数据结构哈夫曼编码

摘要利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。这要求在发送端通过一个编码系统对待传输数据预先编码,在接收端将传来的数据进行译码(复原),将所得结果存储到已开辟空间中。试为这样的信息收发站编写一个哈夫曼码的编/译码系统。本程序可以对任何大小的字符型文件进行Huffman编码,生成一个编码文件。并可以在程序运行结束后的任意时间对它解码还原生成字符文件。即:先对一条电文进行输入,并实现Huffman编码,然后对Huffman编码生成的代码串进行译码,最后输出电文数字
Abstract Use hoffmann code was communication can improve the utilization rate of channel, shorten the information transmission time, reduce the transmission cost. This requirement in the sending end through a coding system in advance to transmit data coding, in the receiver will spread of the data decoding (restoration), will the results of open space to store already. Try for such information sending and receiving station write a hoffmann yards of make up/decoding system. This program can on any of the size of the file type character Huffman coding, generates a code files. And can the running of the application at any time after the end of the reduction of decoding it generated character files. Namely: first to a message for input, and realize the Huffman coding, and then to Huffman coding generated code string decode, finally digital output message
关键字哈夫曼编码;哈夫曼译码
Keywords Hoffmann code; Hoffmann decode
1 设计要求
对输入的一串电文字符实现哈夫曼编码,输出电文字符串。通常我们把数据压缩的过程称为编码。电报通信是传递文字的二进制码形式的字符串。但在信息传递时,总希望总长度能尽可能短,即采用最短码。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长度为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵哈夫曼树,此构造过程称为哈夫曼编码。设计实现的功能: (1) 哈夫曼树的建立; (2) 哈夫曼编码的生成;(3) 对编码文件的译码。
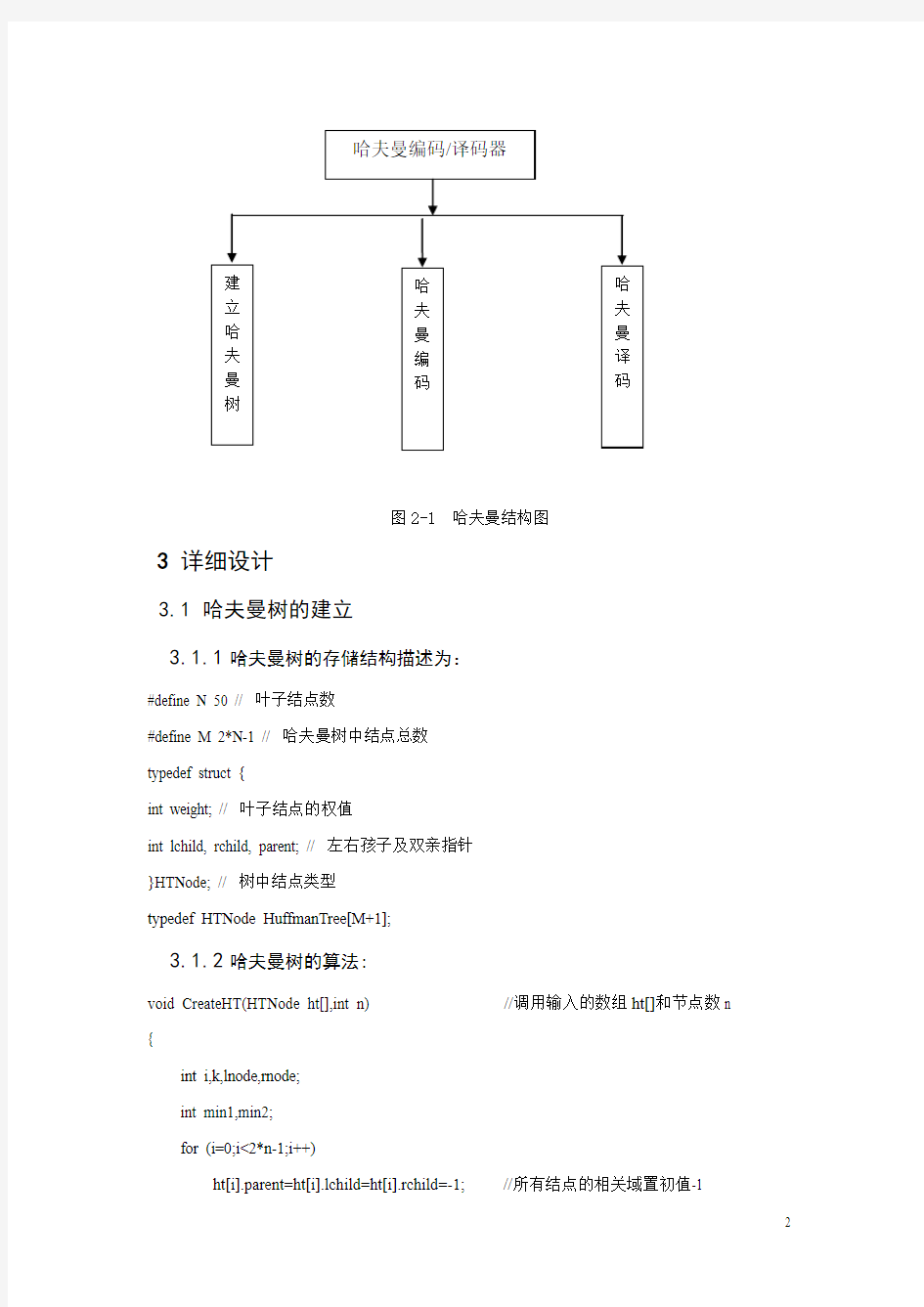
2系统结构图(功能模块图)
图2-1 哈夫曼结构图
3 详细设计
3.1 哈夫曼树的建立
3.1.1哈夫曼树的存储结构描述为:
#define N 50 // 叶子结点数
#define M 2*N-1 // 哈夫曼树中结点总数
typedef struct {
int weight; // 叶子结点的权值
int lchild, rchild, parent; // 左右孩子及双亲指针
}HTNode; // 树中结点类型
typedef HTNode HuffmanTree[M+1];
3.1.2哈夫曼树的算法:
void CreateHT(HTNode ht[],int n) //调用输入的数组ht[]和节点数n
{
int i,k,lnode,rnode;
int min1,min2;
for (i=0;i<2*n-1;i++)
ht[i].parent=ht[i].lchild=ht[i].rchild=-1; //所有结点的相关域置初值-1 哈夫曼编码/译码器
建立哈夫曼树
哈夫曼编码 哈
夫
曼
译
码
for (i=n;i<2*n-1;i++) //构造哈夫曼树
{
min1=min2=32767; //int的范围是-32768—32767
lnode=rnode=-1; //lnode和rnode记录最小权值的两个结点位置
for (k=0;k<=i-1;k++)
{
if (ht[k].parent==-1) //只在尚未构造二叉树的结点中查找
{
if (ht[k].weight { min2=min1;rnode=lnode; min1=ht[k].weight;lnode=k; } else if (ht[k].weight { min2=ht[k].weight;rnode=k; } } } ht[lnode].parent=i;ht[rnode].parent=i; //两个最小节点的父节点是i ht[i].weight=ht[lnode].weight+ht[rnode].weight; //两个最小节点的父节点权值为两个最小节点权值之和 ht[i].lchild=lnode;ht[i].rchild=rnode; //父节点的左节点和右节点} } 3.2哈夫曼编码 void CreateHCode(HTNode ht[],HCode hcd[],int n) { int i,f,c; HCode hc; for (i=0;i { hc.start=n;c=i; f=ht[i].parent; while (f!=-1) //循序直到树根结点结束循环 { if (ht[f].lchild==c) //处理左孩子结点 hc.cd[hc.start--]='0'; else //处理右孩子结点 hc.cd[hc.start--]='1'; c=f;f=ht[f].parent; } hc.start++; //start指向哈夫曼编码hc.cd[]中最开始字符hcd[i]=hc; } } void DispHCode(HTNode ht[],HCode hcd[],int n) //输出哈夫曼编码的列表 { int i,k; printf(" 输出哈夫曼编码:\n"); for (i=0;i printf(" %c:\t",ht[i].data); for (k=hcd[i].start;k<=n;k++) //输出所有data中数据的编码 { printf("%c",hcd[i].cd[k]); } printf("\n"); } } void editHCode(HTNode ht[],HCode hcd[],int n) //编码函数 { char string[MAXSIZE]; int i,j,k; scanf("%s",string); //把要进行编码的字符串存入string数组中printf("\n输出编码结果:\n"); for (i=0;string[i]!='#';i++) //#为终止标志 { for (j=0;j { if(string[i]==ht[j].data) //循环查找与输入字符相同的编号,相同的就输出这个字符的编码 { for (k=hcd[j].start;k<=n;k++) { printf("%c",hcd[j].cd[k]); } break; //输出完成后跳出当前for循环 } } } } 3.3哈夫曼译码 void deHCode(HTNode ht[],HCode hcd[],int n) //译码函数 { char code[MAXSIZE]; int i,j,l,k,m,x; scanf("%s",code); //把要进行译码的字符串存入code数组中while(code[0]!='#') for (i=0;i { m=0; //m为想同编码个数的计数器 for (k=hcd[i].start,j=0;k<=n;k++,j++) //j为记录所存储这个字符的编码个数 { if(code[j]==hcd[i].cd[k]) //当有相同编码时m值加1 m++; } if(m==j) //当输入的字符串与所存储的编码字符串个数相等时则输出这个的data数据 { printf("%c",ht[i].data); for(x=0;code[x-1]!='#';x++) //把已经使用过的code数组里的字符串删除 { code[x]=code[x+j]; } } } } 3.4主函数 void main() { int n=26,i; char orz,back,flag=1; char str[]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'}; //初始化 int fnum[]={186,64,13,22,32,103,21,15,47,57,1,2,32,20,57,63,15,1,48,51,80,23,8,18,1,16}; //初始化 HTNode ht[M]; //建立结构体 HCode hcd[N]; //建立结构体 for (i=0;i { ht[i].data=str[i]; ht[i].weight=fnum[i]; } while (flag) //菜单函数,当flag为0时跳出循环 3.5显示部分源程序: { printf("\n"); printf(" ********************************"); printf("\n ** 1---------------显示编码**"); printf("\n ** 2---------------进行编码**"); printf("\n ** 3---------------进行译码**"); printf("\n ** 4---------------退出**\n"); printf(" * **********************************"); printf("\n"); printf(" 请输入选择的编号:"); scanf("%c",&orz); switch(orz) { case 'a': case 'A': system("cls"); //清屏函数 CreateHT(ht,n); CreateHCode(ht,hcd,n); DispHCode(ht,hcd,n); printf("\n按任意键返回..."); getch(); system("cls"); break; case 'b': case 'B': system("cls"); printf("请输入要进行编码的字符串(以#结束):\n"); editHCode(ht,hcd,n); printf("\n按任意键返回..."); getch(); system("cls"); break; case 'c': case 'C': system("cls"); DispHCode(ht,hcd,n); printf("请输入编码(以#结束):\n"); deHCode(ht,hcd,n); printf("\n按任意键返回..."); getch(); system("cls"); break; case 'd': case 'D': flag=0; break; default: system("cls"); } } } 4 程序运行结果 进入主菜单 图4-1选A时的显示结果 选B时的显示结果 选C时的显示结果 图4-4 5 心得体会 通过这次课程设计,我们学习了很多在上课没懂的知识,并对求哈夫曼树及哈夫曼编码/译码的算法有了更加深刻的了解,更巩固了课堂中学习有关于哈夫曼编码的知识,真正学会一种算法了。我们认识到根据不同的需求,采用不同的数据存储方式,不一定要用栈,二叉树等高级类型,有时用基本的一维数组,只要运用得当,也能达到相同的效果,甚至更佳,就如这次的课程设计,通过用for 的多重循环,舍弃多余的循环,提高了程序的运行效率。这次课程设计,我们在编辑中犯了不应有的错误,设计统计字符和合并时忘记应该怎样保存数据,对文件的操作也很生疏。在不断分析后明确并改正了错误和疏漏,我们的程序有了更高的质量。另外,互帮互助让我们的程序设计更加完善。 参考文献 [1] 徐孝凯编著,《数据结构课程实验》,清华大学出版 2002年第一版 [2] 张乃笑编著,《数据结构与算法》,电子工业出版社 2004年10月 [3] 严蔚敏《数据结构》(C语言版)清华大学出版社 [4] 李春葆《数据结构(C语言篇)—习题与解析》(修订版)清华大学出版 2002年4月第一版 附录 源程序如下: #include #include #include #include #define N 50 //义用N表示50叶节点数 #define M 2*N-1 //用M表示节点总数当叶节点数位n时总节点数为2n-1 #define MAXSIZE 100 typedef struct { char data; //结点值 int weight; //权值 int parent; //双亲结点 int lchild; //左孩子结点 int rchild; //右孩子结点 }HTNode; typedef struct { char cd[N]; //存放哈夫曼码 int start; //从start开始读cd中的哈夫曼码 }HCode; void CreateHT(HTNode ht[],int n) //调用输入的数组ht[],和节点数n { int i,k,lnode,rnode; int min1,min2; for (i=0;i<2*n-1;i++) ht[i].parent=ht[i].lchild=ht[i].rchild=-1; //所有结点的相关域置初值-1 for (i=n;i<2*n-1;i++) //构造哈夫曼树 { min1=min2=32767; //int的范围是-32768—32767 lnode=rnode=-1; //lnode和rnode记录最小权值的两个结点位置 for (k=0;k<=i-1;k++) { if (ht[k].parent==-1) //只在尚未构造二叉树的结点中查找 { if (ht[k].weight { min2=min1;rnode=lnode; min1=ht[k].weight;lnode=k; } else if (ht[k].weight { min2=ht[k].weight;rnode=k; } } } ht[lnode].parent=i;ht[rnode].parent=i; //两个最小节点的父节点是i ht[i].weight=ht[lnode].weight+ht[rnode].weight; //两个最小节点的父节点权值为两个最小节点权值之和 ht[i].lchild=lnode;ht[i].rchild=rnode; //父节点的左节点和右节点} } void CreateHCode(HTNode ht[],HCode hcd[],int n) { int i,f,c; HCode hc; for (i=0;i { hc.start=n;c=i; f=ht[i].parent; while (f!=-1) //循序直到树根结点结束循环 { if (ht[f].lchild==c) //处理左孩子结点 hc.cd[hc.start--]='0'; else //处理右孩子结点 hc.cd[hc.start--]='1'; c=f;f=ht[f].parent; } hc.start++; //start指向哈夫曼编码hc.cd[]中最开始字符hcd[i]=hc; } } void DispHCode(HTNode ht[],HCode hcd[],int n) //输出哈夫曼编码的列表 { int i,k; printf(" 输出哈夫曼编码:\n"); for (i=0;i printf(" %c:\t",ht[i].data); for (k=hcd[i].start;k<=n;k++) //输出所有data中数据的编码 { printf("%c",hcd[i].cd[k]); } printf("\n"); } } void editHCode(HTNode ht[],HCode hcd[],int n) //编码函数 { char string[MAXSIZE]; int i,j,k; scanf("%s",string); //把要进行编码的字符串存入string数组中printf("\n输出编码结果:\n"); for (i=0;string[i]!='#';i++) //#为终止标志 { for (j=0;j { if(string[i]==ht[j].data) //循环查找与输入字符相同的编号,相同的就输出这个字符的编码 { for (k=hcd[j].start;k<=n;k++) { printf("%c",hcd[j].cd[k]); } break; //输出完成后跳出当前for循环 } } } } void deHCode(HTNode ht[],HCode hcd[],int n) //译码函数 { char code[MAXSIZE]; int i,j,l,k,m,x; scanf("%s",code); //把要进行译码的字符串存入code数组中while(code[0]!='#') for (i=0;i { m=0; //m为想同编码个数的计数器 for (k=hcd[i].start,j=0;k<=n;k++,j++) //j为记录所存储这个字符的编码个数 { if(code[j]==hcd[i].cd[k]) //当有相同编码时m值加1 m++; } if(m==j) //当输入的字符串与所存储的编码字符串个数相等时则输出这个的data数据 { printf("%c",ht[i].data); for(x=0;code[x-1]!='#';x++) //把已经使用过的code数组里的字符串删除 { code[x]=code[x+j]; } } } } void main() { int n=26,i; char orz,back,flag=1; char str[]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'}; //初始化 int fnum[]={186,64,13,22,32,103,21,15,47,57,1,2,32,20,57,63,15,1,48,51,80,23,8,18,1,16}; //初始化 HTNode ht[M]; //建立结构体 HCode hcd[N]; //建立结构体 for (i=0;i ht[i].data=str[i]; ht[i].weight=fnum[i]; } while (flag) //菜单函数,当flag为0时跳出循环{ printf("\n"); printf(" **************************************"); printf("\n ** A---------------显示编码**"); printf("\n ** B---------------进行编码**"); printf("\n ** C---------------进行译码**"); printf("\n ** D---------------退出**\n"); printf(" ****************************************"); printf("\n"); printf(" 请输入选择的编号:"); scanf("%c",&orz); switch(orz) { case 'a': case 'A': system("cls"); //清屏函数 CreateHT(ht,n); CreateHCode(ht,hcd,n); DispHCode(ht,hcd,n); printf("\n按任意键返回..."); getch(); system("cls"); break; case 'b': case 'B': system("cls"); printf("请输入要进行编码的字符串(以#结束):\n"); editHCode(ht,hcd,n); printf("\n按任意键返回..."); getch(); system("cls"); break; case 'c': case 'C': system("cls"); DispHCode(ht,hcd,n); printf("请输入编码(以#结束):\n"); deHCode(ht,hcd,n); printf("\n按任意键返回..."); getch(); system("cls"); break; case 'd': case 'D': flag=0; break; default: system("cls"); } } } 实验三树的应用 一.实验题目: 树的应用——哈夫曼编码 二.实验内容: 利用哈夫曼编码进行通信可以大大提高信道的利用率,缩短信息传输的时间,降低传输成本。根据哈夫曼编码的原理,编写一个程序,在用户输入结点权值的基础上求哈夫曼编码。 要求:从键盘输入若干字符及每个字符出现的频率,将字符出现的频率作为结点的权值,建立哈夫曼树,然后对各个字符进行哈夫曼编码,最后打印输出字符及对应的哈夫曼编码。 三、程序源代码: #include 算法与数据结构课程设计哈夫曼编码/译码器设计 学生姓名: 学号: 专业:(计算机科学与技术) 年级:(大二) 指导教师:(汪洋) 2009年6月19日 哈夫曼编码/译码器 问题描述: 利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本,但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道)每端都需要一个完整的编/译码系统。试为这样的信息收发站写一哈夫曼编/译码系统。 基本要求: I:初始化(Initialization)。从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件hfmTree中。 E:编码(Encoding)。利用已建好的哈夫曼树(如不在内存,则从文件hfmTree中读入),对文件ToBeTran中的正文进行编码,然后将结果存入文件CodeFile中。 D:译码(Decoding)。利用已建好的哈夫曼树将文件CodeFile中的代码进行译码,结果存入文件TextFile中。 P:打印代码文件(Print)。将文件CodeFile以紧凑格式显示在终端上,每行50个代码。同时将此字符形式的编码文件写入文件CodePrin中。 T:打印哈夫曼树(Tree printing)。将已在中的哈夫曼树以直观的方式(树或凹入表形式)显示在终端上,同时将此字符形式的哈夫曼树写入文件TreePrint中。 大体解题思路: (1)对输入的一段欲编码的字符串进行统计各个字符出现的次数,并它们转化为权值{w1,w2,……,wN}构成n棵二叉树的集合F={T1,T2,……,Tn}把它们保存到结构体数组HT[n]中,其中{Ti是按它们的ASCⅡ码值先后排序。其中每棵二叉树Ti中只有一个带权为Wi的根结点的权值为其左、右子树上根结点的权值之和。 (2)在HT[1..i]中选取两棵根结点的权值最小且没有被选过的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为左、右子树上根结点的权值之和。 (3)哈夫曼树已经建立后,从叶子到根逆向求每一个字符的哈夫曼编码。 概要设计: 实现的功能:1.查看原文(showpassage()),2.字符统计(showdetail()), 数据结构课程设计设计题目:哈夫曼树编码译码 目录 第一章需求分析 (1) 第二章设计要求 (1) 第三章概要设计 (2) (1)其主要流程图如图1-1所示。 (3) (2)设计包含的几个方面 (4) 第四章详细设计 (4) (1)①哈夫曼树的存储结构描述为: (4) (2)哈弗曼编码 (5) (3)哈弗曼译码 (7) (4)主函数 (8) (5)显示部分源程序: (8) 第五章调试结果 (10) 第六章心得体会 (12) 第七章参考文献 (12) 附录: (12) 在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视,哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。哈夫曼编码是一种编码方式,以哈夫曼树—即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。哈弗曼编码使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和各个叶子对应的字符的编码,这就是哈夫曼编码。哈弗曼译码输入字符串可以把它编译成二进制代码,输入二进制代码时可以编译成字符串。 第二章设计要求 对输入的一串电文字符实现哈夫曼编码,再对哈夫曼编码生成的代码串进行译码,输出电文字符串。通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。电报通信是传递文字的二进制码形式的字符串。但在信息传递时,总希望总长度能尽可能短,即采用最短码。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长度为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi 恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵哈夫曼树,此构造过程称为哈夫曼编码。设计实现的功能: (1) 哈夫曼树的建立; (2) 哈夫曼编码的生成; (3) 编码文件的译码。 数据结构课程设计哈夫曼编码-2 《数据结构与算法》课程设计 目录 一、前言 1.摘要 2.《数据结构与算法》课程设计任务书 二、实验目的 三、题目--赫夫曼编码/译码器 1.问题描述 2.基本要求 3.测试要求 4.实现提示 四、需求分析--具体要求 五、概要设计 六、程序说明 七、详细设计 八、实验心得与体会 前言 1.摘要 随着计算机的普遍应用与日益发展,其应用早已不局限于简单的数值运算,而涉及到问题的分析、数据结构框架的设计以及设计最短路线等复杂的非数值处理和操作。算法与数据结构的学习就是为以后利用计算机资源高效地开发非数值处理的计算机程序打下坚实的理论、方法和技术基础。 算法与数据结构旨在分析研究计算机加工的数据对象的特性,以便选择适当的数据结构和存储结构,从而使建立在其上的解决问题的算法达到最优。 数据结构是在整个计算机科学与技术领域上广泛被使用的术语。它用来反映一个数据的内部构成,即一个数据由那些成分数据构成,以什么方式构成,呈什么结构。数据结构有逻辑上的数据结构和物理上的数据结构之分。逻辑上的数据结构反映成分数据之间的逻辑关系,而物理上的数据结构反映成分数据在计算机内部的存储安排。数据结构是数据存在的形式。 《数据结构》主要介绍一些最常用的数据结构,阐明各种数据结构内在的逻辑关系,讨论其在计算机中的存储表示,以及在其上进行各种运算时的实现算法,并对算法的效率进行简单的分析和讨论。数据结构是介于数学、计算机软件和计算机硬件之间的一门计算机专业的核心课程,它是计算机程序设计、数据库、操作系统、编译原理及人工智能等的重要基础,广泛的应用于信息学、系统工程等各种领域。 学习数据结构是为了将实际问题中所涉及的对象在计算机中表示出来并对它们进行处理。通过课程设计可以提高学生的思维能力,促进学生的综合应用能力和专业素质的提高。 #include #include"stdafx.h" #include"stdio.h" #include"conio.h" #include 《数据结构与算法》课程设计(2009/2010学年第二学期第20周) 指导教师:王老师 班级:计算机科学与技术(3)班 学号: 姓名: 《数据结构与算法》课程设计 目录 一、前言 1.摘要 2.《数据结构与算法》课程设计任务书 二、实验目的 三、题目--赫夫曼编码/译码器 1.问题描述 2.基本要求 3.测试要求 4.实现提示 四、需求分析--具体要求 五、概要设计 六、程序说明 七、详细设计 八、实验心得与体会 前言 1.摘要 随着计算机的普遍应用与日益发展,其应用早已不局限于简单的数值运算,而涉及到问题的分析、数据结构框架的设计以及设计最短路线等复杂的非数值处理和操作。算法与数据结构的学习就是为以后利用计算机资源高效地开发非数值处理的计算机程序打下坚实的理论、方法和技术基础。 算法与数据结构旨在分析研究计算机加工的数据对象的特性,以便选择适当的数据结构和存储结构,从而使建立在其上的解决问题的算法达到最优。 数据结构是在整个计算机科学与技术领域上广泛被使用的术语。它用来反映一个数据的内部构成,即一个数据由那些成分数据构成,以什么方式构成,呈什么结构。数据结构有逻辑上的数据结构和物理上的数据结构之分。逻辑上的数据结构反映成分数据之间的逻辑关系,而物理上的数据结构反映成分数据在计算机内部的存储安排。数据结构是数据存在的形式。 《数据结构》主要介绍一些最常用的数据结构,阐明各种数据结构内在的逻辑关系,讨论其在计算机中的存储表示,以及在其上进行各种运算时的实现算法,并对算法的效率进行简单的分析和讨论。数据结构是介于数学、计算机软件和计算机硬件之间的一门计算机专业的核心课程,它是计算机程序设计、数据库、操作系统、编译原理及人工智能等的重要基础,广泛的应用于信息学、系统工程等各种领域。 学习数据结构是为了将实际问题中所涉及的对象在计算机中表示出来并对它们进行处理。通过课程设计可以提高学生的思维能力,促进学生的综合应用能力和专业素质的提高。 2.《数据结构与算法》课程设计任务书 《数据结构与算法》是计算机专业重要的核心课程之一,在计算机专业的学习过程中占有非常重要的地位。《数据结构与算法课程设计》就是要运用本课程以及到目前为止的有关课程中的知识和技术来解决实际问题。特别是面临非数值计算类型的应用问题时,需要选择适当的数据结构,设计出满足一定时间和空间限制的有效算法。 本课程设计要求同学独立完成一个较为完整的应用需求分析。并在设计和编写具有一定规模程序的过程中,深化对《数据结构与算法》课程中基本概念、理论和方法的理解;训练综合运用所学知识处理实际问题的能力,强化面向对象的程序设计理念;使自己的程序设计与调试水平有一个明显的提高。 #include 课程设计任务书 题目:基于哈夫曼编码的图像编解码系统设计及实现 初始条件: 计算机 Windows8操作系统 MATLAB7.8.0软件 要求完成的主要任务: 设计哈夫曼编码的图像编解码系统、利用软件编写程序、仿真实现 时间安排: 第1-18周:理论讲解 第19周:理论设计,实验室安装调试以及撰写设计报告 答辩: 时间:7月2日 地点: 鉴主15楼通信实验室四 指导教师签名:年月日 系主任(或责任教师)签名:年月日 目录 目录........................................................................................................................ I矚慫润厲钐瘗睞枥庑赖。摘要....................................................................................................................... I I聞創沟燴鐺險爱氇谴净。ABSTRACT ......................................................................................................... I II残骛楼諍锩瀨濟溆塹籟。1引言..................................................................................................................... 1酽锕极額閉镇桧猪訣锥。 1.1图像数据压缩的目的.............................................................................. 1彈贸摄尔霁毙攬砖卤庑。 1.2图像数据压缩的原理.............................................................................. 1謀荞抟箧飆鐸怼类蒋薔。 1.3常用的压缩编码方法.............................................................................. 3厦礴恳蹒骈時盡继價骚。2哈夫曼编码......................................................................................................... 3茕桢广鳓鯡选块网羈泪。 2.1 哈夫曼编码简介..................................................................................... 3鹅娅尽損鹌惨歷茏鴛賴。 2.2哈夫曼编码步骤...................................................................................... 3籟丛妈羥为贍偾蛏练淨。 2.3 哈夫曼编码的缺点................................................................................. 5預頌圣鉉儐歲龈讶骅籴。3基于哈夫曼编码的图像编解码系统的程序设计............................................. 6渗釤呛俨匀谔鱉调硯錦。 3.1 分块程序设计分析................................................................................. 6铙誅卧泻噦圣骋贶頂廡。 3.2主程序...................................................................................................... 8擁締凤袜备訊顎轮烂蔷。 3.3程序函数.................................................................................................. 9贓熱俣阃歲匱阊邺镓騷。 3.3.1编码函数....................................................................................... 9坛摶乡囂忏蒌鍥铃氈淚。 3.3.2解码函数..................................................................................... 12蜡變黲癟報伥铉锚鈰赘。 3.3.3符号概率计算函数..................................................................... 14買鲷鴯譖昙膚遙闫撷凄。 3.3.4节点添加函数............................................................................. 14綾镝鯛駕櫬鹕踪韦辚糴。 3.3.5解码返回符号函数..................................................................... 15驅踬髏彦浃绥譎饴憂锦。4系统仿真结果................................................................................................... 15猫虿驢绘燈鮒诛髅貺庑。 4.1程序运行结果........................................................................................ 15锹籁饗迳琐筆襖鸥娅薔。 4.2 程序运行结果分析............................................................................... 17構氽頑黉碩饨荠龈话骛。 5.总结................................................................................................................... 18輒峄陽檉簖疖網儂號泶。参考文献.............................................................................................................. 19尧侧閆繭絳闕绚勵蜆贅。 福建农林大学计算机与信息学院 数据结构课程设计 设计:哈夫曼编译码器 姓名:韦邦权 专业:2013级计算机科学与技术 学号:13224624 班级:13052316 完成日期:2013.12.28 1 哈夫曼编译码器 一、需求分析 在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视,哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。哈夫曼编码是一种编码方式,以哈夫曼树—即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。哈夫曼编码使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和 各个叶子对应的字符的编码,这就是哈夫曼编码。哈夫曼译码输入字符串可以把它编译成二进制代码,输入二进制代码时可以编译成字符串。 二、设计要求 对输入的一串电文字符实现哈夫曼编码,再对哈夫曼编码生成的2 代码串进行译码,输出电文字符串。通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。电报通信是传递文字的二进制码形式的字符串。但在信息传递时,总希望总长度能尽可能短,即采用最短码。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长度为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi 恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵哈夫曼树,此构造过程称为哈夫曼编码。设计实现的功能: (1) 哈夫曼树的建立; (2) 哈夫曼编码的生成; (3) 编码文件的译码。 三、概要设计 哈夫曼编\译码器的主要功能是先建立哈夫曼树,然后利用建好的哈夫曼树生成哈夫曼编码后进行译码。 在数据通信中,经常需要将传送的文字转换成由二进制字符0、1组成的二进制串,称之为编码。构造一棵哈夫曼树,规定哈夫曼树中的左分之代表0,右分支代表1,则从根节点到每个叶子节点所经过的 目录 摘要………………………………………………………………………..………………II Abstract …………………………………………………………………………..………... II 第一章课题描述 (1) 1.1 问题描述 (1) 1.2 需求分析…………………………………………………..…………………………… 1 1.3 程序设计目标…………………………………………………………………………… 第二章设计简介及设计方案论述 (2) 2.1 设计简介 (2) 2.2 设计方案论述 (2) 2.3 概要设计 (2) 第三章详细设计 (4) 3.1 哈夫曼树 (4) 3.2哈夫曼算 法 (4) 3.2.1基本思 想 (4) 3.2.2存储结 构 (4) 3.3 哈夫曼编码 (5) 3.4 文件I/O 流 (6) 3.4.1 文件流 (6) 3.4.2 文件的打开与关闭 (7) 3.4.3 文件的读写 (7) 3..5 C语言文件处理方式…………………………………………………………………… 第四章设计结果及分析 (8) 4.1 设计系统功能 (8) 4.2 进行系统测试 (8) 总结 (13) 致谢 (14) 参考文献 (15) 附录主要程序代码 (16) 摘要 在这个信息高速发展的时代,每时每刻都在进行着大量信息的传递,到处都离不开信息,它贯穿在人们日常的生活生产之中,对人们的影响日趋扩大,而利用哈夫曼编码 进行通信则可以大大提高信道利用率,缩短信息传输时间,降低传输成本。在生产中则可以更大可能的降低成本从而获得更大的利润,这也是信息时代发展的趋势所在。本课程设计的目的是使学生学会分析待加工处理数据的特性,以便选择适当的逻辑结构、存储结构以及进行相应的算法设计。学生在学习数据结构和算法设计的同时,培养学生的抽象思维能力、逻辑推理能力和创造性的思维方法,增强分析问题和解决问题的能力。此次设计的哈夫曼编码译码系统,实现对给定报文的编码和译码,并且任意输入报文可以实现频数的统计,建立哈夫曼树以及编码译码的功能。这是一个拥有完备功能的系统程序,对将所学到的知识运用到实践中,具有很好的学习和研究价值. 关键词:信息;通讯;编码;译码;程序 Abstract This is a date that information speeding highly development and transmit 实验名称:实验六费诺编码 一、实验目的: 加深对赫夫曼编码的理解及其具体的实现过程 二、实验内容与原理: 1.完成赫夫曼的编码 2.计算平均码长及编码效率 三、实验步骤 根据赫夫曼编码的步骤完成该编码 四、实验数据及结果分析(可附程序运行截图) 编码的结果: 五、代码附录 %哈夫曼编码的MATLAB实现(基于0、1编码):clc; clear; A=[0.25 0.25 0.2 0.15 0.1 0.05];%信源消息的概率序列A=fliplr(sort(A));%按降序排列 T=A; [m,n]=size(A); B=zeros(n,n-1);%空的编码表4*5(矩阵) for i=1:n B(i,1)=T(i);%生成编码表的第一列 end r=B(i,1)+B(i-1,1);%最后两个元素相加 T(n-1)=r; T(n)=0; T=fliplr(sort(T)); t=n-1;%t=4 for j=2:n-1%生成编码表的其他各列 for i=1:t B(i,j)=T(i); end K=find(T==r);%函数用于返回所需要元素的所在位置 B(n,j)=K(end);%从第二列开始,每列的最后一个元素记录特征元素在%该列的位置 r=(B(t-1,j)+B(t,j));%最后两个元素相加 T(t-1)=r; T(t)=0; T=fliplr(sort(T)); t=t-1; end B;%输出编码表 END1=sym('[0,1]');%给最后一列的元素编码 END=END1; t=3; d=1; for j=n-2:-1:1%从倒数第二列开始依次对各列元素编码 for i=1:t-2 if i>1 & B(i,j)==B(i-1,j) d=d+1; else d=1; end B(B(n,j+1),j+1)=-1; temp=B(:,j+1); x=find(temp==B(i,j)); END(i)=END1(x(d)); end y=B(n,j+1); END(t-1)=[char(END1(y)),'0']; END(t)=[char(END1(y)),'1']; t=t+1; END1=END; end A%排序后的原概率序列 END%编码结果 for i=1:n [a,b]=size(char(END(i))); L(i)=b; end disp('平均码长:;'); avlen=sum(L.*A)%平均码长 H1=log2(A); H=-A*(H1')%熵 《用哈夫曼编码实现文件压缩》 实验报告 课程名称数据结构B 实验学期 2017 至 2018 学年第一学期学生所在院部计算机学院 年级 2016 专业班级信管B162 学生姓名学号 成绩评定: 1、工作量: A(),B(),C(),D(),F( ) 2、难易度:A(),B(),C(),D(),F( ) 3、答辩情况: 基本操作:A(),B(),C(),D(),F( ) 代码理解:A(),B(),C(),D(),F( ) 4、报告规范度:A(),B(),C(),D(),F( ) 5、学习态度:A(),B(),C(),D(),F( )总评成绩:_________________________________ 指导教师: 兰芸 用哈夫曼编码实现文件压缩 1、了解文件的概念。 2、掌握线性链表的插入、删除等算法。 3、掌握Huffman树的概念及构造方法。 4、掌握二叉树的存储结构及遍历算法。 5、利用Huffman树及Huffman编码,掌握实现文件压缩的一般原理。 微型计算机、Windows 7操作系统、Visual C++6.0软件 输入的字符创建Huffman树,并输出各字符对应的哈夫曼编码。 五.系统设计 输入字符的个数和各个字符以及权值,将每个字符的出现频率作为叶子结点构建Huffman树,规定哈夫曼树的左分支为0,右分支为1,则从根结点到每个叶子结点所经过的分支对应的0和1组成的序列便为该结点对应字符的哈夫曼编码。 流程图如下 1.输入哈夫曼字数及相应权值 相应代码 int main() { HuffmanTree HTree; HuffmanCode HCode; int *w, i; int n,wei; //编码个数及权值 printf("请输入需要哈夫曼编码的字符个数:"); scanf("%d",&n); w=(int*)malloc((n+1)*sizeof(int)); for(i=1; i<=n;i++) { printf("请输入第%d字符的权值:",i); fflush(stdin); scanf("%d",&wei); w[i]=wei; } HuffmanCoding(&HTree,&HCode,w,n); return 1; } 2.输出HT初态(每个字符的权值) 课程设计 (数据结构) 哈夫曼树和哈夫曼编码 二○○九年六月二十六日课程设计任务书及成绩评定 课题名称表达式求值哈夫曼树和哈夫曼编码 Ⅰ、题目的目的和要求: 巩固和加深对数据结构的理解,通过上机实验、调试程序,加深对课本知识的理解,最终使学生能够熟练应用数据结构的知识写程序。 (1)通过本课程的学习,能熟练掌握几种基本数据结构的基本操作。 (2)能针对给定题目,选择相应的数据结构,分析并设计算法,进而给出问题的正确求解过程并编写代码实现。 Ⅱ、设计进度及完成情况 Ⅲ、主要参考文献及资料 [1] 严蔚敏数据结构(C语言版)清华大学出版社 1999 [2] 严蔚敏数据结构题集(C语言版)清华大学出版社 1999 [3] 谭浩强 C语言程序设计清华大学出版社 [4] 与所用编程环境相配套的C语言或C++相关的资料 Ⅳ、成绩评定: 设计成绩:(教师填写) 指导老师:(签字) 二○○九年六月二十六日 目录 第一章概述 (1) 第二章系统分析 (2) 第三章概要设计 (3) 第四章详细设计及实现代码 (8) 第五章调试过程中的问题及系统测试情况 (12) 第六章结束语 (13) 参考文献 (13) 第一章概述 课程设计是实践性教学中的一个重要环节,它以某一课程为基础,可以涉及和课程相关的各个方面,是一门独立于课程之外的特殊课程。课程设计是让同学们对所学的课程更全面的学习和应用,理解和掌握课程的相关知识。《数据结构》是一门重要的专业基础课,是计算机理论和应用的核心基础课程。 数据结构课程设计,要求学生在数据结构的逻辑特性和物理表示、数据结构的选择和应用、算法的设计及其实现等方面,加深对课程基本内容的理解。同时,在程序设计方法以及上机操作等基本技能和科学作风方面受到比较系统和严格的训练。 在这次的课程设计中我选择的题目是表达式求值和哈夫曼树及哈夫曼编码。这里我们介绍一种简单直观、广为使用的算法,通常称为“算符优先法”。哈夫曼树又称最优树,是一类带权路径长度最短的树,有着广泛的应用。 功能:表达式求值以栈为存储结构,实现输入的表达式的求值; 哈夫曼树和哈夫曼编码是实现最优二叉树的构造,并能通过最优二叉树进行编码,应用到电文中,并以此来译码。 利用键盘,输入相应的数值,通过程序实现表达式的求值;再利用键盘,输入各个顶点,通过程序构造最优二叉树以及为此编码。 题目:哈夫曼编码器 班级:031021班姓名:李鑫学号:03102067 完成日期:2011/12 1. 问题描述 利用赫夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。这要求在发送端通过一个编码系统对待传输数据预先编码,在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。试为这样的信息收发站编写一个赫夫曼码的编/译码系统。 2.基本要求 一个完整的系统应具有以下功能: (1) I:初始化(Initialization)。从终端读入字符集大小n,以及n个字符和n个权值,建立赫夫曼树,并将它存于文件hfmTree中。 (2) E:编码(Encoding)。利用已建好的赫夫曼树(如不在内存,则从文件hfmTree中读入),对文件ToBeTran中的正文进行编码,然后将结果存入文件CodeFile中。 (3) D:译码(Decoding)。利用已建好的赫夫曼树将文件CodeFile中的代码进行译码,结果存入文件Textfile中。 以下为选做: (4) P:印代码文件(Print)。将文件CodeFile以紧凑格式显示在终端上,每行50个代码。同时将此字符形式的编码文件写入文件CodePrin中。 (5) T:印赫夫曼树(Tree printing)。将已在内存中的赫夫曼树以直观的方式(比如树)显示在终端上,同时将此字符形式的赫夫曼树写入文件TreePrint 中。 3.测试 (1)利用教科书例6-2中的数据调试程序。 (2) 用下表给出的字符集和频度的实际统计数据建立赫夫曼树,并实现以下报文的编码和译码:“THIS PROGRAME IS MY FA VORITE”。 字符 A B C D E F G H I J K L M 频度186 64 13 22 32 103 21 15 47 57 1 5 32 20 字符N O P Q R S T U V W X Y Z 频度57 63 15 1 48 51 80 23 8 18 1 16 1 4.实现提示 (1) 编码结果以文本方式存储在文件Codefile中。 (2) 用户界面可以设计为“菜单”方式:显示上述功能符号,再加上“Q”,表示退出运行Quit。请用户键入一个选择功能符。此功能执行完毕后再显示此菜单,直至某次用户选择了“Q”为止。 (3) 在程序的一次执行过程中,第一次执行I,D或C命令之后,赫夫曼树已经在内存了,不必再读入。每次执行中不一定执行I命令,因为文件hfmTree可能早已建好。 湖南科技学院 课程设计报告 课程名称:数据结构课程设计 课程设计题目:哈夫曼编码 系:数学与计算科学系 专业:信息与计算科学 年级、班:信计0901 姓名:郭如华 学号:200905002145 指导教师:牛志毅 职称:讲师 2011年12月 目录 1 问题描述 (3) 2 基本要求 (3) 3 测试数据 (3) 4 算法思想 (3) 5 模块划分 (3) 6 数据结构 (3) 7 源程序 (4) 8 测试情况 (9) 9 设计总结 (9) 10参考资料 (9) 1 问题描述 设计一个哈夫曼编码系统,对文档中的报文进行编码,输出这段报文的哈夫曼编码,并且可以对输入的哈夫曼编码进行译码。 2 基本要求 从文档中读取报文(如"what did you do that made you so happy")进行编码输出这段报文的哈夫曼编码。 3 测试数据 what did you do that made you so happy 4算法思想 ①:从文件中读取lei.txt并到数组z(保存所有字符的种类),读取data,txt存到数组ch(保存统计频数的一个样本)。 ②:对数组z和数组ch进行比较统计出每个字符出现的频数,以频数代替权值,并把权值赋值到ht.weight的的数组中。 ③:利用权值创建哈夫曼树。 ④:利用哈夫曼树求的哈夫曼编码。把lei.txt的数据赋值到hcd.ch中,把编好的哈夫曼编码赋值到hcd.code,则hcd这个数组就是一个哈夫曼编码的集合,hcd.ch 对应的下标就是这个字符所对应的哈夫曼编码。 ⑤:输入要编码的字符,保存到ch数组,把ch数组的ch[j]元素逐个与hcd[i].ch 比较找出下标i,则hcd[i].code为ch[j]元素的哈夫曼编码。 ⑥:输入要译码的哈夫曼编码lcd,逐个与hcd[i].code比较,找出下标i,则hcd[i].ch 为lcd所对应的字符。 5 模块划分 ①:void inithuffmantree(huffmantree ht);/*初始化哈夫曼树*/ ②:void tongji(huffmantree ht,huffmancode hcd,char *ch,char *z);/*统计权值*/ ③:void selectmin(huffmantree ht, int i, int *p1, int *p2);/*选择最小的权值*/ ④:void createhuffmantree(huffmantree ht) ;/*创建哈夫曼树*/ ⑤:void huffmancodes(huffmantree ht,huffmancode hcd,char *z) ;/*利用哈夫曼树求哈夫曼编码*/ ⑥:void bianma(huffmancode hcd);/*对输入的字符进行编码*/ ⑦:void yima(huffmancode hcd);/*对输入的哈夫曼编码进行译码*/ 6 数据结构 typedef struct { int weight; int lchild,rchild,parent; }htnode; typedef htnode huffmantree[m+1];定义哈夫曼树的结构类型。 电子科技大学 实验报告 课程名称:数据结构与算法 学生姓名:陈*浩 学号:************* 点名序号: *** 指导教师:钱** 实验地点:基础实验大楼 实验时间: 2014-2015-2学期 信息与软件工程学院 实验报告(二) 学生姓名:陈**浩学号:*************指导教师:钱** 实验地点:科研教学楼A508实验时间:一、实验室名称:软件实验室 二、实验项目名称:数据结构与算法—树 三、实验学时:4 四、实验原理: 霍夫曼编码(Huffman Coding)是一种编码方式,是一种用于无损数据压缩的熵编码(权编码)算法。1952年,David A. Huffman在麻省理工攻读博士时所发明的。 在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。 例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。 霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。 可以证明霍夫曼树的WPL是最小的。哈夫曼编码算法实现完整版
哈夫曼编码程序设计
哈夫曼树编码译码实验报告(DOC)
数据结构课程设计哈夫曼编码-2
数据结构哈夫曼树的实现
哈夫曼树的编码和译码
数据结构课程设计哈夫曼编码(DOC)
赫夫曼树的编码译码
基于哈夫曼编码的图像编解码系统设计及实现
完整word版数据结构课程设计:电文编码译码哈夫曼编码
哈夫曼编码译码系统课程设计实验报告(含源代码C++_C语言)
实验六_赫夫曼编码
哈夫曼树及编码综合实验报告
哈夫曼树和哈夫曼编码(数据结构程序设计)
数据结构课程设计哈夫曼编码
哈夫曼编码课程设计
哈夫曼树及其操作-数据结构实验报告(2)
- 数据结构哈夫曼树
- 数据结构课程设计哈夫曼树及编码
- 哈夫曼树编码实验报告
- 数据结构实验哈夫曼树编码
- 数据结构哈夫曼树的实现
- 2020年最新数据结构哈夫曼编码实验报告
- 北京邮电大学信通院数据结构实验三——哈夫曼树实验报告
- 哈夫曼树编码译码实验报告(DOC)
- 数据结构实验报告(哈夫曼树)
- 数据结构哈夫曼编码实验报告
- 数据结构实验三哈夫曼树实验报告
- 数据结构课程设计 哈夫曼树及编码
- 数据结构哈夫曼树
- 哈工大数据结构大作业——哈夫曼树生成、编码、遍历
- 哈夫曼树编码译码实验报告(DOC)
- 数据结构哈夫曼编码实验报告
- 数据结构 哈夫曼树编码译码 课程设计 实验报告
- 数据结构课程设计哈夫曼编码(DOC)
- 数据结构课件哈夫曼树
- 完整word版数据结构课程设计:电文编码译码哈夫曼编码