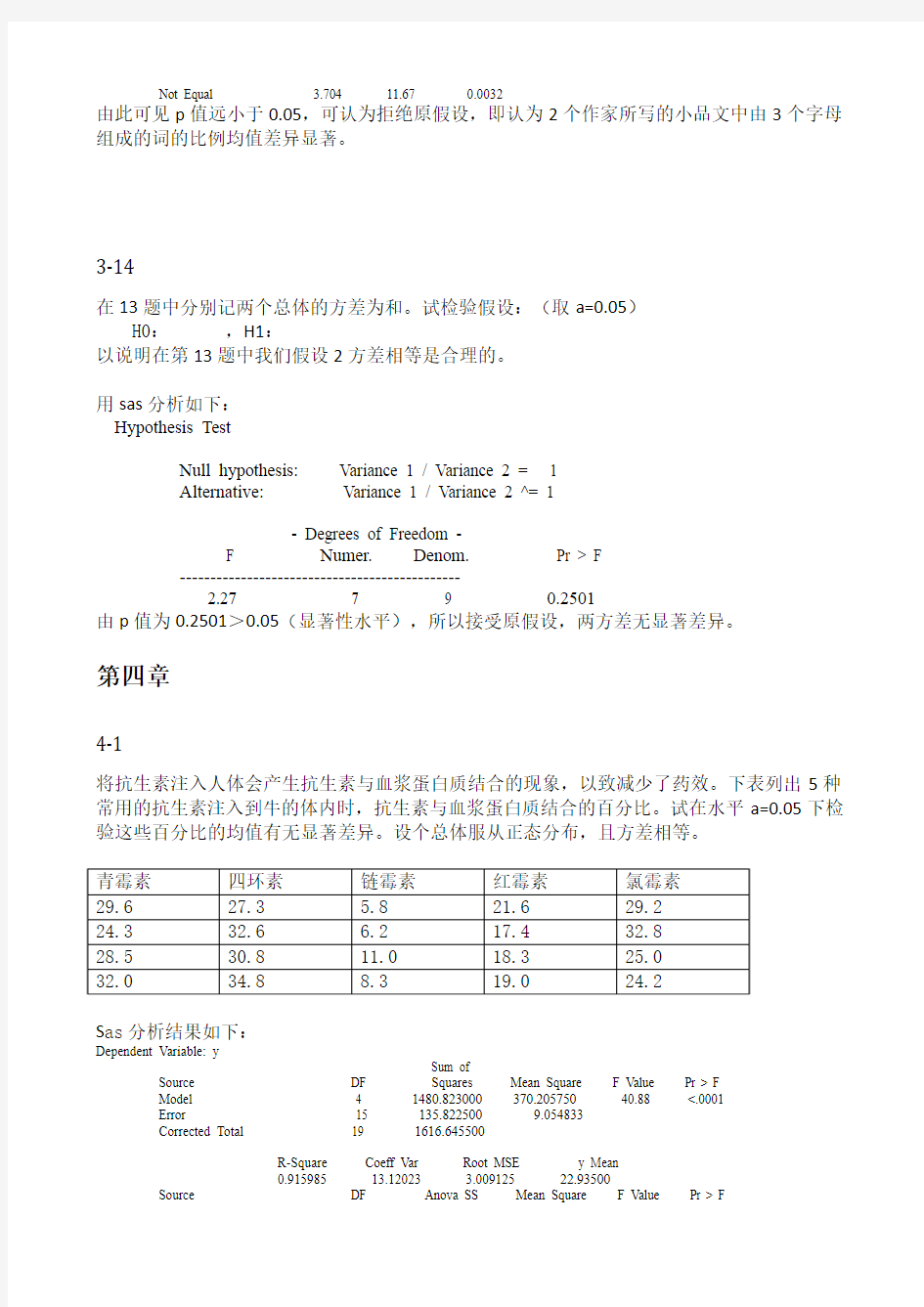
3-14
在13题中分别记两个总体的方差为和。试检验假设:(取a=0.05)
H0:,H1:
以说明在第13题中我们假设2方差相等是合理的。
用sas分析如下:
Hypothesis Test
Null hypothesis: Variance 1 / Variance 2 = 1
Alternative: Variance 1 / Variance 2 ^= 1
- Degrees of Freedom -
F Numer. Denom. Pr > F
----------------------------------------------
2.27 7 9 0.2501
由p值为0.2501>0.05(显著性水平),所以接受原假设,两方差无显著差异。
第四章
4-1
将抗生素注入人体会产生抗生素与血浆蛋白质结合的现象,以致减少了药效。下表列出5种常用的抗生素注入到牛的体内时,抗生素与血浆蛋白质结合的百分比。试在水平a=0.05下检验这些百分比的均值有无显著差异。设个总体服从正态分布,且方差相等。
S as分析结果如下:
Dependent Variable: y
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 4 1480.823000 370.205750 40.88 <.0001
Error 15 135.822500 9.054833
Corrected Total 19 1616.645500
R-Square Coeff Var Root MSE y Mean
0.915985 13.12023 3.009125 22.93500
Source DF Anova SS Mean Square F Value Pr > F
c 4 1480.823000 370.205750 40.88 <.0001
由结果可知,p值小于0.001,故可认为在水平a=0.05下,这些百分比的均值有显著差异。
4-2
下表给出某种化工生产过程在三种浓度、四种温度水平下得率的数据:
度下得率有无显著差异;在不同温度下的率是否有显著差异;交互作用的效应是否显著。
The GLM Procedure
Dependent Variable: R
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 11 82.8333333 7.5303030 1.39 0.2895
Error 12 65.0000000 5.4166667
Corrected Total 23 147.8333333
R-Square Coeff Var Root MSE R Mean
0.560316 22.34278 2.327373 10.41667
Source DF Type I SS Mean Square F Value Pr > F
m 2 44.33333333 22.16666667 4.09 0.0442
n 3 11.50000000 3.83333333 0.71 0.5657
m*n 6 27.00000000 4.50000000 0.83 0.5684
Source DF Type III SS Mean Square F Value Pr > F
m 2 44.33333333 22.16666667 4.09 0.0442
n 3 11.50000000 3.83333333 0.71 0.5657
m*n 6 27.00000000 4.50000000 0.83 0.5684
由结果可知,在不同浓度下得率有显著差异,在不同温度下得率差异不明显,交互作用的效应不显著。
第五章
5-3
配比试验。四因素ABCD的水平表如下(因素C用了一个拟水平):
091.05.02.03.01.011.0A =+++?= 273.05
.02.03.01.013.0B =+++?= 182.05.02.03.01.012.0C =+++?= 455.05
.02.03.01.015.0D =+++?= 2号实验:A:B:C:D=0.1:0.4:0.1:0.3,要求四个比值之和为1,所以:
111.03.01.04.01.011.0A =+++?= 444.03
.01.04.01.014.0B =+++?= 111.03.01.04.01.011.0C =+++?= 333.03
.01.04.01.013.0D =+++?= 3号实验:A:B:C:D=0.1:0.5:0.1:0.1,要求四个比值之和为1,所以:
125.01.01.05.01.011.0A =+++?= 625.01
.01.05.01.015.0B =+++?= 125.01.01.05.01.011.0C =+++?= 125.01
.01.05.01.011.0D =+++?= 4号实验:A:B:C:D=0.3:0.3:0.1:0.1,要求四个比值之和为1,所以:
375.01.01.03.03.013.0A =+++?= 375.01
.01.03.03.013.0B =+++?= 125.01.01.03.03.011.0C =+++?= 125.01
.01.03.03.011.0D =+++?= 5号实验:A:B:C:D=0.3:0.4:0.1:0.5,要求四个比值之和为1,所以:
231.05.01.04.03.013.0A =+++?= 308.05
.01.04.03.014.0B =+++?= 077.05.01.04.03.011.0C =+++?= 385.05
.01.04.03.015.0D =+++?=
6号实验:A:B:C:D=0.3:0.5:0.2:0.3,要求四个比值之和为1,所以:
231.03.02.05.03.013.0A =+++?= 385.03
.02.05.03.015.0B =+++?= 154.03.02.05.03.012.0C =+++?= 231.03
.02.05.03.013.0D =+++?= 7号实验:A:B:C:D=0.2:0.3:0.1:0.3,要求四个比值之和为1,所以:
222.03.01.03.02.012.0A =+++?= 333.03
.01.03.02.013.0B =+++?= 111.03.01.03.02.011.0C =+++?= 333.03
.01.03.02.013.0D =+++?= 8号实验:A:B:C:D=0.2:0.4:0.2:0.1,要求四个比值之和为1,所以:
222.01.02.04.02.012.0A =+++?= 444.01
.02.04.02.014.0B =+++?= 222.01.02.04.02.012.0C =+++?= 222.01
.02.04.02.012.0D =+++?= 9号实验:A:B:C:D=0.2:0.5:0.1:0.5,要求四个比值之和为1,所以:
154.05.01.05.02.012.0A =+++?= 385.05
.01.05.02.015.0B =+++?= 077.05.01.05.02.011.0A =+++?= 385.05
.01.05.02.015.0D =+++?= 第六章
6-5
作出散点图如下:
S as分析结果如下:
Dependent Variable: y
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 38.93714 19.46857 9.54 0.0033
Error 12 24.47619 2.03968
Corrected Total 14 63.41333
Root MSE 1.42817 R-Square 0.6140
Dependent Mean 30.03333 Adj R-Sq 0.5497
Coeff Var 4.75530
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 19.03333 3.27755 5.81 <.0001
t1 1 1.00857 0.35643 2.83 0.0152
t2 1 -0.02038 0.00881 -2.31 0.0393
所以截距为19.03333 t1=1.00857 t2=-0.02038
所以y=19.03333+1.00857x-0.02038x^2
6-6
某化工产品的得率y与反应温度x1、反应时间x2及某反应物浓度x3有关,设对于给定的x1、x2、x3得率y服从正态分布且方差与x1、x2、x3无关,今得实验结果如下表所示,其中x1、
(2)在a=0.05下做逐项检验,求y的多元线性回归方程。
(1)sas分析如下:
Dependent Variable: y
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 3 15.64500 5.21500 15.17 0.0119
Error 4 1.37500 0.34375
Corrected Total 7 17.02000
Root MSE 0.58630 R-Square 0.9192
Dependent Mean 9.90000 Adj R-Sq 0.8586
Coeff Var 5.92224
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 9.90000 0.20729 47.76 <.0001
x1 1 0.57500 0.20729 2.77 0.0501
x2 1 0.55000 0.20729 2.65 0.0568
x3 1 1.15000 0.20729 5.55 0.0052
由此可见,回归方程为:
由p值可知,每项都是显著的。方程也是显著的。
(2) Stepwise Selection: Step 3
Variable x2 Entered: R-Square = 0.9192 and C(p) = 4.0000
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 3 15.64500 5.21500 15.17 0.0119
Error 4 1.37500 0.34375
Corrected Total 7 17.02000
Parameter Standard
Variable Estimate Error Type II SS F Value Pr > F
Intercept 9.90000 0.20729 784.08000 2280.96 <.0001
x1 0.57500 0.20729 2.64500 7.69 0.0501
x2 0.55000 0.20729 2.42000 7.04 0.0568
x3 1.15000 0.20729 10.58000 30.78 0.0052
Bounds on condition number: 1, 9
------------------------------------------------------------------------------------------------------
All variables left in the model are significant at the 0.1500 level.
All variables have been entered into the model.
Summary of Stepwise Selection
Variable Variable Number Partial Model
Step Entered Removed Vars In R-Square R-Square C(p) F Value Pr
1 x3 1 0.6216 0.6216 14.7345 9.86 0.0201
2 x1 2 0.1554 0.7770 9.0400 3.48 0.1209
3 x2 3 0.1422 0.9192 4.0000 7.0
4 0.0568
由最后一张表可知,在a=0.05下,仅有x3和x1应当引入方程。
故所求方程为:y =9.90+0.575x1+1.150x3
6-9
16次发酵猪饲料试验结果如下表,其中x1、x2、x3、x4和y 分别表示发酵温度、发酵时间、ph 值、投曲量和酸度。试用逐步回归方法选择适当的x1、x2、x3和x4的二次多项式,以预
Dependent Variable: y
Stepwise Selection: Step 1
Variable t9 Entered: R-Square = 0.3473 and C(p) = 175.7517
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 1 76.24389 76.24389 7.45 0.0163
Error 14 143.28371 10.23455
Corrected Total 15 219.52760
Parameter Standard
Variable Estimate Error Type II SS F Value Pr > F
Intercept 8.22980 1.38618 360.74949 35.25 <.0001
t9 0.01056 0.00387 76.24389 7.45 0.0163
Bounds on condition number: 1, 1
------------------------------------------------------------------------------------------------------
Stepwise Selection: Step 2
Variable t13 Entered: R-Square = 0.6717 and C(p) = 84.4265
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 147.46551 73.73276 13.30 0.0007
Error 13 72.06209 5.54324
Corrected Total 15 219.52760
Parameter Standard
Variable Estimate Error Type II SS F Value Pr > F
Intercept 18.33483 2.99803 207.32264 37.40 <.0001
t9 0.01173 0.00287 92.81733 16.74 0.0013
t13 -1.89938 0.52989 71.22162 12.85 0.0033
------------------------------------------------------------------------------------------------------
Stepwise Selection: Step 3
Variable t5 Entered: R-Square = 0.7627 and C(p) = 60.2727
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 3 167.42492 55.80831 12.85 0.0005
Error 12 52.10268 4.34189
Corrected Total 15 219.52760
Parameter Standard
Variable Estimate Error Type II SS F Value Pr > F
Intercept 19.49941 2.70837 225.06452 51.84 <.0001
t5 0.00163 0.00076176 19.95941 4.60 0.0532
t9 0.00728 0.00328 21.44626 4.94 0.0462
t13 -2.19305 0.48856 87.48515 20.15 0.0007
Bounds on condition number: 1.8185, 13.825
------------------------------------------------------------------------------------------------------
All variables left in the model are significant at the 0.1500 level.
No other variable met the 0.1500 significance level for entry into the model.
Summary of Stepwise Selection
Variable Variable Number Partial Model
Step Entered Removed Vars In R-Square R-Square C(p) F Value Pr > F
1 t9 1 0.3473 0.3473 175.75
2 7.45 0.0163
2 t1
3 2 0.324
4 0.6717 84.426
5 12.85 0.0033
3 t5 3 0.0909 0.7627 60.2727 4.60 0.0532由结果可知,y=19.49941+0.00163+0.00728-2.19305
6-10
(1)画出y.x散点图如下:
采用Gompertz,Logistic,Richhards,Margan-Mercer-Flodin和Welbull都可以。(2)用Logistic模拟结果为:
Dependent Variable y
Method: Gauss-Newton
Sum of
Iter b c a Squares
0 3.7180 2.0000 21.0000 1124.1
1 3.6408 1.8493 14.8393 570.9
2 3.5475 1.6684 14.9977 534.7
3 3.470
4 1.5208 15.2362 499.4
4 3.4046 1.3963 15.4814 464.3
5 3.3469 1.2887 15.7348 429.2
6 3.2955 1.1943 15.9985 394.1
7 3.2491 1.1107 16.2735 359.1
8 3.2069 1.0360 16.5601 324.4
9 3.1684 0.9691 16.8579 290.5
10 3.1331 0.9091 17.1660 257.6
11 3.1008 0.8551 17.4829 226.3
12 3.0712 0.8067 17.8067 196.8
13 3.0442 0.7632 18.1349 169.7
14 3.0195 0.7242 18.4653 145.1
15 2.9971 0.6892 18.7951 123.1
16 2.9768 0.6580 19.1220 104.0
17 2.9584 0.6300 19.4438 87.4241
18 2.9420 0.6050 19.7586 73.4129
19 2.9272 0.5827 20.0648 61.7148
20 2.9140 0.5628 20.3610 52.0895
21 2.9023 0.5450 20.6464 44.2826
22 2.8920 0.5291 20.9203 38.0422
23 2.8828 0.5149 21.1822 33.1304
24 2.8748 0.5021 21.4319 29.3307
25 2.8679 0.4907 21.6693 26.4509
26 2.8618 0.4804 21.8946 24.3243
27 2.8566 0.4711 22.1078 22.8087
28 2.8522 0.4628 22.3094 21.7843
29 2.8484 0.4553 22.4995 21.1514
30 2.8453 0.4486 22.6787 20.8276
31 2.8428 0.4425 22.8472 20.7456
WARNING: Step size shows no improvement.
WARNING: PROC NLIN failed to converge.
Estimation Summary (Not Converged)
Method Gauss-Newton
Iterations 31
Subiterations 29
Average Subiterations 0.935484
R 0.653053
PPC(c) 0.012486
The NLIN Procedure
Estimation Summary (Not Converged)
RPC .
Object 0.00394
Objective 20.74557
Observations Read 15
Observations Used 15
Observations Missing 0
NOTE: An intercept was not specified for this model.
Sum of Mean Approx
Source DF Squares Square F Value Pr > F
Regression 3 3245.5 1081.8 625.77 <.0001
Residual 12 20.7456 1.7288
Uncorrected Total 15 3266.3
Corrected Total 14 949.9
Approx
Parameter Estimate Std Error Approximate 95% Confidence Limits
b 2.8428 0.00488 2.8321 2.8534
c 0.4425 0.00321 0.4355 0.4494
a 22.8472 0.5749 21.5947 24.0998
Approximate Correlation Matrix
b c a
b 1.0000000 0.7483922 -0.2191675
c 0.7483922 1.0000000 -0.4085662
a -0.2191675 -0.4085662 1.0000000
故得
(3)将α、β、γ改为a,b,c 表示参数,x 是自变量
(4) 由()
x c -b exp 1a y ?+=得,当∞→x 时,y=a ,又由散点图看出∞→x 时,max y y =,所以25a ≈,再由???? ??=?1-y a ln x c -b 通过x 的观察值和???
? ??1-y a ln 的值的散点图估计处b 、c 的值:用一直线接近这些点,b 是这直线的截距1,c 是斜率0.1
第七章
7-1
(设)作变换 x=(z-39)/0.5+1=2z-77
并可设y =b0+b1Ф1(x)+ b2Ф2(x)+ b2Ф2(x)+ b4Ф4(x)
差附表6可得:
正交多项表
k Ф1(k)Ф2(k)Ф3(k)Ф4(k)
1 -4 28 -14 14
2 -
3 7 7 -21
3 -2 -8 13 -11
4 -1 -17 9 9
5 0 -20 0 18
6 1 -1
7 -9 9
7 2 -8 -13 -11
8 3 7 -7 -21
9 4 28 14 14
1 3 5/6 7/1
2 SAS程序:
data E701;
input z y @@;
t1=z; t2=z**2; t3=z**3; t4=z**4;
cards;
39 2.1
39.5 1.83
40 1.53
40.5 1.7
41 1.8
41.5 1.9
42 2.35
42.5 2.54
43 2.9
;
proc print;
run;
data E7011;
input w1 w2 w3 w4 y @@;
cards;
-4 28 -14 14 2.1
-3 7 7 -21 1.83
-2 -8 13 -11 1.53
-1 -17 9 9 1.7
0 -20 0 18 1.8
1 -17 -9 9 1.9
2 -8 -1
3 -11 2.35
3 7 -7 -21 2.54
4 28 14 14 2.9
;
run;
proc orthoreg data= E7011;
model y=w1-w4;
run;
运行结果如下:
The SAS System 13:31 Wednesday, November 28, 2011 2
The ORTHOREG Procedure
Dependent Variable: y
Sum of
Source DF Squares Mean Square F Value
Pr > F
Model 4 1.5437287599 0.38593219 46.46 0.0013
Error 4 0.0332267957 0.0083066989
Corrected Total 8 1.5769555556
Root MSE 0.0911410934
R-Square 0.9789297831
Standard
Variable DF Parameter Estimate Error t Value Pr > |t|
Intercept 1 2.07282769839883 0.0304524004 68.07
<.0001
w1 1 0.11959082142649 0.0117704537 10.16
0.0005
w2 1 0.01524435863815 0.0017349336 8.79
0.0009
w3 1 -0.00634246825283 0.0029017133 -2.19
0.0941
w4 1 0.00060547617661 0.0020933576 0.29
0.7868
由结果分析得,w3、w4的P值都大于0.05,说明三次项、四次项不显著,回归方程只需要配到二次就可以了。只保留一次项、二次项进行SAS 操作:
SAS程序:
proc orthoreg data=E7011;
model y=w1 w2;
run;
运行结果如下:
The SAS System 13:31 Wednesday, November 28, 2011 5
The ORTHOREG Procedure
Dependent Variable: y
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 2 1.5038288889 0.7519144444 61.69 <.0001
Error 6 0.0731266667 0.0121877778
Corrected Total 8 1.5769555556
Root MSE 0.1103982689
R-Square 0.953627947
Standard
Variable DF Parameter Estimate Error t Value Pr > |t|
Intercept 1 2.07222222222222 0.036799423 56.31 <.0001
w1 1 0.1195 0.0142523552 8.38 0.0002
w2 1 0.01527777777777 0.0020968417 7.29 0.0003
从结果可以看到模型的Pr<.0001,说明模型更加显著了。b1、b2的值分别是0.1195、0.01527777777777。
1112
2222()()5
758()()3(10)3303796x x x x x x x x x ?λφ?λφ==-==?-+=-+ 011222()()
2.072220.1195(5)0.01528(330379)y b b x b x x x x ??=++=+?-+?-+
将277x z =-代入上式得所求多项式回归方程:20.1833614.79452304.5489y z z =-+
7-3
苯酚的产率y 与因素z1、z2、z3、z4有关:
Z 1—反应温度,300-320; z2—反应时间,20-30分钟
Z 3—压力,200—250个大气压; z4—NaoH 溶液用量,80—100升,按正交表排好试验,的结果如下,试求线性回归方程(令),并做回归的显著性检验。(a=0.05)
采用二水平,做变换:x1=103101-z ,x2=5252-z ,x3=252253-z ,x4=10
904-z 改造过的正交表()782L
SAS 程序:
data E703;
input x1-x4 y;
cards;
1 1 1 1 92.4
1 1 -1 -1 90.4
1 -1 1 -1 87.8
1 -1 -1 1 87.3
-1 1 1 -1 84.5
-1 1 -1 1 86.0
-1 -1 1 1 83.7
-1 -1 -1 -1 83.4
;
proc reg data=E703;
model y=x1-x4;
run;
运行结果如下:
The SAS System 13:54 Wednesday, November 28, 2011 2
The REG Procedure
Model: MODEL1
Dependent Variable: y
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 4 68.48500 17.12125 12.73 0.0317
Error 3 4.03375 1.34458
Corrected Total 7 72.51875
Root MSE 1.15956 R-Square 0.9444 Dependent Mean 86.93750 Adj R-Sq 0.8702 Coeff Var 1.33379
Parameter Estimates
Parameter Standard
Variable DF Estimate Error t Value Pr > |t|
Intercept 1 86.93750 0.40997 212.06 <.0001
x1 1 2.53750 0.40997 6.19 0.0085
x2 1 1.38750 0.40997 3.38 0.0430
x3 1 0.16250 0.40997 0.40 0.7183 x4 1 0.41250 0.40997 1.01 0.3885
x3、x4 的P 值大于0.05,不显著,删掉后重新进行检验。
SAS 程序:
proc orthoreg data=E703;
model y=x1 x2;
run;
运行结果如下:
The SAS System 13:54 Wednesday, November 28, 2012 3
The ORTHOREG Procedure
Dependent Variable: y
Sum of
Source DF Squares Mean Square F Value Pr > F
Model 2 66.9125 33.45625 29.84 0.0017
Erro 5 5.60625 1.12125
Corrected Total 7 72.51875
Root MSE 1.0588909292
R-Square 0.9226924071
Standar Variable DF Parameter Estimate Error t Value Pr > |t|
Intercept 1 86.9375 0.3743744783 232.22 <.0001
x1 1 2.5375 0.3743744783 6.78 0.0011
x2 1 1.3875 0.3743744783 3.71 0.0139
与第一次分析结果相比,模型的显著性明显提高。y=86.93750+2.53750x1+1.38750x2,用z1、
z2替换x1、x2,得回归方程y =0.25375 z1+0.2375 z2+1.3375
第八章
8-1
安排方案如下:每个因素各水平等间距取值,则因素水平如表所示
选用)5(45U 表,按使用表把z1,z2,z3三个因素分别放在
)5(45U 的1,2,4列,即得实验方案如表
第九章
9-1
(1)反射点E 的坐标(5,310
,0)
(2)(i )扩大,а>1(ii )内收缩,а<0(iii )收缩,0<а<1
(3)新单纯形各点坐标B(2,4,3),A ’(1.5,3,3.5),C ’(2.5,2.5,2.5),D ”(3,3.5,2)。
第十章
10-4
分析酶絮凝的适宜条件。
经分析可知,在a=0.05的情况下,一次项均不显著,二次项、交互项均是显著地,求得最优适宜条件是交互条件下的情况
第十二章
12-4
1y :0.2 =<)(1x x P 0.2/2=0.1,
2y :0.4 =<)(2x x P 0.2+0.4/2=0.4,
3y :0.3 =<)(3x x P 0.6+0.3/2=0.75,
4y :0.1 =<)(4x x P 0.9+0.1/2=0.95,
查正太分布表,就可到:
1x =-1.29 2x =-0.26 3x =0.68 4x =1.65
第十三章
ppt 上
前3个主成分的累积方差贡献率达到86.66%,损失信息较少,并且此时特征根数值接近1
或大于1,从第4个特征根开始数值明显减少。前3个主成分与原8个单指标线性组合如下:Prin1=0.47665x1+0.472808x2+0.423845x3-0.212893x4-0.38846x5-0.352427x6+0.214835x7+0.055 034x8
Prin2=0.295991x1+0.277894x2+0.377951x3+0.451408x4+0.330945x5+0.402737x6-0.377415x7+0. 272736x8
Prin3=0.10419x1+0.162983x2+0.156255x3-0.008544x4+0.321133x5+0.145144x6+0.140459x7-0.8 91162x8
排序结果为:
第十四章
14-1
解:
(1)最大隶属度原则:
0 4/9 1/9 4/9
1/3 5/9 0 1/9
R= 1/3 4/9 2/9 0
0 2/3 1/3 0
0 1/9 8/9 0
权重向量a=(0.30,0.25,0.15,0.20,0.10)
所以b=aR=(2/15,23/60, 2/9, 29/180 )
根据最大隶属度原则取最大值23/60所对应的评语作为该食品的感官评定结果,即一般。
秩加权平均原则:
用1、2、3、4分别代表差、一般、良好、优,
A=(1*2/15+2*23/60+3*2/9+4*29/180)=2.21
2.46位于一般与良好之间,且该食品一般偏良
(2)100*2/15+80*23/60+60*2/9+40*29/180=64.33
第十五章
15-3
编程
data zl;
input bh cs ss lj tt jm ym;
cards;
1 14 13 28 14 2
2 39
2 10 14 15 14 34 35
3 11 12 19 13 2
4 39
4 7 7 7 9 20 23
5 13 12 24 12 2
6 38
6 19 14 22 16 23 37
7 20 16 26 2 38 69
8 9 10 14 9 31 46
9 9 8 15 13 14 46
10 9 9 12 10 23 46
;
proc cluster /*系统聚类*/ data = zl method=average;/*类平均法*/
var cs ss lj tt jm ym;
id bh;
proc tree horizontal spaces=2; /*水平树*/ id bh;/*编号为样本*/
proc cluster data=zl method=centroid;/*重心法*/
var cs ss lj tt jm ym;
id bh;
proc tree horizontal spaces=2; id bh;
proc cluster data=zl method =density k=3;/*密度估计法*/
var cs ss lj tt jm ym;
id bh;
proc tree horizontal spaces=2; id bh;
proc cluster data=zl method=single;/*最小距离法*/
var cs ss lj tt jm ym;
id bh;
实验设计与数据处理心得
实验设计与数据处理心得体会 刚开始选这门课的时候,我觉得这门课应该就是很难懂的课程,首先我们做过不少的实验了,当然任何自然科学都离不开实验,大多数学科(化工、化学、轻工、材料、环境、医药等)中的概念、原理与规律大多由实验推导与论证的,但我觉得每次到处理数据的时候都很困难,所以我觉得这就是门难懂的课程,却也就是很有必要去学的一门课程,它对于我们工科生来说也就是很有用途的,在以后我们实验的数据处理上有很重要的意义。 如何科学的设计实验,对实验所观测的数据进行分析与处理,获得研究观测对象的变化规律,就是每个需要进行实验的人员需要解决的问题。“实验设计与数据处理”课程就就是就是以概率论数理统计、专业技术知识与实践经验为基础,经济、科学地安排试验,并对试验数据进行计算分析,最终达到减少试验次数、缩短试验周期、迅速找到优化方案的一种科学计算方法。它主要应用于工农业生产与科学研究过程中的科学试验,就是产品设计、质量管理与科学研究的重要工具与方法,也就是一门关于科学实验中实验前的实验设计的理论、知识、方法、技能,以及实验后获得了实验结果,对实验数据进行科学处理的理论、知识、方法与技能的课程。 通过本课程的学习,我掌握了试验数据统计分析的基本原理,并能针对实际问题正确地运用,为将来从事专业科学的研究打下基础。这门课的安排很合理,由简单到复杂、由浅入深的思维发展规律,先讲单因素试验、双因素试验、正交试验、均匀试验设计等常用试验设计
方法及其常规数据处理方法、再讲误差理论、方差分析、回归分析等数据处理的理论知识,最后将得出的方差分析、回归分析等结论与处理方法直接应用到试验设计方法。 比如我对误差理论与误差分析的学习:在实验中,每次针对实验数据总会有误差分析,误差就是进行实验设计与数据评价最关键的一个概念,就是测量结果与真值的接近程度。任何物理量不可能测量的绝对准确,必然存在着测定误差。通过学习,我知道误差分为过失误差,系统误差与随机误差,并理解了她们的定义。另外还有对准确度与精密度的学习,了解了她们之间的关系以及提高准确度的方法等。对误差的学习更有意义的应该就是如何消除误差,首先消除系统误差,可以通过对照试验,空白试验,校准仪器以及对分析结果的校正等方法来消除;其次要减小随机误差,就就是要在消除系统误差的前提下,增加平行测定次数,可以提高平均值的精密度。 比如我对方差分析的理解:方差分析就是实验设计中的重要分析方法,应用非常广泛,它就是将不同因素、不同水平组合下试验数据作为不同总体的样本数据,进行统计分析,找出对实验指标影响大的因素及其影响程度。对于单因素实验的方差分析,主要步骤如下:建立线性统计模型,提出需要检验的假设;总离差平方与的分析与计算;统计分析,列出方差分析表。对于双因素实验的方差分析,分为两种,一种就是无交互作用的方差分析,另一种就是有交互作用的方差分析,对于这两种类型分别有各自的设计方法,但就是总体步骤都与单因素实验的方差分析一样。
EXCEL数据处理题库题目
E X C E L数据处理题库题 目 The pony was revised in January 2021
Excel数据处理 ==================================================题号:15053 注意:下面出现的所有文件都必须保存在考生文件夹下。 提示:[答题]按钮只会自动打开题中任意一个文件。 在[D:\exam\考生文件夹\Excel数据处理\1]下, 找到文件或文件: 1. 在考生文件夹下打开文件, (1)将Sheet1工作表的A1:E1单元格合并为一个单元格,内容水平居中; (2)在E4单元格内计算所有考生的平均分数 (利用AVERAGE函数,数值型,保留小数点后1位), 在E5和E6单元格内计算笔试人数和上机人数(利用COUNTIF函数), 在E7和E8单元格内计算笔试的平均分数和上机的平均分数 (先利用SUMIF函数分别求总分数,数值型,保留小数点后1位); (3)将工作表命名为:分数统计表
(4)选取"准考证号"和"分数"两列单元格区域的内容建立 "带数据标记的折线图",数据系列产生在"列", 在图表上方插入图表标题为"分数统计图",图例位置靠左, 为X坐标轴和Y坐标轴添加次要网格线, 将图表插入到当前工作表(分数统计表)内。 (5)保存工作簿文件。 2. 打开工作簿文件, 对工作表"图书销售情况表"内数据清单的内容按主要关键字 "图书名称"的升序次序和次要关键字"单价"的降序次序进行排序,对排序后的数据进行分类汇总,汇总结果显示在数据下方, 计算各类图书的平均单价,保存文件。 题号:15059 注意:下面出现的所有文件都必须保存在考生文件夹下。 提示:[答题]按钮只会自动打开题中任意一个文件。 在[.\考生文件夹\Excel数据处理\1]下,找到文件或exc文件:
实验设计与数据处理试题库
一、名词解释:(20分) 1. 准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度 2. 重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部 就叫一个区组 3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法: 对不能够明确区分自变数和因变数的两变数的相关关系的统计方法 4?总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体 5. 试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间 二、填空:(20分) 1. 资料常见的特征数有:(3空)算术平均数方差变异系数 2. 划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空) 3. 方差分析的三个基本假定是(3空)可加性正态性同质性 4. 要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照 5. 减小难控误差的原则是(3空)设置重复随机排列局部控制 6. 在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式 阶梯式 7. 正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法 8. 在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。 三、选择:(20分) 1试验因素对试验指标所引起的增加或者减少的作用,称作(C) A、主要效应 B、交互效应 C、试验效应 D、简单效应 2. 统计推断的目的是用(A) A、样本推总体 B、总体推样本 C、样本推样本 D、总体推总体 3. 变异系数的计算方法是(B) 4. 样本平均数分布的的方差分布等于(A) 5. t检验法最多可检验(C)个平均数间的差异显著性。 6. 对成数或者百分数资料进行方差分析之前,须先对数据进行(B) A、对数 B、反正弦 C、平方根 D、立方根 7. 进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B) A、相关系数 B、决定性系数 C、回归系数 D、变异系数 8. 进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A) 9. 进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B 10. 自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C) A、0.9054 B、0.0946 C、0.8197 D、0.0089 四、简答题:(15分) 1. 回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次 效益,利用回归方程进行预测预报: 计算相关系数,对相关系数进行检验 2. 一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。请画出田间排列示意图。(2分) 3. 田间试验中,难控误差有哪些?(4分)土壤肥力,小气候,相邻群体间的竞争差异,同一群体内个体间的竞争 差异。 4随即取样法包括哪几种方式?(3分)简单随机取样法分层随机取样法整群简单随机取样法 五、计算题(25分) 1. 研究变数x与y之间的关系,测得30组数据,经计算得出:x均值=10,y均值=20,l xy =60, l yy=300,r=0.6。根
实验设计与数据处理
《实验设计与数据处理》大作业 班级:环境17研 姓名: 学号: 1、 用Excel (或Origin )做出下表数据带数据点的折线散点图 余浊(N T U ) 加量药(mL) 总氮T N (m g /L ) 加量药(mL ) 图1 加药量与剩余浊度变化关系图 图2 加药量与总氮TN 变化关系图 总磷T P (m g /L ) 加量药(mL) C O D C r (m g /L ) 加量药(mL) 图3 加药量与总磷TN 变化关系图 图4 加药量与COD Cr 变化关系图 去除率(%) 加药量(mL)
图5 加药量与各指标去除率变化关系图
2、对离心泵性能进行测试的实验中,得到流量Q v 、压头H 和效率η的数据如表所示,绘制离心泵特性曲线。将扬程曲线和效率曲线均拟合成多项式(要求作双Y 轴图)。 η H (m ) Q v (m 3 /h) 图6 离心泵特性曲线 扬程曲线方程为:H=效率曲线方程为:η=+、列出一元线性回归方程,求出相关系数,并绘制出工作曲线图。 (1) 表1 相关系数的计算 Y 吸光度(A ) X X-3B 浓度(mg/L ) i x x - i y y - l xy l xx l yy R 10 -30 2800 20 -20 30 -10 40 ()() i i x x y y l R --= = ∑
50 10 60 20 70 30 平均值 40 吸光度 X-3B浓度(mg/L) 图7 水中染料活性艳红(X-3B )工作曲线 一元线性回归方程为:y=+ 相关系数为:R 2= (2) 代入数据可知: 样品一:x=样品二:x=、试找出某伴生金属c 与含量距离x 之间的关系(要求有分析过程、计算表格以及回归图形)。 表2 某伴生金属c 与含量距离x 之间的关系分析计算表 序号 x c lgx 1/x 1/c 1 2 2 3 3 4 4 5 5 7 6 8 7 10 1
试验设计与数据处理复习提纲
第0章 1 试验数据处理的主要作用 试验设计合理的规划试验,以通过较高效的试验方案获得更具代表性的数据 数据处理对试验数据进行分析研究,从而获得研究对象的变化规律,为生产和科研提供指导。 数据处理的具体作用: 第一章 2 真值的概念和特点 真值 某时刻和某一状态下,某量的可观值或实际值。 真值很多是位置的,但部分又是已知的。 3 平均值,尤其是算数平均值,加权平均值的概念。 平均值 科学实验中,经常将多次试验值得平均值作为真值的近似值。 (1) 算数平均值(arithmetic mean ) 同样试验条件下,如多次试验值服从正态分布,则算数平均值是这组等精度试验值中最佳或最可信赖的值。 (2) 加权平均值(weighted mean ) 若一组试验数据的精度或可靠度不一致,为了突出可靠性高的数值,可以采用加权平均值 权值的确定方法:①取试验值出现的频率ni/n ②若xi 为每组试验值的平均值,则权值为每组试验的次数 ③根据权与绝对误差的平方成反比确定 ④根据试验者的经验确定 4 误差的概念,包括绝对误差与相对误差。 判断影响结果的因素主次 优化试验或生产方案 确定试验因素与试验结果之间的近似函数关系 判断试验数据的可靠性 预测试验结果 控制试验结果 n n x i n ===121n x x x x i n ==+++= 121
5 误差的类型及产生的原因。 随机误差 系统误差 过失误差 6 精密度、正确度和准确度的概念。 1精密度定义:一定条件下多次试验值得彼此符合程度或一致程度。 正确度定义:大量试验结果的算数平均值与真值的一致程度。 准确度定义:反映系统误差与随机误差的综合 正确度:大量试验结果的算数平均值与真值的一致程度。 反映试验系统随机误差的大小 准确度:反映系统误差与随机误差的综合 7随机误差的检验法F 检验法。 1)检验两组实验数据精密度是否一致—双侧检验 (2)检验两组实验数据精密度优劣—单侧检验 a. 左侧检验 ① 取统计量为: ②给定显著性水平α ③查表确定临界值: ④ 判断:若 且 结论:S12相对S12两无显著减小。 b. 右侧检验 8 系统误差的t 检验法。 2122S F S = ① 取统计量为: ②给定显著性水平α ③查表确定临界值: 1212 (1,1) F n n α - --122(1,1) F n n α--④ 判断:若 121212 2 (1,1)F (1,1) F n n F n n αα- --<<--结论:则两组数据方差无显著差异。 2 122 S F S =112(1,1)F n n α---F 1<12F (1 ,1)F n n α<--12(1,1)F n n α--12F (1 ,1)F n n α<--
数据挖掘考试题库【最新】
一、填空题 1.Web挖掘可分为、和3大类。 2.数据仓库需要统一数据源,包括统一、统一、统一和统一数据特征 4个方面。 3.数据分割通常按时间、、、以及组合方法进行。 4.噪声数据处理的方法主要有、和。 5.数值归约的常用方法有、、、和对数模型等。 6.评价关联规则的2个主要指标是和。 7.多维数据集通常采用或雪花型架构,以表为中心,连接多个表。 8.决策树是用作为结点,用作为分支的树结构。 9.关联可分为简单关联、和。 10.B P神经网络的作用函数通常为区间的。 11.数据挖掘的过程主要包括确定业务对象、、、及知识同化等几个步 骤。 12.数据挖掘技术主要涉及、和3个技术领域。 13.数据挖掘的主要功能包括、、、、趋势分析、孤立点分析和偏 差分析7个方面。 14.人工神经网络具有和等特点,其结构模型包括、和自组织网络 3种。 15.数据仓库数据的4个基本特征是、、非易失、随时间变化。 16.数据仓库的数据通常划分为、、和等几个级别。 17.数据预处理的主要内容(方法)包括、、和数据归约等。 18.平滑分箱数据的方法主要有、和。 19.数据挖掘发现知识的类型主要有广义知识、、、和偏差型知识五种。 20.O LAP的数据组织方式主要有和两种。 21.常见的OLAP多维数据分析包括、、和旋转等操作。 22.传统的决策支持系统是以和驱动,而新决策支持系统则是以、建 立在和技术之上。 23.O LAP的数据组织方式主要有和2种。 24.S QL Server2000的OLAP组件叫,OLAP操作窗口叫。 25.B P神经网络由、以及一或多个结点组成。 26.遗传算法包括、、3个基本算子。 27.聚类分析的数据通常可分为区间标度变量、、、、序数型以及混合 类型等。 28.聚类分析中最常用的距离计算公式有、、等。 29.基于划分的聚类算法有和。
试验设计与数据处理
试验设计与数据处理方法总述及总结 王亚丽 (数学与信息科学学院 08统计1班 081120132) 摘要:实验设计与数据处理是一门非常有用的学科,是研究如何经济合理安排 试验可以解决社会中存在的生产问题等,对现实生产有很重要的指导意义。因此本文根据试验设计与数据处理进行了总述与总结,以期达到学习、理解、掌握的以及灵活运用的目的。 1 试验设计与数据处理基本知识总述 1.1试验设计与数据处理的基本思想 试验设计与数据处理是数理统计学中的一个重要分支。它是以概率论、数理统计及线性代数为理论基础,结合一定的专业知识和实践经验,研究如何经济、合理地安排实验方案以及系统、科学地分析处理试验结果的一项科学技术,从而解决了长期以来在试验领域中,传统的试验方法对于多因素试验往往只能被动地处理试验数据,而对试验方案的设计及试验过程的控制显得无能为力这一问题。 1.2试验设计与数据处理的作用 (1)有助于研究者掌握试验因素对试验考察指标影响的规律性,即各因素的水平改变时指标的变化情况。 (2)有助于分清试验因素对试验考察指标影响的大小顺序,找出主要因素。(3)有助于反映试验因素之间的相互影响情况,即因素间是否存在交互作用。(4)能正确估计和有效控制试验误差,提高试验的精度。 (5)能较为迅速地优选出最佳工艺条件(或称最优方案),并能预估或控制一定条件下的试验指标值及其波动范围。 (6)根据试验因素对试验考察指标影响规律的分析,可以深入揭示事物内在规律,明确进一步试验研究的方向。
1.3试验设计与数据处理应遵循的原则 (1)重复原则:重可复试验是减少和估计随机误差的的基本手段。 (2)随机化原则:随机化原则可有效排除非试验因素的干扰,从而可正确、无偏地估计试验误差,并可保证试验数据的独立性和随机性。 (3)局部控制原则:局部控制是指在试验时采取一定的技术措施方法减少非试验因素对试验结果的影响。用图形表示如下: 2试验设计与数据处理方法总述和总结 2.1方差分析 (1)概念:方差分析是用来检验两个或两个以上样本的平均值差异的显著程度。并由此判断样本究竟是否抽自具有同一均值的总体。 (2)优点:方差分析对于比较不同生产工艺或设备条件下产量、质量的差异,分析不同计划方案效果的好坏和比较不同地区、不同人员有关的数量指标差异是否显著时,是非常有用的。 (3)缺点:对所检验的假设会发生错判的情况,比如第一类错误或第二类错误的发生。 (4)基本原理:方差分析的基本思路是一方面确定因素的不同水平下均值之间的方差,把它作为对由所有试验数据所组成的全部总体的方差的第一个估计值;另一方面再考虑在同一水平下不同试验数据对于这一水平的均值的方差,由此计算出对由所有试验数据所组成的全部数据的总体方差的第 二个估计值。比较上述两个估计值,如果这两个方差的估计值比较接近就说明因素的不同水平下的均值间的差异并不大,就接受零假设;否则,说明因素的不同水平下的均值间的差异比较大。
实验设计与数据处理试题库
一、名词解释:(20分) 1.准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度 2.重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部就叫一个区组 3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法: 对不能够明确区分自变数和因变数的两变数的相关关系的统计方法 4.总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体 5.试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间 二、填空:(20分) 1.资料常见的特征数有:(3空)算术平均数方差变异系数 2.划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空) 3.方差分析的三个基本假定是(3空)可加性正态性同质性 4.要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照 5.减小难控误差的原则是(3空)设置重复随机排列局部控制 6.在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式阶梯式 7.正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法 8.在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。 三、选择:(20分) 1试验因素对试验指标所引起的增加或者减少的作用,称作(C) A、主要效应 B、交互效应 C、试验效应 D、简单效应 2.统计推断的目的是用(A) A、样本推总体 B、总体推样本 C、样本推样本 D、总体推总体 3.变异系数的计算方法是(B) 4.样本平均数分布的的方差分布等于(A) 5.t检验法最多可检验(C)个平均数间的差异显著性。 6.对成数或者百分数资料进行方差分析之前,须先对数据进行(B) A、对数 B、反正弦 C、平方根 D、立方根 7.进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B) A、相关系数 B、决定性系数 C、回归系数 D、变异系数 8.进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A) 9.进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B 10.自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C) A、0.9054 B、0.0946 C、0.8197 D、0.0089 四、简答题:(15分) 1.回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次效益,利用回归方程进行预测预报: 计算相关系数,对相关系数进行检验 2.一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。请画出田间排列示意图。(2分) 3.田间试验中,难控误差有哪些?(4分)土壤肥力,小气候,相邻群体间的竞争差异,同一群体内个体间的竞争差异。 4随即取样法包括哪几种方式?(3分)简单随机取样法分层随机取样法整群简单随机取样法 五、计算题(25分) 1.研究变数x与y之间的关系,测得30组数据,经计算得出:x均值=10,y均值=20,l xy=60, l yy=300,r=0.6。根据所得数据建立直线回归方程。(5分)a=2 b=1.8 y=2+1.8 x 2.完成下列方差分析表,计算出用LSR法进行多重比较时各类数据填下表:
数据处理与实验设计小论文
上海大学2014~2015学年秋季学期研究生课程考试课程名称:数据处理与实验设计课程编号:11S009003论文题目:正交实验在锂离子电极材料制备中的应用 研究生姓名:李艳峰学号:14722191 论文评语: 成绩:任课教师: 评阅日期:
正交实验在锂离子电极材料制备中的应用 李艳峰 (上海大学环境与化学工程学院,上海200444) 摘要:锂源、反应温度、反应时间和锂钛摩尔比是影响锂离子电极负极材料Li4Ti5O12制备的重要因素,本文利用正交实验L9 (34)的方法对液相法制备Li4Ti5O12的各种影响因素进行进一步优化,从而得到最优水平组合,并对各种影响因素进行权重分析。最后,利用正交实验确定了液相法制备Li4Ti5O12的最佳工艺:烧结温度为750℃,烧结时间为8h,LiOH·H2O 为锂源,原料中锂钛摩尔比为0.85。 关键词:正交实验设计;液相法;影响因素; 中图分类号:O242.1文献标识码:A The application of orthogonal experimental design on liquid method in the production of Lithium-ion electrode materials Yanfeng Li (School of Environmental and Chemical Engineering, Shanghai University, Shanghai 200444, China) Abstract:lithium source, reaction temperature, reaction time and lithium titanium molar ratio are important factors for the preparation of Li4Ti5O12 conditions of liquid method. Based on the single factor experiment, this study use L9 (34) orthogonal experiments to optimized the removal of the preparation of Li4Ti5O12 of liquid method. The optimal technological parameters of solution method determined by the orthogonal experiment were as follows: sintering temperature was 750℃, sintering time was 8 h, the lithium resource was LiOH·H2O and the mole ration of Li to Ti was 0.85. Key words: Orthogonal experimental design;Liquid method; Factors;
试验设计与数据处理课程论文
课 程 论 文 课程名称试验设计与数据处理 专业2012级网络工程 学生姓名孙贵凡 学号201210420136 指导教师潘声旺职称副教授
成绩 科学研究与数据处理 学院信息科学与技术学院专业网络工程姓名孙贵凡学号:201210420136 摘要:《实验设计与数据处理》这门课程列举典型实例介绍了一些常用的实验设计及实验数据处理方法在科学研究和工业生产中的实际应用,重点介绍了多因素优化实验设计——正交设计、回归分析方法以对目标函数进行模型化处理。其适于工艺、工程类本科生使用,尤其适用于化学化工、矿物加工、医学和环境学等学科的本科生使用。其对行实验设计可提供很大的帮助,也可供广大分析化学工作者应用。关键字:优化实验设计; 标函数进行模型化处理; 正交设计; 回归分析方法 1 引言 实验是一切自然科学的基础,科学界中大多数公式定理是由试验反复验证而推导出来的。只有经得起试验验证的定理规律才具有普遍实用性。而科学的试验设计是利用自己已有的专业学科知识,以大量的实践经验为基础而得出的既能减少试验次数,又能缩短试验周期,从而迅速找到优化方案的一种科学计算方法,就必然涉及到数据处理,也只有对试验得出的数据做出科学合理的选择,才能使实验结果更具说服力。实验设计与数据处理在水处理中发挥着不可估量的作用,通过科学合理的实验设计过程加上严谨规范的数据处理方法,可以使水处理原理,内在规律性被很好的发现,从而更好的应用于生产实践。 2 材料与方法 2.1 供试材料 1. 论文所围绕的目标和假设 研究的目标就是实验的目的,我们设计了这个实验是想来做什么以及想得到什么样的结论。要正确的识别问题和陈述问题,这些需要专业知识和大量的阅读文献综述等方法来获得我们所要提出的问题。需要对某一个具体的问题,并且对这个具体的问题提出假设。如水处理中混凝剂的最佳投加量,混凝剂的最佳投加量有一个适宜的PH值范围。
大数据技术及应用题库
大数据技术及应用题库单选题: 1 从大量数据中提取知识的过程通常称为(A)。 a. . 数据挖掘 b. . 人工智能 c. . 数据清洗 d. . 数据仓库 2 下列论据中,能够支撑“大数据无所不能”的观点的是( A )。 A、互联网金融打破了传统的观念和行为 B、大数据存在泡沫 C、大数据具有非常高的成本 D、个人隐私泄露与信息安全担忧 3 数据仓库的最终目的是(D)。 a. . 收集业务需求 b. . 建立数据仓库逻辑模型 c. . 开发数据仓库的应用分析 d. . 为用户和业务部门提供决策支持 4 大数据处理技术和传统的数据挖掘技术最大的区别是(A)。 a. . 处理速度快(秒级定律)
b. . 算法种类更多 c. . 精度更高 d. . 更加智能化 5 大数据的起源是( C )。 a. . 金融 b. . 电信 c. . 互联网 d. . 公共管理 6 大数据不是要教机器像人一样思考。相反,它是( A )。 a. . 把数学算法运用到海量的数据上来预测事情发生的可能性 b. . 被视为人工智能的一部 c. . 被视为一种机器学习 d. . 预测与惩罚 7 人与人之间沟通信息、传递信息的技术,这指的是(D)。 a. . 感测技术 b. . 微电子技术 c. . 计算机技术 d. . 通信技术
8 数据清洗的方法不包括(D)。 a. . 缺失值处理 b. . 噪声数据清除 c. . 一致性检查 d. . 重复数据记录处理 9. 下列关于舍恩伯格对大数据特点的说法中,错误的是(D) A. 数据规模大 B. 数据类型多样 C. 数据处理速度快 D. 数据价值密度高 10规模巨大且复杂,用现有的数据处理工具难以获取、整理、管理以及处理的数据,这指 的是(D)。 a. . 富数据 b. . 贫数据 c. . 繁数据 d. . 大数据 1大数据正快速发展为对数量巨大、来源分散、格式多样的数据进行采集、存储和关联分 析,从中发现新知识、创造新价值、提升新能力的(D)。 a. . 新一代信息技术 b. . 新一代服务业态 c. . 新一代技术平台 d. . 新一代信息技术和服务业态
实验设计与数据处理
试验设计与数据处理 学院 班级 学号 学生姓名 指导老师
第一章 4、 相对误差18.20.1%0.0182x mg mg ?=?= 故100g 中维生素C 的质量范围为:±。 5、1)、压力表的精度为级,量程为, 则 max 0.2 1.5%0.00333 0.375 8 R x MPa KPa x E x ?=?==?=== 2)、1mm 的汞柱代表的大气压为, 所以 max 2 0.1330.133 1.662510 8 R x KPa x E x -?=?===? 3)、1mm 水柱代表的大气压为gh ρ,其中2 9.8/g m s = 则: 3max 33 9.8109.810 1.22510 8 R x KPa x E x ---?=???===? 6. 样本测定值 算数平均值 几何平均值 调和平均值 标准差s 标准差σ 样本方差S 2 总体方差σ2 算术平均误差△ 极差R 7、S ?2=,S ?2= F =S ?2/ S ?2== 而F ()=,= 所以F ()< F < 两个人测量值没有显著性差异,即两个人的测量方法的精密度没有显著性差异。 |||69.947|7.747 6.06 p p d x =-=>
分析人员A分析人员B 8样本方差1 8样本方差2 10Fa值 104F值 6 68 4705 6 6 88 8.旧工艺新工艺 %% %% %% %% %% %% %% %% %% % % % % t-检验: 双样本异方差假设 变量 1变量 2 平均 方差 观测值139假设平均差0 df8 t Stat-38. P(T<=t) 单尾0 t 单尾临界 P(T<=t) 双尾0 t 双尾临界 F-检验双样本方差分析
测绘数据处理与数字成图复习题
复习思考题 1.与传统模拟测图相比较,数字测图具有哪些特点? 答:数字测图的实质是全解析、机助成图。 a、使大比例尺测图走向自动化 b、数字测图使得大比例尺测图走向数字化 c、提高了测图精度 d、数字测图促进了大比例尺的发展、更新 1. 大比例尺测图自动化:野外测量自动记录、自动结算处理,自动成图、绘图,并提供可供处理的数字地图。效率高、劳动强度小。 2. 大比例尺测图的数字化:数字地形信息可以传输、处理和多用户共享;可自动提取点位坐标、距离、方位、面积等;可供工程CAD(计算机辅助设计)使用;可供GIS建库使用,可绘制各类专题地图;可进行局部更新,保持地图的现势性。 3.模拟测方法的比例尺精度决定了图的最高精度。数字地形图无损地体现了外业测量的精度。 4. 地面数字测图的图根控制测量与碎部测量可同时进行。 5. 地面数字测图在测区内可不受图幅的限制。 6. 地面数字测图必须有足够的特征点坐标才能绘制地物符号。 2.根据空间数据来源以及采用仪器的不同,目前数字测图的主要作业方法有哪些?各适用于什么情况?并谈谈你对各种作业方法未来发展的展望? 答:(1)全站仪地面数据采集,适用于城市大比例尺数字测图 (2)既有模拟地形图数字化。这种方法适用于计算机存档、图纸更新、修测,任意比例尺地形图的测制 (3)数字摄影测量。适合大面积中、大比例尺地形图测制和更新,也将是城市GIS数据获取的主要方法。 (4)GPS、RTK地面数据采集。适合大比例尺地形图的测制。 3.什么是数字测图系统?试根据你的认识绘出数字测图系统生产工艺流程框图? 答:依托计算机系统,在外连输入输出设备软、硬件的支持下,以数字测图软件为核心对地形空间数据进行采集、输入、编辑、成图、管理、输出的测绘系统。 4.什么是数字地形图?与纸质模拟地形图相比较,数字地形图具有哪些特点? 答:数字地形图是根据地形图制图表示的要求,将地形要素进行计算机处理后,以矢量或栅格数据结构组织、储存并可以图形方式输出的数字产品。 特点:(1)真实三维坐标数字化存储在磁介质中 (2)地形要素分层组织与管理 (3)突破图纸大小限制,可以自然界线分区存储 (4)易于复制分发 5.有同学说:“在数字地形图中地形要素的空间数据是以真实坐标存储的,因而进入数字测图时代不再存在比例尺和比例尺精度的概念了。”试谈谈你对这句话的看法? 答:数字测图也离不开比例尺,测图过程中地物的取舍就必须考虑比例尺,不同的比例尺地面表达的程度不一样,只是说在室内成图时比例尺比较容易修改而已。 6.有同学说:“进入数字测图时代,再大测区范围的地形信息都可以存储在一个数字地形图中,因而不再需要地形图的分幅与编号了。”试谈谈你对这句话的看法? 答:为了不重测、漏测,就需要将地面按一定的规律分成若干块,为了科学的反映各种比例尺地形图之间的关系和相同比例尺地图的拼接关系,为了能迅速查找到所需的某地区某种比例尺的地图,需要将地形图按一定规律进行编号。 7.地形要素具有哪些基本特征?在数字地形图中是如何存储和组织这些特征信息的? 答:空间位置、属性关系、连接关系。 8.什么是图层?对数字地形图分层的目的和作用是什么?结合你的认识制定一套1:500、1:1000和1:2000数字地形图分层方案? 答:图层:在电子地图中,图层是地形特征相似的地形要素组成的逻辑或物理集合。 作用:(1)图形数据库图形组织与管理的一种技术,通过控制图层的特性来控制图形对象的显示、输出,以提高图形处理的效率 (2)更重要的是适应数据管理的需要。 9.对地形要素进行编码的目的和作用是什么?编码设计时应遵循哪些原则?在基于CAD的数字测图软件中实现编码管理的方案有哪些? 答:编码的目的:便于数字测图软件及GIS软件识别与处理(采集、检索、分析、输出和数据交换)。 原则:规范性,适用性,唯一性,稳定性,可扩展性。
实验设计与数据处理课后答案
《试验设计与数据处理》 专业:机械工程班级:机械11级专硕学号:S110805035 姓名:赵龙 第三章:统计推断 3-13 解:取假设H0:u1-u2≤0和假设H1:u1-u2>0用sas分析结果如下:Sample Statistics Group N Mean Std. Dev. Std. Error ---------------------------------------------------- x 8 0.231875 0.0146 0.0051 y 10 0.2097 0.0097 0.0031 Hypothesis Test Null hypothesis: Mean 1 - Mean 2 = 0 Alternative: Mean 1 - Mean 2 ^= 0 If Variances Are t statistic Df Pr > t ---------------------------------------------------- Equal 3.878 16 0.0013 Not Equal 3.704 11.67 0.0032 由此可见p值远小于0.05,可认为拒绝原假设,即认为2个作家所写的小品文中由3个字母组成的词的比例均值差异显著。 3-14 解:用sas分析如下: Hypothesis Test Null hypothesis: Variance 1 / Variance 2 = 1 Alternative: Variance 1 / Variance 2 ^= 1 - Degrees of Freedom - F Numer. Denom. Pr > F ---------------------------------------------- 2.27 7 9 0.2501 由p值为0.2501>0.05(显著性水平),所以接受原假设,两方差无显著差异 第四章:方差分析和协方差分析 4-1 解: Sas分析结果如下: Dependent Variable: y Sum of Source DF Squares Mean Square F Value Pr > F
试验设计与数据处理试验报告
试验设计与数据处理试验报告 正交试验设计 1.为了通过正交试验寻找从某矿物中提取稀土元素的最优工艺条件,使稀土元素提取率最高,选取的水平如下:
需要考虑交互作用有A×B,A×C,B×C,如果将A,B,C分别安排在正交表L8(2)的 1,2,4列上,试验结果(提取量/ml)依次是1.01,,1,33,1,13,1.06,,1.03,0.08,,0.76,0.56. 试用方差分析法(α=0.05)分析实验结果,确定较优工艺条件 解:(1)列出正交表L8(27)和实验结果,进行方差分析。 试验号 A B A×B C A×C B×C 空号提取量(ml) 1 1 1 1 1 1 1 1 1.01 2 1 1 1 2 2 2 2 1.33 3 1 2 2 1 1 2 2 1.13 4 1 2 2 2 2 1 1 1.06 5 2 1 2 1 2 1 2 1.03 6 2 1 2 2 1 2 1 0.8 7 2 2 1 1 2 2 1 0.76 8 2 2 1 2 1 1 2 0.56 K1 4.53 4.17 3.66 3.93 3.5 3.66 3.63 K2 3.15 3.51 4.02 3.75 4.18 4.02 4.05 k1 2.265 2.085 1.83 1.965 1.75 1.83 1.815 k2 1.575 1.755 2.01 1.875 2.09 2.01 2.025 极差R 1.38 0.66 0.36 0.18 0.68 0.36 0.42 因素主次 A A×C B A×B B×C 优选方案 A1B1C1 SS J 0.23805 0.05445 0.0162 0.00405 0.0578 0.0162 0.02205 Q 7.7816 总和T 7.68 P=T^2/n 7.3728 SS T 0.4088 差异源SS df MS F 显著性 A 0.23805 1 0.23805 19.5925 9259 * B 0.05445 1 0.05445 4.48148 1481 A*B 0.0162 1 0.0162 1.33333 3333 C 0.00405 1 0.00405 0.33333 3333 A*C 0.0578 1 0.0578 4.75720 1646
数据的试题及答案
数据的试题及答案 1、当前大数据技术的基础是由(C)首先提出的;A:微软B:百度C:谷歌D:阿里巴巴; 2、大数据的起源是(C);A:金融B:电信C:互联网D:公共管理; 3、根据不同的业务需求来建立数据模型,抽取最有意;A:数据管理人员B:数据分析员C:研究科学家D:; 4、(D)反映数据的精细化程度,越细化的数据,价;A:规模B:活性C:关联度D:颗粒度; 5、数据清洗的方法不包 1、当前大数据技术的基础是由( C)首先提出的。(单选题,本题2分) A:微软 B:百度 C:谷歌 D:阿里巴巴 2、大数据的起源是(C )。(单选题,本题2分) A:金融 B:电信 C:互联网 D:公共管理 3、根据不同的业务需求来建立数据模型,抽取最有意义的向量,决定选取哪种方法的数据分析角色人员是( C)。(单选题,本题2分) A:数据管理人员 B:数据分析员 C:研究科学家 D:软件开发工程师 4、(D )反映数据的精细化程度,越细化的数据,价值越高。(单选题,本题2分) A:规模 B:活性 C:关联度 D:颗粒度 5、数据清洗的方法不包括( D)。(单选题,本题2
A:缺失值处理 B:噪声数据清除 C:一致性检查 D:重复数据记录处理 6、智能健康手环的应用开发,体现了( D)的数据采集技术的应用。(单选题,本题2分) A:统计报表 B:网络爬虫 C:API接口 D:传感器 7、下列关于数据重组的说法中,错误的是( A)。(单选题,本题2分) A:数据重组是数据的重新生产和重新采集 B:数据重组能够使数据焕发新的光芒 C:数据重组实现的关键在于多源数据融合和数据集成D:数据重组有利于实现新颖的数据模式创新 8、智慧城市的构建,不包含( C)。(单选题,本题2分) A:数字城市 B:物联网 C:联网监控 D:云计算 9、大数据的最显著特征是( A)。(单选题,本题2分) A:数据规模大 B:数据类型多样 C:数据处理速度快 D:数据价值密度高 10、美国海军军官莫里通过对前人航海日志的分析,绘制了新的航海路线图,标明了大风与洋流可能发生的地点。这体现了大数据分析理念中的(B )。(单选题,本题
实验设计与数据处理
Fisher传统的试验设计被誉为第一个里程碑。正交表的构造和开发是第二个里程碑,日本学者田口玄一开开发的SN比试验设计则称为第三个里程碑。 第一章试验设计 1.试验包括:验证性试验、探索性试验。 2.试验设计的要求:效率、精度。(效率由设计保证,精度由数据处理、分析保证。) 3.试验方案设计的4个基本要素:目标、目标函数、因素、水平。 4.目标:进行试验所要达到的目的。 目标可以定量也可定性。 5.目标函数:表示目标的函数Y(x)。有显示目标函数、隐式目标函数。 6.因素:对目标产生影响的自变量或试验条件,也称因子。分为可控因素与不可控因素。 7.水平:每个因素所处的状态,也称位级。 8.选取因素的原则:抓住主要因素及多因素之间的交互作用;抓住非主要因素,在试验中保持不变,消除其干扰。因素用大写字母表示。
9.按所取因素的多少,可把试验分为单因素试验、两因素试验、多因素试验。 10.交互作用:就是这些因素在同时改变水平时,其效果会超过单独改变某一因素水平时的效果。 11.水平的选取原则:等间距;三水平为宜;是具体的;技术上可行。 12.误差包括:系统误差、随机误差。 13.费希尔Fisher三原则(作用:进行误差控制):重复测试、随机化、区组控制。 14.重复测试,作用:减小误差。 15.随机化是使系统误差转化为偶然误差的有效方法。原则:进行随机化,使其转化为随机误差。 16.区组控制,原则:机会均等,公平原则。区组控制原则实质上是机会均等原则,实行区组控制,可使设备条件由存在差异转化为没有差异,在区组控制中也把区组当做因素来对待,并称之为区组因素。 17.试验设计法和现行做法的不同点:对于不能实现控制的环境条件及未知原因对试验数据产生的干扰和影响程度,可以做出客观
《实验设计与数据处理》教学大纲
《实验设计与数据处理》教学大纲 (Experiment Design and Data Analysis) 一、基本信息 课程代码: 学分:2 总课时:32 课程性质:硕士专业必修课 适用专业:环境工程 先修课程:高等数学、概率论、线性代数 二、本课程教学目的和任务 本课程是环境工程硕士生的专业课。数据分析作为一种研究手段,主要是通过从系统设计、参数设计和允许误差设计入手,运用一定的物质手段,在人为控制或模拟自然现象的条件下,使环境过程以纯粹的、典型的形式表现出来,以便进行观察、研究、探索环境本质及其规律,使试验设计建立在统计理论基础之上,试验设计与数据处理相并重。 三、大纲的教学体系 以课堂教学和上机操作为主,采用多媒体教学,辅以课堂讨论、专题讲解等内容。主要开展环境试验的优化设计、环境数据的展示分析、环境数据的比较分析、环境数据的关系分析、环境数据的类别分析、环境数据的序列分析、环境数据的序列分析、正交试验的数据分析、回归分析、数据分析软件学习等内容。 四、教学内容及要求 第一章环境实验设计与数据处理概论 要求掌握(1)环境试验研究的目的与任务;(2)环境试验研究的类型;(3)环境试验研究的程序 重点内容:准确理解环境试验研究类型的区分;理解环境试验研究的设计步骤,以及试验设计的基本要求。 难点内容:理解环境试验因子、水平、处理、重复、响应指标等要素,了解准确度、精密度等概念。 第二章环境试验的优化设计 要求掌握(1)非均分设计;(2)黄金分割设计;(3)纵横对折设计;(4)平行线设计;(5)环境试验的正交设计;(6)环境试验点均匀设计;熟悉单因子、双因子优选设计的基本方法,熟悉正交表的定义和类型;了解均匀设计与正交设计的区别。 重点内容:正交试验的设计步骤,常见的正交设计运用方法,均匀设计的步骤 难点内容:了解分数法设计;旋升设计;逐步提高设计;陡度法设计;单纯形法设计等。 第三章环境数据的展示分析