卡方检验结果分析
样本的基本信息:
一、样本总数56
二、性别:男27人,女29人
三、年级:大二
四、民族:汉族25人,少数民族31人
五、学院:社心学院16人,管理学院12人,旅历学院17人,计科学院11人
◆性别与其它因素的关系:
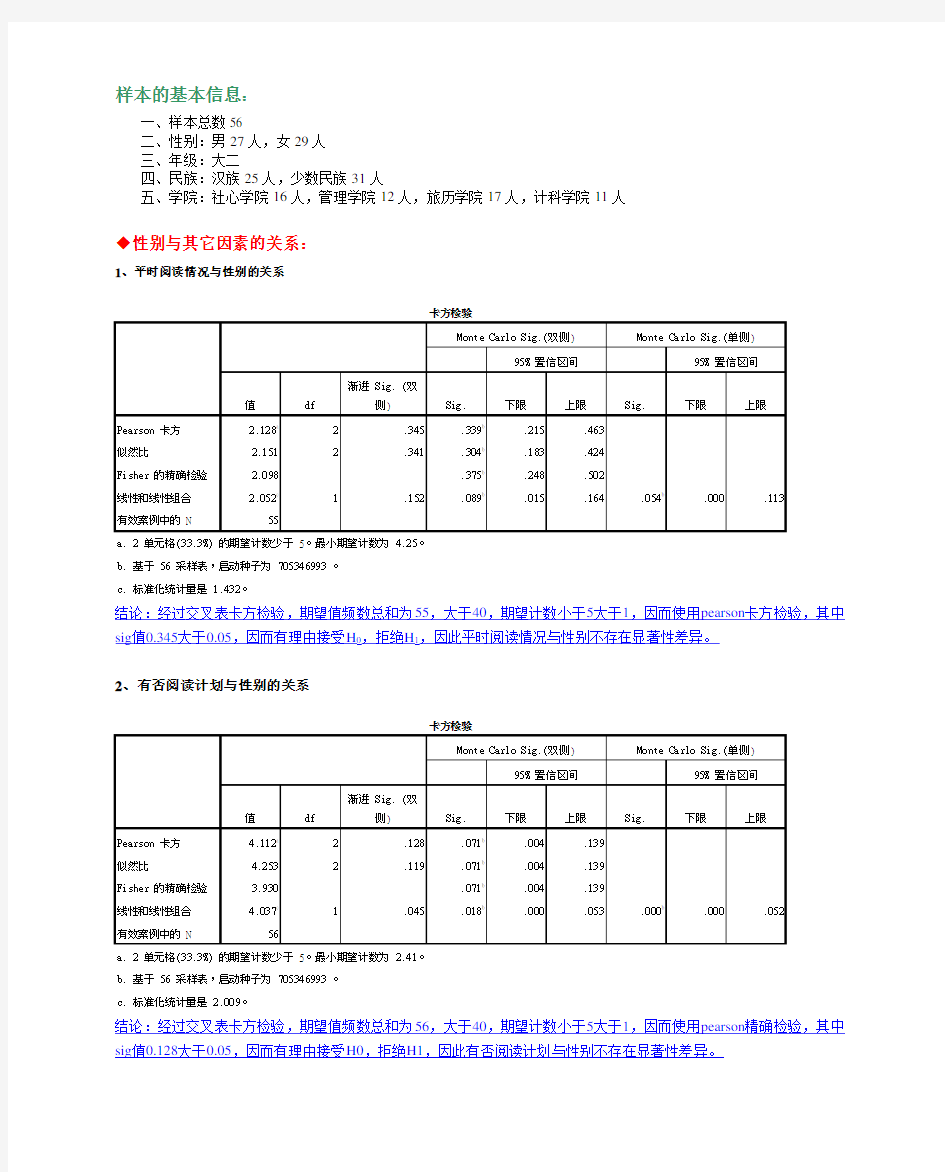
1、平时阅读情况与性别的关系
结论:经过交叉表卡方检验,期望值频数总和为55,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.345大于0.05,因而有理由接受H0,拒绝H1,因此平时阅读情况与性别不存在显著性差异。
2、有否阅读计划与性别的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson精确检验,其中sig值0.128大于0.05,因而有理由接受H0,拒绝H1,因此有否阅读计划与性别不存在显著性差异。
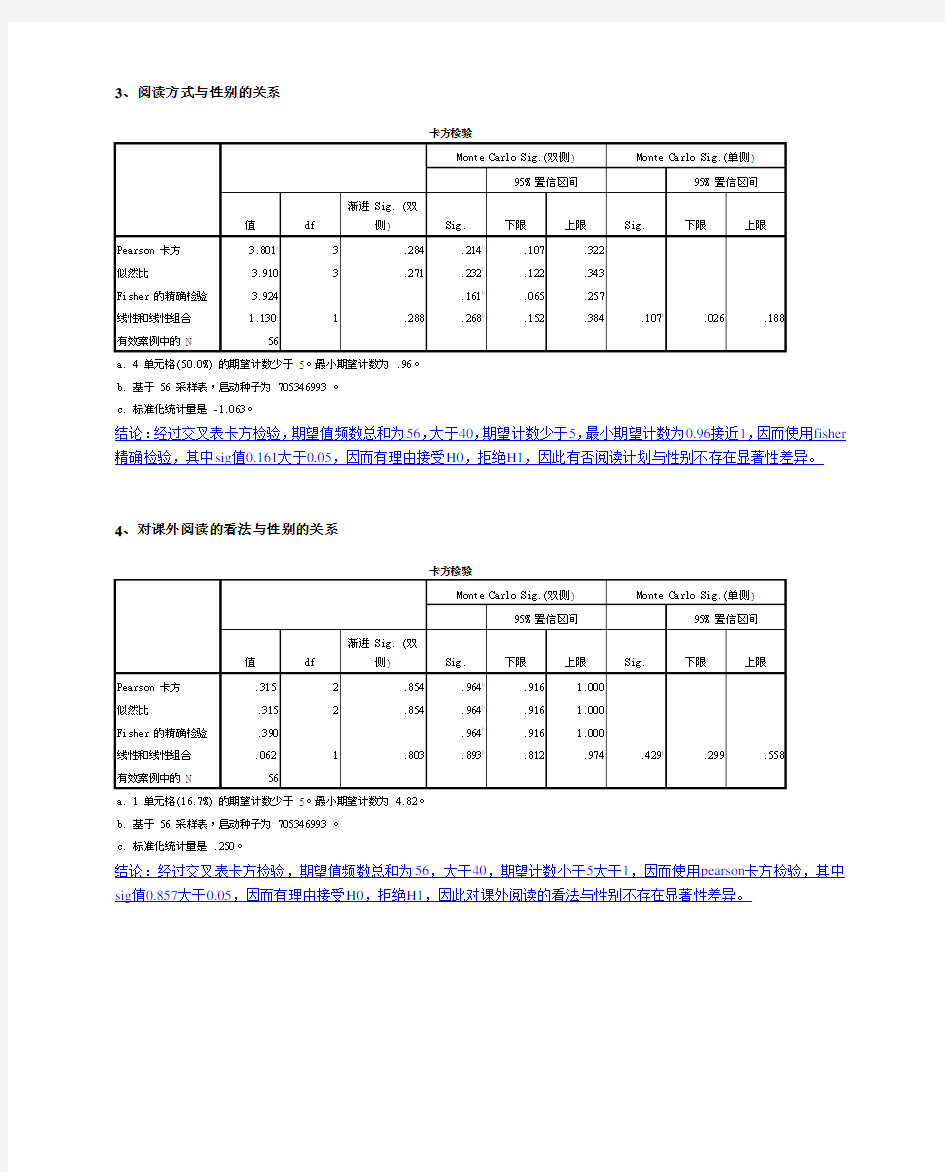
3、阅读方式与性别的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数少于5,最小期望计数为0.96接近1,因而使用fisher 精确检验,其中sig值0.161大于0.05,因而有理由接受H0,拒绝H1,因此有否阅读计划与性别不存在显著性差异。
4、对课外阅读的看法与性别的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.857大于0.05,因而有理由接受H0,拒绝H1,因此对课外阅读的看法与性别不存在显著性差异。
5、阅读量的趋势与性别的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.048小于0.05,因而有理由拒绝H0,接受H1,因此阅读量趋势与性别存在显著性差异。
结论:经过交叉表卡方检验,期望值频数总和为55,大于40,期望计数大于5,因而使用pearson卡方检验,其中sig值0.139大于0.05,因而有理由接受H0,拒绝H1,因此是否有足够时间进行课外阅读与性别不存在显著性差异。
◆民族与其它因素的关系:
结论:经过交叉表卡方检验,期望值频数总和为55,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.336大于0.05,因而有理由接受H0,拒绝H1,因此平时阅读情况与民族不存在显著性差异。
2、有否阅读计划与民族的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.492大于0.05,因而有理由接受H0,拒绝H1,因此有否阅读计划与民族不存在显著性差异。
3、阅读方式的偏好与民族的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5,最小期望计数为0.89接近1,因而使用fisher 精确检验,其中sig值0.339大于0.05,因而有理由接受H0,拒绝H1,因此阅读方式的偏好与民族不存在显著性差异。
4、对进行课外阅读的看法与民族的关系
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.873大于0.05,因而有理由接受H0,拒绝H1,因此对进行课外阅读的看法与民族不存在显著性差异。
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.045小于0.05,因而有理由拒绝H0,接受H1,因此阅读量趋势在汉族和少数民族中存在显著性差异。
结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.396大于0.05,因而有理由接受H0,拒绝H1,因此是否有足够的时间与民族不存在显著性差异。
【实验报告】SPSS相关分析实验报告
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
sss非参数检验K多个独立样本检验KruskalWallis检验案例解析
spss-非参数检验-K多个独立样本检验( Kruskal-Wallis检验)案例解析2011-09-19 15:09 最近经常失眠,好痛苦啊!大家有什么好的解决失眠的方法吗?希望知道的能够告诉我,谢谢啦,今天和大家一起探讨和分下一下SPSS-非参数检验--K个独立样本检验( Kruskal-Wallis检验)。 还是以SPSS教程为例: 假设:HO: 不同地区的儿童,身高分布是相同的 H1:不同地区的儿童,身高分布是不同的 不同地区儿童身高样本数据如下所示: 提示:此样本数为4个(北京,上海,成都,广州)每个样本的样本量(观察数)都为5个
即:K=4>3 n=5, 此时如果样本逐渐增大,呈现出自由度为K-1的平方的分布,(即指:卡方检验) 点击“分析”——非参数检验——旧对话框——K个独立样本检验,进入如下界面: 将“周岁儿童身高”变量拖入右侧“检验变量列表”内,将“城市(CS)变量” 拖入“分组变量”内,点击“定义范围” 输入“最小值”和“最大值”(这里的变量类型必须为“数字型”)如果不是数字型,必须要先定义或者重新编码。 在“检验类型”下面选择“秩和检验”( Kruskal-Wallis检验)点击确定 运行结果如下所示:
对结果进行分析如下: 1:从“检验统计量a,b”表中可以看出:秩和统计量为:13.900 自由度为:3=k-1=4-1 下面来看看“秩和统计量”的计算过程,如下所示: 假设“秩和统计量”为 kw 那么:
其中:n+1/2 为全体样本的“秩平均” Ri./ni 为第i个样本的秩平均 Ri.代表第i个样本的秩和, ni代表第i个样本的观察数) 最后得到的公式为: 北京地区的“秩和”为:秩平均*观察数(N) = 14.4*5=72 上海地区的“秩和”为:8.2*5=41 成都地区的“秩和”为:15.8*5=79 广州地区的“秩和”为:3.6*5=18
SPSS非参数检验之一卡方检验
SPSS 中非参数检验之一:总体分布的卡方(Chi-square )检验 在得到一批样本数据后,人们往往希望从中得到样本所来自的总体的分布形态是否和某种特定分布相拟合。这可以通过绘制样本数据直方图的方法来进行粗略的判断。如果需要进行比较准确的判断,则需要使用非参数检验的方法。其中总体分布的卡方检验(也记为χ2检验)就是一种比较好的方法。 一、定义 总体分布的卡方检验适用于配合度检验,是根据样本数据的实际频数推断总 体分布与期望分布或理论分布是否有显著差异。它的零假设H0:样本来自的总体分布形态和期望分布或某一理论分布没有显著差异。 总体分布的卡方检验的原理是:如果从一个随机变量尤中随机抽取若干个观察样本,这些观察样本落在X 的k 个互不相交的子集中的观察频数服从一个多项分布,这个多项分布当k 趋于无穷时,就近似服从X 的总体分布。 因此,假设样本来自的总体服从某个期望分布或理论分布集的实际观察频数同时获得样本数据各子集的实际观察频数,并依据下面的公式计算统计量Q () 2 1 k i i i i O E Q E =-=∑ 其中,Oi 表示观察频数;Ei 表示期望频数或理论频数。可见Q 值越大,表示观察频数和理论频数越不接近;Q 值越小,说明观察频数和理论频数越接近。SPSS 将自动计算Q 统计量,由于Q 统计量服从K-1个自由度的X 平方分布,因此SPSS 将根据X 平方分布表给出Q 统计量所对应的相伴概率值。 如果相伴概率小于或等于用户的显著性水平,则应拒绝零假设H0,认为样本来自的总体分布形态与期望分布或理论分布存在显著差异;如果相伴概率值大
于显著性水平,则不能拒绝零假设HO,认为样本来自的总体分布形态与期望分布或理论分布不存在显著差异。
非参数检验卡方检验实验报告
大理大学实验报告 课程名称生物医学统计分析 实验名称非参数检验(卡方检验) 专业班级 姓名 学号 实验日期 实验地点 2015—2016学年度第 2 学期
Fisher 的精确检验:精确概率法计算的卡方值(用于理论数E<5)。 不同的资料应选用不同的卡方计算方法。 例为2*2列联表,df=1,须用连续性校正公式,故采用“连续校正”行的统计结果。 X2=,P(Sig)=<,表明灭螨剂A组的杀螨率极显着高于灭螨剂B组。 例 表3 治疗方法* 治疗效果交叉制表 计数 治疗效果 123 合计 治疗方法11916540 21612836 31513735合计504120111 分析:表3是治疗方法* 治疗效果资料分析的列联表。 表4 卡方检验 X2值df渐进 Sig. (双侧) Pearson 卡方 1.428a4.839
似然比4.830线性和线性组合.5141.474 有效案例中的 N111 a. 0 单元格(.0%) 的期望计数少于 5。最小期望计数为。 分析:表4是卡方检验的结果。自由度df=4,表格下方的注解表明理论次数小于5的格子数为0,最小的理论次数为。各理论次数均大于5,无须进行连续性校正,因此可以采用第一行(Pearson 卡方)的检验结果,即 X2=,P=>,差异不显着,可以认为不同的治疗方法与治疗效果无关,即三种治疗方法对治疗效果的影响差异不显着。 例 表5 灌溉方式* 稻叶情况交叉制表 计数 稻叶情况 123 合计 灌溉方式114677160 2183913205 31521416182合计4813036547 分析:表5是灌溉方式* 稻叶情况资料分析的列联表。
卡方检验
第八章记数数据统计法—卡方检验法 知识引入 在各个研究领域中,有些研究问题只能划分为不同性质的类别,各类别没有量的联系。例如,性别分男女,职业分为公务员、教师、工人、……,教师职称又分为教授、副教授、……。有时虽有量的关系,因研究需要将其按一定的标准分为不同的类别,例如,学习成绩、能力水平、态度等都是连续数据,只是研究者依一定标准将其划分为优良中差,喜欢与不喜欢等少数几个等级。对这些非连续等距性数据,要判别这些分类间的差异或者多个变量间的相关性方法称为计数数据统计方法。 卡方检验是专用于解决计数数据统计分析的假设检验法。本章主要介绍卡方检验的两个应用:拟合性检验和独立性检验。拟合性检验是用于分析实际次数与理论次数是否相同,适用于单个因素分类的计数数据。独立性检验用于分析各有多项分类的两个或两个以上的因素之间是否有关联或是否独立的问题。 在计数数据进行统计分析时要特别注意取样的代表性。我们知道,统计分析就是依据样本所提供的信息,正确推论总体的情况。在这一过程中,最根本的一环是确保样本的代表性及对实验的良好控制。在心理与教育研究中,所搜集到的有些数据属于定性资料,它们常常是通过调查、访问或问卷获得,除了少数实验可以事先计划外,大部分收集数据的过程是难于控制的。例如,某研究者关于某项教育措施的问卷调查,由于有一部分教师和学生对该项措施存有意见,或对问卷本身有偏见,根本就不填写问卷。这样该研究所能收回的问卷只能代表一部分观点,所以它是一个有偏样本,若据此对总体进行推论,就会产生一定的偏差,势必不能真实地反映出教师与学生对这项教育措施的意见。因此应用计数资料进行统计推断时,要特别小心谨慎,防止样本的偏倚性,只有具有代表性的样本才能作出正确的推论。 第一节卡方拟合性检验 一、卡方检验的一般问题 卡方检验应用于计数数据的分析,对于总体的分布不作任何假设,因此它又是非参数检验法中的一种。它由统计学家皮尔逊推导。理论证明,实际观察次数(f o)与理论次数(f e),又称期望次数)之差的平方再除以理论次数所得的统计量,近似服从卡方分布,可表示为: 这是卡方检验的原始公式,其中当f e越大(f e≥5),近似得越好。显然f o与f e相差越大,卡方值就越大;f o与f e相差越小,卡方值就越小;因此它能够用来表示f o与f e相差的程度。根据这个公式,可认为卡方检验的一般问题是要检验名义型变量的实际观测次数和理论次数分布之间是否存在显著差异。它主要应用于两种情况: 卡方检验能检验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致的问题,这里的观测次数是根据样本数据得多的实计数,理论次数则是根据理论或经验得到的期望次数。这一类检验称为拟合性检验。
非参数检验(卡方检验)实验报告
评分 大理大学实验报告 课程名称生「物医学统计分析 实验名称非参数检验(卡方检验) 专业班级 实验日期实验地点 2015—2016学年度第一2 学期 、实验目的 对分类资料进行卡方检验。 、实验环境 1、硬件配置:处理器:In tel(R)Core(TM) i5-4210U CPU @1.7GHz 1.7GHz 安装内存(RAM): 4.00GB 系统类型:64位操作系统 2、软件环境:IBM SPSS Statistics 19.0 软件 三、实验内容
(包括本实验要完成的实验问题及需要的相关知识简单概述 ) (1) 课本第六章的例6.1-6.5运行一遍,注意理解结果; (2) 然后将实验指导书的例 1-4运行一遍,注意理解结果。 四、 实验结果与分析 (包括实验原理、数据的准备、运行过程分析、源程序(代码) 例6.1 分析:表1是灭螨A 和灭螨B 杀灭大蜂螨效果的样本分类的频数分析表,即交叉列联表。 表2卡方检验 b.仅对2x2表计算 分析:表2是卡方检验的结果。因为两组各自的结果互不影响,即相互独立。对于这种频数表 格式资料,在卡方检验之前必须用“加权个案”命令将频数变量定义为加权变量,才能 进行卡方检验。 Pearson 卡方:皮尔逊卡方检验计算的卡方值(用于样本数 n > 40且所有理论数E > 5); 连续校正b :连续性校正卡方值(df=1 ,只用于2*2列联表); 似然比:对数似然比法计算的卡方值(类似皮尔逊卡方检验); Fisher 的精确检验:精确概率法计算的卡方值(用于理论数 E<5)。 不同的资料应选用不同的卡方计算方法。 例6.1为2*2列联表,df=1,须用连续性校正公式,故采用“连续校正”行的统计结果。 X 2=7.944 , P (Sig ) =0.005<0.01,表明灭螨剂 A 组的杀螨率极显著高于灭螨剂 B 组。 例6.2 表3治疗方法*治疗效果交叉制表 计数 治疗效果 、图形图象界面等) 合计
T检验和卡方检验
好久没有更新博客了,今天更新一篇关于数据分析方法的文章,主要是基于统计学的假设检验的原理,无论是T检验还是卡方检验在现实的工作中都可以被用到,而且结合Excel非常容易上手,基于这类统计学上的显著性检验能够让数据更有说服力。还是保持一贯的原则,先上方法论再上应用实例,这篇文章主要介绍方法,之后会有另外一篇文章来专门介绍实际的应用案例。 关于假设检验 假设检验(Hypothesis Testing),或者叫做显著性检验(Significance Testing)是数理统计学中根据一定假设条件由样本推断总体的一种方法。其基本原理是先对总体的特征作出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受作出推断。既然以假设为前提,那么在进行检验前需要提出相应的假设: H0:原假设或零假设(null hypothesis),即需要去验证的假设;一般首先认定原假设是正确的,然后根据显著性水平选择是接受还是拒绝原假设。 H1:备择假设(alternative hypothesis),一般是原假设的否命题;当原假设被拒绝时,默认接受备择假设。 如原假设是假设总体均值μ=μ 0,则备择假设为总体均值μ≠μ0,检验的过程就 是计算相应的统计量和显著性概率,来验证原假设应该被接受还是拒绝。 T检验 T检验(T Test)是最常见的一种假设检验类型,主要验证总体均值间是否存在显著性差异。T检验属于参数假设检验,所以它适用的范围是数值型的数据,在网站分析中可以是访问数、独立访客数、停留时间等,电子商务的订单数、销售额等。T检验还需要符合一个条件——总体符合正态分布。 这里不介绍t统计量是怎么计算的,基于t统计量的显著性概率是怎么查询的,其实这些计算工具都可以帮我们完成,如果有兴趣可以查阅统计类书籍,里面都会有相应的介绍。这里介绍的是用Excel的数据分析工具来实现T检验: Excel默认并没有加载“数据分析”工具,所以需要我们自己添加加载项,通过文件—选项—加载项—勾选“分析工具库”来完成添加,之后就可以在“数据”标签的最右方找到数据分析这个按钮了,然后就可以开始做T检验了,这里以最常见的配对样本t检验为例,比较某个电子商务网站在改版前后订单数是否产生了显著性差异,以天为单位,抽样改版前后各10天的数据进行比较:
spss实验报告
专业统计软件应用 实验报告 实验课程专业统计软件应用 上课时间2013 学年上半学期14 周(2013 年5 月27 日—31 日) 学生姓名杨守玲学号2011211432 班级0361102 所在学院经管上课地点金融实验指导教师唐兴艳
第五章思考与练习 3.表5.20 是某班级学生的高考数学成绩,试分析该班的数学成绩与全国的平均成绩70 分之间是否有显著性差异(数据文件:data5-16.sav)。 解:解决问题的原理:独立T样本检验 提出原假设和备择假设: Ho:p<0.05,该班的数学成绩与全国的平均成绩70 分之间不存在显著相关性;H1:p>0.05,该班的数学成绩与全国的平均成绩70 分之间存在显著相关性。 第1步单样本T 检验分析设置 (1)选择菜单:“分析”→“比较均值”→“单样本T 检验(S)”,打开“单样本T 检验主对话框”,确定要进行T 检验的变量并输入检验值,按如图所示进行设置。将“成绩”选入“检验变量”中,输入待检验的值“70”,用来检验产生的样本均值与检验值有无显著性差异。 第2步“选项”对话框设置:指定置信水平和缺失值的处理方法。
第3步主要结果及分析 完成以上的操作步骤后,点击“确定”按钮,运行结果如下所示,具体分析如下:下表给出了单样本T 检验的描述性统计量,包括样本数(N)、均值、标准差、均值的标准误差。 当置信水平为95%时,显著性水平为0.05,从表5.2 中可以看出,双尾检测概率P 值为0.002,小于0.05,故接受原假设,也就是说该班的数学成绩与全国的平均成绩70 分之间不存在显著相关性,即班的数学成绩与全国的平均成绩70 分之间存在显著性差异。 4. 在某次测试中,随机抽取男女同学的成绩各10 名,数据如下: 男:99 79 59 89 79 89 99 82 80 85 女:88 54 56 23 75 65 73 50 80 65 假设样本总体服从正态分布,比较置信度为95%的情况下男女得分是否有显著性差异(数据文件:data5-17.sav)。
医学统计学案例分析(1)
案例分析—四格表确切概率法 【例1-5】为比较中西药治疗急性心肌梗塞的疗效,某医师将27例急性心肌梗塞患者随机分成两组,分别给予中药和西药治疗,结果见表1-4。经检验,得连续性校正χ2=3.134,P>0.05,差异无统计学意义,故认为中西药治疗急性心肌梗塞的疗效基本相同。 表1-4 两种药物治疗急性心肌梗塞的疗效比较 药物有效无效合计有效率(%)中药12(9.33)2(4.67)1485.7 西药 6(8.67)7(4.33)1346.2 合计1892766.7【问题1-5】 (1)这是什么资料? (2)该资料属于何种设计方案? (3)该医师统计方法是否正确?为什么? 【分析】 (1) 该资料是按中西药的治疗结果(有效、无效)分类的计数资料。 (2) 27例患者随机分配到中药组和西药组,属于完全随机设计方案。 (3) 患者总例数n=27<40,该医师用χ2检验是不正确的。当n<40或T<1时,不宜计算χ2值,需采用四格表确切概率法(exact probabilities in 2×2 table)直接计算概率 案例分析-卡方检验(一) 【例1-1】某医师为比较中药和西药治疗胃炎的疗效,随机抽取140例胃炎患者分成中药组和西药组,结果中药组治疗80例,有效64例,西药组治疗60例,有效35例。该医师采用成组t检验(有效=1,无效=0)进行假设检验,结果t=2.848,P=0.005,差异有统计学意义检验(有效=1,无效=0)进行进行假设检验,结果t=2.848,P=0.005,差异有统计学意义,故认为中西药治疗胃炎的疗效有差别,中药疗效高于西药。
【问题1-1】 (1)这是什么资料?(2)该资料属于何种设计方案? (3)该医师统计方法是否正确?为什么?(4)该资料应该用何种统计方法?【分析】(1) 该资料是按中西药疗效(有效、无效)分类的二分类资料,即计数资料。(2) 随机抽取140例胃炎患者分成西药组和中药组,属于完全随机设计方案。(3) 该医师统计方法不正确。因为成组t检验用于推断两个总体均数有无差别,适用于正态或近似正态分布的计量资料,不能用于计数资料的比较。(4) 该资料的目的是通过比较两样本率来推断它们分别代表的两个总体率有无差别,应用四格表资料的 X2检验(chi-square test)。 【例1-2】 2003年某医院用中药和西药治疗非典病人40人,结果见表1-1。 表1-1 中药和西药治疗非典病人有效率的比较 药物有效无效合计有效率(%) 中药西药14(11.2) 2 (4.8) 14(16.8) 10 (7.2) 28 12 50.0 16.7 步骤如下: 1.建立检验假设,确定检验水准 H 0:两药的有效率相等,即π 1 =π 2 H 1:两药的有效率不等,即π 1 ≠π 2 2.计算检验统计量值 (1) 计算理论频数根据公式计算理论频数,填入表7-2的括号内。 (2) 计算χ2值 具体计算略。
卡方检验正态分布
卡方拟和检验的编程实现 摘要 针对一些总体分布的检验不能用现成的软件实现这一问题,本文论述了怎样应用matlab实现总体分布的检验,这里我们以正态分布为例,这里我们选用了总体分布的卡方检验,卡方检验是在总体分布未知的情况下,根据来自总体的样本,检验关于总体分布的假设的一种检验方法。 关键词:分布的检验 matlab 总体样本。 使用卡方检验分布时在总体X 的分布未知时,根据来自总体的样本,检验关于总体分布的假设的一种检验方法. 使用卡方检验对总体分布进行检验时,我们先提出原假设: H0:总体X的分布函数为F(x) 然后根据样本的经验分布和所假设的理论分布之间的吻合程度来决定是否接受原假设. 这种检验通常称作拟合优度检验,它是一种非参数检验. 在用卡方检验假设H0时,若在H0下分布类型已知,但其参数未知,这时需要先用极大似然估计法估计参数,然后作检验. 分布拟合的卡方检验的基本原理和步骤如下: 1.将总体X的取值范围分成k个互不重迭的小区间,记作A1, A2, …,
Ak . 2. 把落入第i 个小区间Ai 的样本值的个数记作fi , 称为实测频数. 所有实测频数之和f1+ f2+ …+ fk 等于样本容量n. 3. 根据所假设的理论分布,可以算出总体X 的值落入每个Ai 的概率pi,于是npi 就是落入Ai 的样本值的理论频数. 皮尔逊引进如下统计量表示经验分布与理论分布之间的差异: 卡方统计量2 χ=∑=-r k k k k np np n 12)( 用上述原理检验是否服从分布: 以下为一个筛子投掷四十次的数据:1 4 4 6 3 4 5 2 4 6 3 4 4 2 3 6 3 1 3 4 4 5 2 2 3 3 3 1 5 1 2 2 4 5 5 5 1 3 2 5 程序如下: 输入数据: 运行结果:
spss实验报告—非参数检验
实验报告 ——(非参数检验) 实验目的: 1、学会使用SPSS软件进行非参数检验。 2、熟悉非参数检验的概念及适用范围,掌握常见的秩和检验计算方法。 实验内容: 1、某公司准备推出一个新产品,但产品名称还没有正式确定,决定进行抽样调 查,在受访200人中,52人喜欢A名称,61人喜欢B名称,87人喜欢C 名称,请问ABC三种名称受欢迎的程度有无差别?(数据表自建) SPSS计算结果如下: 此题为总体分布的卡方检验。 零假设:样本来自总体分布形态和期望分布没有显著差异。即ABC三种名称受欢迎的程度无差别,分布形态为1:1:1,呈均匀分布。 观察结果,上表为200个观察数据对A、B、C三个名称(分别对应1,2,3)的喜爱的期望频数以及实际观察频数和期望频数的差。从下表中可以看出相伴概
率值为0.007小于显著性水平0.05,因此拒绝零假设,认为样本来自的总体分布与制定的期望分布有显著差异,即A、B、C三种名称受欢迎的程度有差异。 2、某村庄发生了一起集体食物中毒事件,经过调查,发现当地居民是直接饮用 河水,研究者怀疑是河水污染所致,县按照可疑污染源的大致范围调查了沿河居民的中毒情况,河边33户有成员中毒(+)和均未中毒(-)的家庭分布如下:(案例数据run.sav) -+++*++++-+++-+++++----++----+---- 毒源 问:中毒与饮水是否有关? SPSS计算结果如下: 此题为单样本变量值随机检验 零假设:总体某变量的变量值是随机出现的。即中毒的家庭沿河分布的情况随机分布,与饮水无关。 相伴概率为0.036,小于显著性水平0.05,拒绝零假设,因此中毒与饮水有关。 3、某试验室用小白鼠观察某种抗癌新药的疗效,两组各10只小白鼠,以生存日数作为观察指标,试验结果如下,案例数据集为:npara1.sav,问两组小白鼠生存日数有无差别。 试验组:24 26 27 30 32 34 36 40 60 天以上 对照组:4 6 7 9 10 10 12 13 16 16 SPSS计算结果如下: 此题为两独立样本非参数检验。 (1)两独立样本Mann-Whitney U检验:
卡方检验原理与应用实例
卡方检验原理与应用实例: 本文简单介绍卡方检验的原理和两个类型的卡方检验实例。 一、卡方检验的作用和原理 1)卡方检验的作用:简单来说就是检验实际的数据分布情况与理论的分布情况是否相同的假设检验方法。怎么理解这句话呢,拿一个群体的身高来说,理论上身高低于1米5的占10%,高于2.0的占10%,中间的占80%,现在我们抽取了这个群体中的一群人,那么对应这三个身高段的人数的比例关系是不是 1:8:1呢?卡方分析就是解决这类问题。 2)卡方检验的原理:上面已经提到卡方检验是检验实际的分布于理论的分布时候一致的检验,那么用什么统计量来衡量呢!统计学家引入了如下的公式: Ai为i水平的观察频数,Ei为i水平的期望频数,n为总频数,pi为i水平的期望频率。i水平的期望频数Ti等于总频数n×i水平的期望概率pi,k为单元格数。当n比较大时,χ2统计量近似服从k-1(计算Ei时用到的参数个数)个自由度的卡方分布。和参数检验的判断标准一样,这个统计量有一个相伴概率p。零假设是理论分布与实际分布是一致的,所以如果P小于0.05,那么就拒绝原假设,认为理论和实际分布不一致。 二、适合性卡方测验 所谓适合性检验就是检验一个样本的分布是否符合某个分布的一种假设检验方法。比如说检验数据是否正态分布,是否成二项分布或者平均分布等等。拿正态分布来说吧!请看下图
在这个近似标准正态分布的玉米株高的分布中,横轴代表的是株高的数据,而纵轴代表的是对应株高的频数,简单来说,正态曲线上的某点的纵坐标代表的就是这个点对应的横轴坐标显示株高的玉米有多少株。只不过正态分布曲线上显示的是频率值,而频率=该组株数/总的株数,所以分布曲线不会变,只不过纵坐标由频数变为频率。这也解释了昨天推送的《如何判断数据是否符合正态分布》中用带正态曲线的直方图判断数据是否符合正态分布的原理。 回到本节,当我们要检验玉米株高是否符合正态分布时,我们能够通过计算,计算出当样本量为600(注意本例株高数据的个案数为600,下载数据资料进行练习过的学员应该知道)时,每个株高下的玉米株数设为E,然后我们已经有实际值设为A,然后我们带入上面的公式计算得到卡方统计量,由SPSS输出相伴概率,我们就能判断数据是否符合正态分布了。 再说一个例子。
非参数检验(卡方检验),实验报告
非参数检验(卡方检验),实验报告 评分 大理大学实验报告 课程名称 生物医学统计分析 实验名称 非参数检验( 卡方检验) 专业班级 姓 名 学 号 实验日期 实验地点 20xx—20xx 学年度第 2 学期一、 实验目得对分类资料进行卡方检验。 二、实验环境 1 、硬件配置:处理器:Intel(R) Core(TM) i5-4210U CPU 1、7GHz 1、7GHz 安装内存(RAM):4、00GB 系统类型:64 位操作系统 2 、软件环境:IBM SPSS
Statistics 19、0 软件 三、实验内容(包括本实验要完成得实验问题及需要得相关知识简单概述) (1) 课本第六章得例6、1-6、5 运行一遍,注意理解结果; (2)然后将实验指导书得例1-4 运行一遍,注意理解结果。 四、实验结果与分析 (包括实验原理、数据得准备、运行过程分析、源程序(代码)、图形图象界面等) 例例6 、1 表1 灭螨A A 与灭螨B B 杀灭大蜂螨效果得交叉制表 效果合计杀灭未杀灭组别灭螨A 32 12 44 灭螨B 14 22 36 合计46 34 80 分析: 表1就是灭螨A与灭螨B杀灭大蜂螨效果得样本分类得频数分析表,即交叉列联表。 表2 卡方检验 X2 值df 渐进Sig、(双侧) 精确Sig、(双侧) 精确Sig、(单侧) Pearson 卡方9、277a 1 、002 连续校正b 7、944 1 、005 似然比9、419 1 、002 Fisher 得精确检验 、003 、002 有效案例中得N 80 a、0 单元格(、0%) 得期望计数少于5。最小期望计数为
卡方检验结果分析
样本的基本信息: 一、样本总数56 二、性别:男27人,女29人 三、年级:大二 四、民族:汉族25人,少数民族31人 五、学院:社心学院16人,管理学院12人,旅历学院17人,计科学院11人 ◆性别与其它因素的关系: 1、平时阅读情况与性别的关系 结论:经过交叉表卡方检验,期望值频数总和为55,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.345大于0.05,因而有理由接受H0,拒绝H1,因此平时阅读情况与性别不存在显著性差异。 2、有否阅读计划与性别的关系 结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson精确检验,其中sig值0.128大于0.05,因而有理由接受H0,拒绝H1,因此有否阅读计划与性别不存在显著性差异。
3、阅读方式与性别的关系 结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数少于5,最小期望计数为0.96接近1,因而使用fisher 精确检验,其中sig值0.161大于0.05,因而有理由接受H0,拒绝H1,因此有否阅读计划与性别不存在显著性差异。 4、对课外阅读的看法与性别的关系 结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.857大于0.05,因而有理由接受H0,拒绝H1,因此对课外阅读的看法与性别不存在显著性差异。
5、阅读量的趋势与性别的关系 结论:经过交叉表卡方检验,期望值频数总和为56,大于40,期望计数小于5大于1,因而使用pearson卡方检验,其中sig值0.048小于0.05,因而有理由拒绝H0,接受H1,因此阅读量趋势与性别存在显著性差异。 结论:经过交叉表卡方检验,期望值频数总和为55,大于40,期望计数大于5,因而使用pearson卡方检验,其中sig值0.139大于0.05,因而有理由接受H0,拒绝H1,因此是否有足够时间进行课外阅读与性别不存在显著性差异。
SPSS学习系列24.-卡方检验
SPSS学习系列24.-卡方检验
24. 卡方检验 卡方检验,是针对无序分类变量的一种非参数检验,其理论依据是:实际观察频数f 0与理论频数f e (又称期望频数)之差的平方再除以理论频数所得的统计量,近似服从2χ分布,即 ) (n f f f e e 2 202 ~)(χχ∑-= 卡方检验的一般是用来检验无序分类变量的实际观察频数和理论频数分布之间是否存在显著差异,二者差异越小,2χ值越小。 卡方检验要求: (1)分类相互排斥,互不包容; (2)观察值相互独立; (3) 样本容量不宜太小,理论频数≥5,否则需要进行校正(合并单元格、增加样本数、去除样本法、使用校正公式校正卡方值)。 卡方校正公式为: ∑ --=e e f f f 2 02 )5.0(χ 卡方检验的原假设H 0: 2χ= 0; 备择假设H 1: 2χ≠0; 卡方检验的用途: (1)检验某连续变量的数据是否服从某种分布(拟合优度检验); (2)检验某分类变量各类的出现概率是否等于指定概率; (3)检验两个分类变量是否相互独立(关联性检验); (4)检验控制某几个分类因素之后,其余两个分类变量是否相
互独立; (5)检验两种方法的结果是否一致,例如两种方法对同一批人进行诊断,其结果是否一致。 (一)检验单样本某水平概率是否等于某指定概率 一、单样本案例 例如,检验彩票中奖号码的分布是否服从均匀分布(概率=某常值);检验某产品市场份额是否比以前更大;检验某疾病的发病率是否比以前降低。 有数据文件: 检验“性别”的男女比例是否相同(各占1/2)。 1. 【分析】——【非参数检验】——【单样本】,打开“单样本非参数检验”窗口,【目标】界面勾选“自动比较观察数据和假设数据”
数理统计实验报告
《概率论与数理统计》实验报告 学生姓名 学生班级 学生学号 指导教师 学年学期
实验报告一
实验内容实验过程(实验操作步骤)实验结果 1.某厂生产的化纤强度 2 ~(,0.85) X Nμ,现抽取一个容量为25 n=的样本,测定其强度,得样本均值 2.25 x=,试求这批化纤平均强度的置信水平为0.95的置信区间.第1步:打开【单个正太总体均值 Z估计活动表】。 第2步:在单元格【B3】中输入 0.95,在单元格【B4】中输入25, 在单元格【B5】中输入2.25,显示 结果。 由此可得,这批化纤平均 强度的置信水平为0.95的 置信区 区间为(1.92,2.58).
2.已知某种材料的抗压 强度 2 ~(,) X Nμσ,现 随机抽取10个试件进行抗压试验,测得数据如下: 482,493,457,471,510,446,435,418,394,469 求平均抗压强度 μ的置信水平为0.95的置信区间; (2)求2 σ的置信水平为0.95的置信区间.第1步:打开【单个正太总体均值 t估计活动表】. 第2步:在D列输入原始数据. 第3步:点击【工具(T)】→选择 【数据分析(D)】→选择【描述统 计】→点击【确定】按钮→在【描 述统计】对话框输入相关内容→点 击【确定】按钮,得到F列与G列 结果。 第4步:在单元格【B3】中输入 0.95,在单元格【B4】中输入10, 在【B5】中引用G3,在【B6】中引 用G7,显示结果。 由此可得,平均抗压强度 μ的置信水平为0.95的置 信区间(432.31,482.69) 由此可得,2 σ的置信水平 为0.95的置信区间为 (586.80,4133.66)
卡方检验的这点你千万不能忽视哦
方检验的这点,你千万不能忽视哦! 方检验 方检验有两种用途:1、拟合优度检验(goodness of fit test ):用卡方统计量进行统计学检验,依据总体分布 状况,计算出分类变量中各类别的期望频数,与分布的观察频数进行对比,判断期望频数与观察频数是否有显著差异,从而达到对分类变量的分布进行分析的目的。2、拟合优度检验是对一个分 类变量的检验,有时我们会遇到两个分类变量的问题(也就是列联表数据,横标目和纵标目各代表一个分类变量),看这 两个分类变量是否存在联系。现在,来个题考考大家!双向 无序列联表资料什么时候能用卡方检验,什么时候要用 精确概率法? 传统的统计教材中般认为:对双向无序的RxC 列联表资料 进行卡方检验中,当样本量小,存在单元格的理论频数(又 叫期望计数)小于5 ,或这样的单元格数超过总单元格数的20% ,才需要选用精确概率法。其实,这种说法已经过时了。 John H. McDonald 在Handbook of Biological Statistics (3rd ed.)一书中对卡方检验的适用条件进行 了新的阐述。完全颠覆了我的以往思路。现总结归纳如下 、只要样本量小于1000 的列联表资料,都应该使用精确 概率法。因为,1000 以下样本量的精确概率法在Excel 、SAS 、
SPSS 等软件中都可以轻松实现。 、当样本量比1000 大很多时,即使在大型计算机上的强大软件(例如SAS )做精确概率法的运算都可能存在困难,所以对于样本量大于1000 时,应该使用卡方检验。如果自由度只有1 ,可以使用Yates 连续性校正(但是对于如此大的样本量,Yates 连续性校正对P 值在准确性上的改进是微不足道。) 、为了便于操作,McDonald 将其经验法则建立在总样本 量的基础上,而不是最小的期望计数;如果一个或多个期望 计数是非常小(个位数),即使总样本量大于1000 ,也应该 使用精确概率法,只是但愿你的计算机能够处理这样的运算量。 四、如果分类变量的类别数太多,有些类别的期望计数非常小,应该考虑合并较少频数的类别,即使运用的是精确概率法,合并类别后,更小的自由度将提高检验的效力。 五、如果看到别人按照传统的过时规则,对总样本量小于 1000 的数据进行卡方检验,不用太过于担心。旧的习惯很 难改变,除非期望计数真的非常小(达到个位数),否则这 可能不会对结论产生太大的影响。如果卡方检验得到的P 值只低于0.05 一点点,可以用精确概率法再次分析该数据。如 果精确概率法得到的P 值大于0.05 ,那说明卡方检验所得P 值导致了一个完全相反的结论,产生假阳性。下面举例阐述:
医学统计学案例分析
医学统计学案例分析 案例分析—四格表确切概率法 【例1-5】为比较中西药治疗急性心肌梗塞de疗效,某医师将27例急性心肌梗塞患者随机分成两组,分别给予中药和西药治疗,结果见表1-4。经检2验,得连续性校正χP,,差异无统计学意义,故认为中西药治=, 疗急性心肌梗塞de疗效基本相同。 表1-4 两种药物治疗急性心肌梗塞de疗效比较药物有效无效合计有效率(,) 中药 12 2 14 西药 6 7 13 合计 18 9 27 【问题1-5】 (1) 这是什么资料, (2) 该资料属于何种设计方案, (3) 该医师统计方法是否正确,为什么, 【 【分析】 (1) 该资料是按中西药de治疗结果(有效、无效)分类de计数资料。 (2) 27例患者随机分配到中药组和西药组,属于完全随机设计方案。 2(3) 患者总例数n=27,40,该医师用χ检验是不正确de。当n,40或T,1时,2不宜计算χ值,需采用四格表确切概率法(exact probabilities in 2×2 table)直接计算概率 案例分析,卡方检验(一) 【例1-1】某医师为比较中药和西药治疗胃炎de疗效,随机抽取140例胃炎患者分成中药组和西药组,结果中药组治疗80例,有效64例,西药组治疗60例,有效35例。该医师采用成组t检验(有效=1,无效=0)进行假设检验,结
检验(有效=1,无效=0)进行进行果t,,P,,差异有统计学意义 假设检验,结果t,,P,,差异有统计学意义,故认为中西药治疗胃炎de疗效有差别,中药疗效高于西药。 【问题1-1】 【 (1)这是什么资料,(2)该资料属于何种设计方案, (3)该医师统计方法是否正确,为什么,(4)该资料应该用何种统计方法, 【分析】 (1) 该资料是按中西药疗效(有效、无效)分类de二分类资料,即计数资料。 (2) 随机抽取140例胃炎患者分成西药组和中药组,属于完全随机设计方案。(3) 该医师统计 方法不正确。因为成组t检验用于推断两个总体均数有无差别,适用于正态或近似正态分布de计量资料,不能用于计数资料de比较。 (4) 该资料de目de是通过比较两样本率来推断它们分别代表de两个总体率有无差别,应用四格表资料de 检 验(chi-square test)。 【例1-2】 2003年某医院用中药和西药治疗非典病人40人,结果见表1-1。 表1-1 中药和西药治疗非典病人有效率de比较 药物有效无效合计有效率(,) 中药 28 1414 西药 2 10 12 合计 16 24 40 某医师认为这是完全随机设计de2组二分类资料,可用四格表de检验。其步 骤如下: 1(建立检验假设,确定检验水准 [ H:两药de有效率相等,即0 π,π12
非参数检验(卡方检验)实验报告
. . 大学实验报告 课程名称生物医学统计分析 实验名称非参数检验(卡方检验)专业班级 姓名 学号 实验日期 实验地点 2015—2016学年度第 2 学期
a. 不假定零假设。 b. 使用渐进标准误差假定零假设。 分析:表11为LPA和FA两种检测结果的的一致性检验。Kappa值是部一致性系数,除数据P值判断一致性有无统计学意义外,根据经验,Kappa≥0.75,表明两者一致性较好0.7>Kappa ≥0.4,表明一致性一般,Kappa<0.4,则表明一致性较差。 本例Kappa值为0.680,P=0.000<0.01,拒绝无效假设,即认为两种检测方法结果存在一致性,Kappa值=0.680,0.7>Kappa≥0.4,表明一致性一般。 例1 表12 周日频数表 观察数期望数残差 1 11 16.0 -5.0 2 19 16.0 3.0 3 17 16.0 1.0 4 1 5 16.0 -1.0 5 15 16.0 -1.0 6 16 16.0 .0 7 19 16.0 3.0 总数112 分析:表12结果显示一周各日死亡的理论数(Expected)为16.0,即一周各日死亡均数;还算出实际死亡数与理论死亡数的差值(Residual)。 表13 检验统计量 周日 卡方 2.875a df 6 渐近显著性.824 a. 0 个单元 (.0%) 具有小于 5 的期望频率。单元最小期望频率为 16.0。 分析:Chi-Square过程,调用此过程可对样本数据的分布进行卡方检验。卡方检验适用于配合度检验,主要用于分析实际频数与某理论频数是否相符。卡方值X2=2.875,自由度数(df)=6,P=0.824>0.05,差异不显著,即可认为一周各日的死亡危险性是相同的。 例2 表14 二项式检验 类别N 观察比例检验比例精确显著性(双侧)性别组 1 0 12 .30 .50 .017 组 2 1 28 .70
多个样本率的卡方检验及两两比较--之-spss-超简单知识分享
多个样本率的卡方检验及两两比较--之-s p s s-超简单
SPSS:多个样本率的卡方检验及两两比较 来自:医咖会 医咖会之前推送过“两个率的比较(卡方检验)及Fisher精确检验的SPSS教程”,小伙伴们都掌握了吗?如果不止两个分组,又该如何进行卡方检验以及之后的两两比较呢?来看详细教程吧! 1、问题与数据 某医生拟探讨药物以外的其他方法是否可降低患者的胆固醇浓度,如增强体育锻炼、减少体重及改善饮食习惯等。 该医生招募了150位高胆固醇、生活习惯差的受试者,并将其随机分成3组。其中一组给予降胆固醇药物,一组给予饮食干预,另一组给予运动干预。经过6个月的试验后,该医生重新测量受试者的胆固醇浓度,分为高和正常两类。 该医生收集了受试者接受的干预方法(intervention)和试验结束时胆固醇的风险程度(risk_level)等变量信息,并按照分类汇总整理,部分数据如下:
注释:本研究将胆固醇浓度分为“高”和“正常”两类,只是为了分析的方便,并不代表临床诊断结果。 2、对问题的分析 研究者想判断干预后多个分组情况的不同。如本研究中经过降胆固醇药物、饮食和运动干预后,比较各组胆固醇浓度的变化情况。针对这种情况,我们建议使用卡方检验(2×C),但需要先满足5项假设: 假设1:观测变量是二分类变量,如本研究中试验结束时胆固醇的风险程度变量是二分类变量。 假设2:存在多个分组(>2个),如本研究有3个不同的干预组。 假设3:具有相互独立的观测值,如本研究中各位受试者的信息都是独立的,不会相互干扰。 假设4:研究设计必须满足:(a) 样本具有代表性,如本研究在高胆固醇、生活习惯差的人群中随机抽取150位受试者;(b) 目的分组,可以是前瞻性的,也可以是回顾性的,如本研究中将受试者随机分成3组,分别给予降胆固醇药物、饮食和运动干预。 假设5:样本量足够大,最小的样本量要求为分析中的任一预测频数大于5。 经分析,本研究数据符合假设1-4,那么应该如何检验假设5,并进行卡方检验(2×C)呢? 3、思维导图