概率统计分布表(常用)
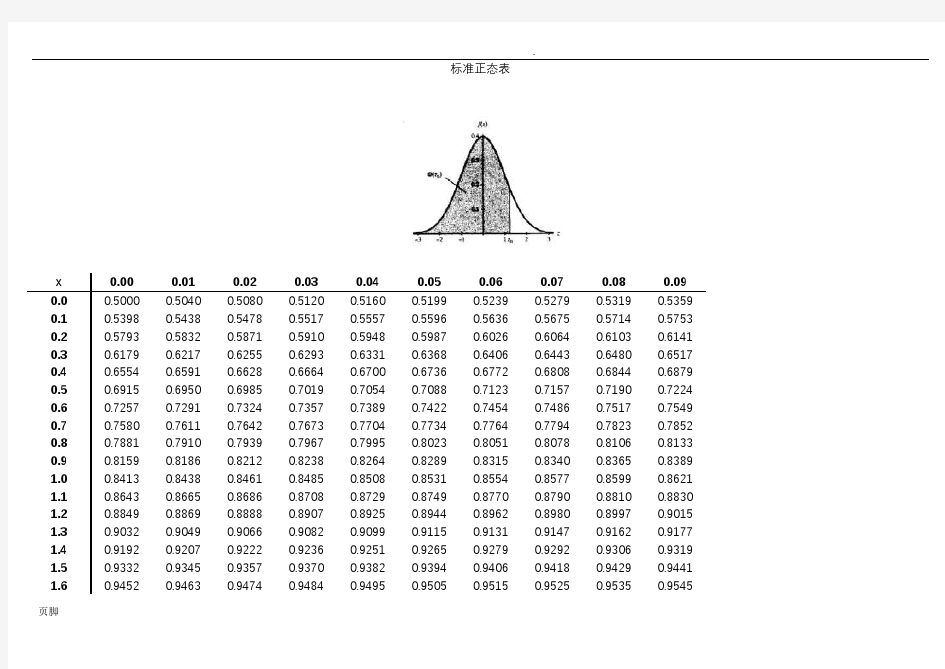
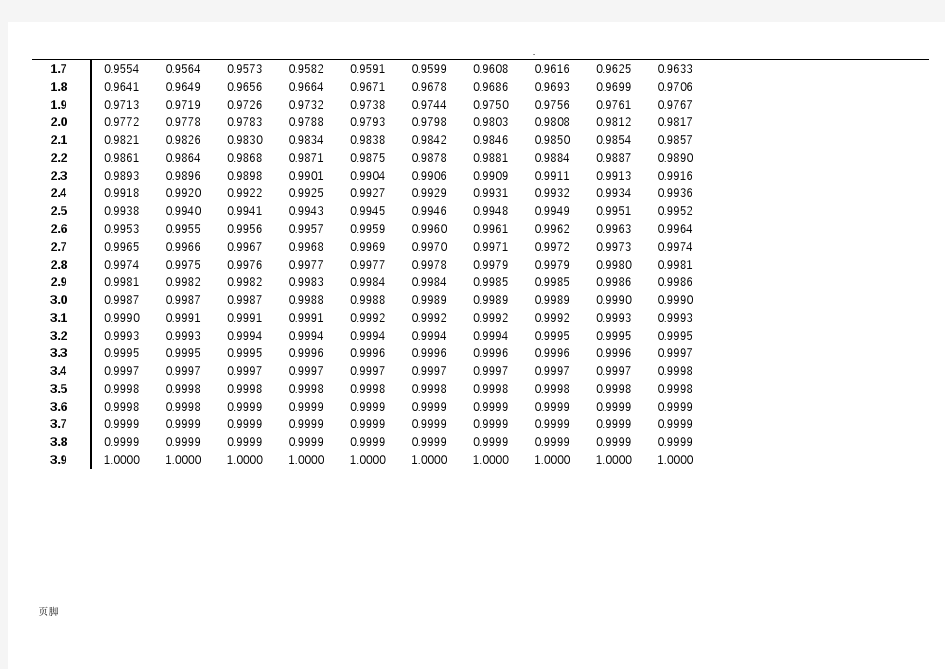
页脚标准正态表
x 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359 0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753 0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141 0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517 0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879 0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224 0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549 0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852 0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133
0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389
1.0 0.8413 0.8438 0.8461 0.8485 0.8508 0.8531 0.8554 0.8577 0.8599 0.8621 1.1 0.8643 0.8665 0.8686 0.8708 0.8729 0.8749 0.8770 0.8790 0.8810 0.8830 1.2 0.8849 0.8869 0.8888 0.8907 0.8925 0.8944 0.8962 0.8980 0.8997 0.9015 1.3 0.9032 0.9049 0.9066 0.9082 0.9099 0.9115 0.9131 0.9147 0.9162 0.9177 1.4 0.9192 0.9207 0.9222 0.9236 0.9251 0.9265 0.9279 0.9292 0.9306 0.9319 1.5 0.9332 0.9345 0.9357 0.9370 0.9382 0.9394 0.9406 0.9418 0.9429 0.9441 1.6 0.9452 0.9463 0.9474 0.9484 0.9495 0.9505 0.9515 0.9525 0.9535 0.9545
页脚
n\p 0.005 0. 0.025 0.050 0.100 0.250 0.750 0.900 0.950 0.975 0.990 0.995
1 0.0000 0.000
2 0.0010 0.0039 0.0158 0.1015 1.323
3 2.7055 3.8415 5.0239 6.6349 7.8794
2 0.0100 0.0201 0.0506 0.1026 0.2107 0.5754 2.7726 4.6052 5.9915 7.3778 9.210
3 10.5966
3 0.0717 0.1148 0.2158 0.3518 0.584
4 1.212
5 4.1083 6.2514 7.8147 9.3484 11.3449 12.8382
4 0.2070 0.2971 0.4844 0.7107 1.0636 1.9226 5.3853 7.7794 9.4877 11.1433 13.2767 14.8603
5 0.4117 0.5543 0.8312 1.1455 1.6103 2.674
6 6.625
7 9.2364 11.0705 12.8325 15.0863 16.7496
6 0.675
7 0.8721 1.2373 1.6354 2.2041 3.4546 7.840
8 10.6446 12.5916 14.4494 16.811
9 18.5476
7 0.9893 1.2390 1.6899 2.1673 2.8331 4.2549 9.0371 12.0170 14.0671 16.0128 18.4753 20.2777
8 1.3444 1.6465 2.1797 2.7326 3.4895 5.0706 10.2189 13.3616 15.5073 17.5345 20.0902 21.9550
9 1.7349 2.0879 2.7004 3.3251 4.1682 5.8988 11.3888 14.6837 16.9190 19.0228 21.6660 23.5894
10 2.1559 2.5582 3.2470 3.9403 4.8652 6.7372 12.5489 15.9872 18.3070 20.4832 23.2093 25.1882
11 2.6032 3.0535 3.8157 4.5748 5.5778 7.5841 13.7007 17.2750 19.6751 21.9200 24.7250 26.7568
12 3.0738 3.5706 4.4038 5.2260 6.3038 8.4384 14.8454 18.5493 21.0261 23.3367 26.2170 28.2995
13 3.5650 4.1069 5.0088 5.8919 7.0415 9.2991 15.9839 19.8119 22.3620 24.7356 27.6882 29.8195
14 4.0747 4.6604 5.6287 6.5706 7.7895 10.1653 17.1169 21.0641 23.6848 26.1189 29.1412 31.3193
15 4.6009 5.2293 6.2621 7.2609 8.5468 11.0365 18.2451 22.3071 24.9958 27.4884 30.5779 32.8013
16 5.1422 5.8122 6.9077 7.9616 9.3122 11.9122 19.3689 23.5418 26.2962 28.8454 31.9999 34.2672
17 5.6972 6.4078 7.5642 8.6718 10.0852 12.7919 20.4887 24.7690 27.5871 30.1910 33.4087 35.7185
18 6.2648 7.0149 8.2307 9.3905 10.8649 13.6753 21.6049 25.9894 28.8693 31.5264 34.8053 37.1565 页脚
页脚
页脚T分布
n\p 0.750 0.800 0.850 0.900 0.950 0.975 0.990 0.995 0.9975 0.9990 0.9995
1 1.0000 1.3764 1.9626 3.0777 6.3138 12.706
2 31.8205 63.6567 127.321
3 318.3088 636.6192
2 0.8165 1.0607 1.3862 1.8856 2.9200 4.3027 6.9646 9.9248 14.0890 22.3271 31.5991
3 0.7649 0.9785 1.2498 1.6377 2.353
4 3.1824 4.5407 5.8409 7.4533 10.214
5 12.9240
4 0.7407 0.9410 1.1896 1.5332 2.1318 2.7764 3.7469 4.6041 5.5976 7.1732 8.6103
5 0.7267 0.9195 1.1558 1.4759 2.0150 2.570
6 3.3649 4.0321 4.7733 5.8934 6.8688
6 0.7176 0.905
7 1.1342 1.439
8 1.9432 2.446
9 3.1427 3.7074 4.3168 5.2076 5.9588
7 0.7111 0.8960 1.1192 1.4149 1.8946 2.3646 2.9980 3.4995 4.0293 4.7853 5.4079
8 0.7064 0.8889 1.1081 1.3968 1.8595 2.3060 2.8965 3.3554 3.8325 4.5008 5.0413
9 0.7027 0.8834 1.0997 1.3830 1.8331 2.2622 2.8214 3.2498 3.6897 4.2968 4.7809
10 0.6998 0.8791 1.0931 1.3722 1.8125 2.2281 2.7638 3.1693 3.5814 4.1437 4.5869
11 0.6974 0.8755 1.0877 1.3634 1.7959 2.2010 2.7181 3.1058 3.4966 4.0247 4.4370
12 0.6955 0.8726 1.0832 1.3562 1.7823 2.1788 2.6810 3.0545 3.4284 3.9296 4.3178
13 0.6938 0.8702 1.0795 1.3502 1.7709 2.1604 2.6503 3.0123 3.3725 3.8520 4.2208
14 0.6924 0.8681 1.0763 1.3450 1.7613 2.1448 2.6245 2.9768 3.3257 3.7874 4.1405
15 0.6912 0.8662 1.0735 1.3406 1.7531 2.1314 2.6025 2.9467 3.2860 3.7328 4.0728
页脚
页脚
76 0.6777 0.8464 1.0436 1.2928 1.6652 1.9917 2.3764 2.6421 2.8913 3.2010 3.4232
77 0.6777 0.8463 1.0435 1.2926 1.6649 1.9913 2.3758 2.6412 2.8902 3.1995 3.4214
78 0.6776 0.8463 1.0434 1.2925 1.6646 1.9908 2.3751 2.6403 2.8891 3.1980 3.4197
79 0.6776 0.8462 1.0433 1.2924 1.6644 1.9905 2.3745 2.6395 2.8880 3.1966 3.4180
80 0.6776 0.8461 1.0432 1.2922 1.6641 1.9901 2.3739 2.6387 2.8870 3.1953 3.4163
81 0.6775 0.8461 1.0431 1.2921 1.6639 1.9897 2.3733 2.6379 2.8860 3.1939 3.4147
82 0.6775 0.8460 1.0430 1.2920 1.6636 1.9893 2.3727 2.6371 2.8850 3.1926 3.4132
83 0.6775 0.8460 1.0429 1.2918 1.6634 1.9890 2.3721 2.6364 2.8840 3.1913 3.4116
84 0.6774 0.8459 1.0429 1.2917 1.6632 1.9886 2.3716 2.6356 2.8831 3.1901 3.4102
85 0.6774 0.8459 1.0428 1.2916 1.6630 1.9883 2.3710 2.6349 2.8822 3.1889 3.4087
86 0.6774 0.8458 1.0427 1.2915 1.6628 1.9879 2.3705 2.6342 2.8813 3.1877 3.4073
87 0.6773 0.8458 1.0426 1.2914 1.6626 1.9876 2.3700 2.6335 2.8804 3.1866 3.4059
88 0.6773 0.8457 1.0426 1.2912 1.6624 1.9873 2.3695 2.6329 2.8795 3.1854 3.4045
89 0.6773 0.8457 1.0425 1.2911 1.6622 1.9870 2.3690 2.6322 2.8787 3.1843 3.4032
90 0.6772 0.8456 1.0424 1.2910 1.6620 1.9867 2.3685 2.6316 2.8779 3.1833 3.4019 100 0.6770 0.8452 1.0418 1.2901 1.6602 1.9840 2.3642 2.6259 2.8707 3.1737 3.3905 120 0.6765 0.8446 1.0409 1.2886 1.6577 1.9799 2.3578 2.6174 2.8599 3.1595 3.3735
F分布
n\m 1 2 3 5 6 7 8 10 15 20 30
1 39.86 49.50 53.59 55.83 57.24 58.91 59.44 59.86 61.2
2 61.74 62.26
2 8.5
3 9.00 9.16 9.2
4 9.29 9.3
5 9.37 9.38 9.42 9.44 9.4
6 页脚
P= 0.99
页脚
页脚
页脚
页脚
页脚
页脚
页脚
页脚
页脚
Excel公式
1.正态分布函数
Excel计算正态分布时,使用NORMDIST函数,其格式如下:
NORMDIST(a,μ,σ,累积)
其中,“累积”:若为TRUE,则输出分布函数值,即P{X≤a};
若为FALSE,则为概率密度函数值.
示例:已知X服从正态分布,μ=600,σ=100,求P{X≤500}.
输入公式
NORMDIST(500, 600, 100, TRUE)
得到的结果为0.158655,即P{X≤500}=0.158655.
2、正态分布函数的反函数
Excel计算正态分布函数的反函数使用NORMINV函数,
格式如下:NORMINV(p,μ,σ),此公式计算a,使P{X ≤a}=p
3标准正态分布反函数=NORMSINV(0.975)
3、t分布
Excel计算t分布的值,采用TDIST函数,
格式如下:TDIST(a,自由度,侧数)
其中,“侧数”:指明分布为单侧或双侧:
若为1,为单侧;此命令输出P{ T >a }
页脚
若为2,为双侧.此命令输出P{ |T| >a}
示例:设T服从自由度为24的t分布,求P(T>1.711).已知t=1.711,df=24,采用单侧,则T分布的值:TDIST(1.711,24,1)
得到0.05,即P(T > 1.711)=0.05.
4. t分布的反函数
Excel使用TINV函数得到t分布的反函数,
格式如下:TINV(α,自由度)
输出T 分布的α / 2 分位点:t_α/2_(n)
若求临界值tα(n),则使用公式=TINV(2*α, n)
5.返回F分布的函数是FDIST
FDIST(x,degrees_freedom1,degrees_freedom2)
函数FDIST 的计算公式为FDIST=P( F>x ),
5.F分布的反函数
FINV(probability,deg_freedom1,deg_freedom2)
已知probability=P( F>x ),求x
页脚
大学概率论与数理统计复习资料
第一章 随机事件及其概率 知识点:概率的性质 事件运算 古典概率 事件的独立性 条件概率 全概率与贝叶斯公式 常用公式 ) ()()()()()2(加法定理AB P B P A P B A P -+= ) ,,() ()(211 1 有限可加性两两互斥设n n i i n i i A A A A P A P ∑===) ,(0 )()()()()(互不相容时独立时与B A AB P B A B P A P AB P ==) ()()()()5(AB P A P B A P B A P -==-) () ()()()(时当A B B P A P B A P B A P ?-==-))0(,,()()/()()()6(211 >Ω=∑=i n n i i i A P A A A A B P A P B P 且的一个划分为其中全概率公式 ) ,,()] (1[1)(211 1 相互独立时n n i i n i i A A A A P A P ∏==--=) /()()/()()()4(B A P B P A B P A P AB P ==) (/)()/()3(A P AB P A B P =) () /()() /()()/()7(1 逆概率公式∑== n i i i i i i A B P A P A B P A P B A P )(/)()(/)()1(S L A L A P n r A P ==
应用举例 1、已知事件,A B 满足)()(B A P AB P =,且6.0)(=A P ,则=)(B P ( )。 2、已知事件,A B 相互独立,,)(k A P =6.0)(,2.0)(==B A P B P ,则=k ( )。 3、已知事件,A B 互不相容,,3.0)(=A P ==)(,5.0)(B A P B P 则( )。 4、若,3.0)(=A P ===)(,5.0)(,4.0)(B A B P B A P B P ( )。 5、,,A B C 是三个随机事件,C B ?,事件()A C B - 与A 的关系是( )。 6、5张数字卡片上分别写着1,2,3,4,5,从中任取3张,排成3位数,则排成3位奇数的概率是( )。 某日他抛一枚硬币决定乘地铁还是乘汽车。 (1)试求他在5:40~5:50到家的概率; (2)结果他是5:47到家的。试求他是乘地铁回家的概率。 解(1)设1A ={他是乘地铁回家的},2A ={他是乘汽车回家的}, i B ={第i 段时间到家的},4,3,2,1=i 分别对应时间段5:30~5:40,5:40~5:50,5:50~6:00,6:00以后 则由全概率公式有 )|()()|()()(2221212A B P A P A B P A P B P += 由上表可知4.0)|(12=A B P ,3.0)|(22=A B P ,5.0)()(21==A P A P 35.05.03.04.05.0)(2=?+?=B P (2)由贝叶斯公式 7 4 35.04.05.0)()()|(22121=?== B P B A P B A P 8、盒中12个新乒乓球,每次比赛从中任取3个来用,比赛 后仍放回盒中,求:第三次比赛时取到3个新球的概率。 看作业习题1: 4, 9, 11, 15, 16
卡方分布概念及表和查表方法
若n个相互独立的随机变量ξ?,ξ?,...,ξn,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成一新的随机变量,其分布规律称为卡方分布(chi-square distribution)。 目录 1简介 2定义 3性质 4概率表 简介 分布在数理统计中具有重要意义。分布是由阿贝(Abbe)于1863年首先提出的,后来由海尔墨特(Hermert)和现代统计学的奠基人之一的卡·皮尔逊(C K·Pearson)分别于1875年和1900年推导出来,是统计学中的一个非常有用的著名分布。 定义 若n个相互独立的随机变量ξ?、ξ?、……、ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成一新的随机变量,其分布规律称为分布(chi-square distribution), 卡方分布是由正态分布构造而成的一个新的分布,当自由度很大时,分布近似为正态分布。
对于任意正整数x,自由度为的卡方分布是一个随机变量X的机率分布。 性质 1) 分布在第一象限内,卡方值都是正值,呈正偏态(右偏态),随着参数 的增大,分布趋近于正态分布;卡方分布密度曲线下的面积都是1。 2) 分布的均值与方差可以看出,随着自由度的增大,分布向正无穷方向延伸(因为均值越来越大),分布曲线也越来越低阔(因为方差越来越大)。 3)不同的自由度决定不同的卡方分布,自由度越小,分布越偏斜。 4) 若互相独立,则:服从分布,自由度为 。 5) 分布的均数为自由度,记为 E( ) = 。 6) 分布的方差为2倍的自由度( ),记为 D( ) = 。 概率表 分布不象正态分布那样将所有正态分布的查表都转化为标准正态分布去查,在 分布中得对每个分布编制相应的概率值,这通过分布表中列出不同的自由度来表示, 查分布概率表时,按自由度及相应的概率去找到对应的值。如上图所示的单侧概率(7)=的查表方法就是,在第一列找到自由度7这一行,在第一行中找到概率这一列,行列的交叉处即是。 表中所给值直接只能查单侧概率值,可以变化一下来查双侧概率值。例如,要在自由度为7的卡方分布中,得到双侧概率为所对应的上下端点可以这样来考虑:双侧概率指的是在
正态概率图(normal probability plot)
正态概率图(normal probability plot) 方法演变:概率图,分位数-分位数图( Q- Q) 概述 正态概率图用于检查一组数据是否服从正态分布。是实数与正态分布数据之间函数关系的散点图。如果这组实数服从正态分布,正态概率图将是一条直线。通常,概率图也可以用于确定一组数据是否服从任一已知分布,如二项分布或泊松分布。 适用场合 ·当你采用的工具或方法需要使用服从正态分布的数据时; ·当有50个或更多的数据点,为了获得更好的结果时。 例如: ·确定一个样本图是否适用于该数据; ·当选择作X和R图的样本容量,以确定样本容量是否足够大到样本均值服从正态分布时;·在计算过程能力指数Cp或者Cpk之前; ·在选择一种只对正态分布有效的假设检验之前。 实施步骤 通常,我们只需简单地把数据输入绘图的软件,就会产生需要的图。下面将详述计算过程,这样就可以知道计算机程序是怎么来编译的了,并且我们也可以自己画简单的图。 1将数据从小到大排列,并从1~n标号。 2计算每个值的分位数。i是序号: 分位数=(i-0.5)/n 3找与每个分位数匹配的正态分布值。把分位数记到正态分布概率表下面的表A.1里面。然后在表的左边和顶部找到对应的z值。 4根据散点图中的每对数据值作图:每列数据值对应个z值。数据值对应于y轴,正态分位数z值对应于x轴。将在平面图上得到n个点。 5画一条拟合大多数点的直线。如果数据严格意义上服从正态分布,点将形或一条直线。将点形成的图形与画的直线相比较,判断数据拟合正态分布的好坏。请参阅注意事项中的典型图
形。可以计算相关系数来判断这条直线和点拟合的好坏。 示例 为了便于下面的计算,我们仅采用20个数据。表5. 12中有按次序排好的20个 值,列上标明“过程数据”。 下一步将计算分位数。如第一个值9,计算如下: 分位数=(i-0.5)/n=(1-0.5)/20=0.5/20=0.025 同理,第2个值,计算如下: 分位数=(i-0.5)/n=(2-0.5)/20=1.5/20=0.075 可以按下面的模式去计算:第3个分位数=2.5÷20,第4个分位数=3 5÷20 以此类推直到最后1个分位数=19. 5÷20。 现在可以在正态分布概率表中查找z值。z的前两 个阿拉伯数字在表的最左边一列,最后1个阿拉伯数 字在表的最顶端一行。如第1个分位数=0. 025,它位 于-1.9在行与0.06所在列的交叉处,故z=-1.96。 用相同的方式找到每个分位数。 如果分位数在表的两个值之间,将需要用插值法 进行求解。例如:第4个分位数为0. 175,它位于0.1736 与0.1762之间。0.1736对应的z值为-0.94,0.1762 对应的z值为-0.93,故 这两数的中间值为z=-0.935。 现在,可以用过程数据和相应的z值作图。图表5. 127显示了结果和穿过这些点的直线。注意:在图形的两端,点位于直线的上侧。这属于典型的右偏态数据。图表5.128显示了数据的直方图,可进行比较。 概率图( probability plot) 该方法可以用于检验任何数据的已知分布。这时我们不是在正态分布概率表中查找分位数,而是在感兴趣的已知分布表中查找它们。 分位数-分位数图(quantile-quantile plot) 同理,任意两个数据集都可以通过比较来判断是否服从同一分布。计算每个分布的分位数。一个数据集对应于x轴,另一个对应于y轴。作一条45°的参照线。如果这两个数据集来自同一分布,那么这些点就会靠近这条参照线。 注意事项 ·绘制正态概率图有很多方法。除了这里给定的程序以外,正态分布还可以用概率和百分数来表示。实际的数据可以先进行标准化或者直接标在x轴上。 ·如果此时这些数据形成一条直线,那么该正态分布的均值就是直线在y轴截距,标准差就是直线斜率。 ·对于正态概率图,图表5.129显示了一些常见的变形图形。 短尾分布:如果尾部比正常的短,则点所形成的图形左边朝直线上方弯曲,右边朝直线下方弯曲——如果倾斜向右看,图形呈S型。表明数据比标准正态分布时候更加集中靠近均值。 长尾分布:如果尾部比正常的长,则点所形成的图形左边朝直线下方弯曲,右边朝直线上方弯曲——如果倾斜向右看,图形呈倒S型。表明数据比标准正态分布时候有更多偏离的数据。
spss教程常用的数据描述统计:频数分布表等统计学
第二节常用的数据描述统计 本节拟讲述如何通过SPSS菜单或命令获得常用的统计量、频数分布表等。 1.数据 这部分所用数据为第一章例1中学生成绩的数据,这里我们加入描述学生性别的变量“sex”和班级的变量“class”,前几个数据显示如下(图2-2),将数据保存到名为“2-6-1.sav”的文件中。 图2-2:数据输入格式示例 1.Frequencies语句 (1)操作 打开数据文件“2-6-1.sav”,单击主菜单Analyze /Descriptive Statistics / F requencies…,出现频数分布表对话框如图2-3所示。 图2-3:Frequencies定义窗口 把score变量从左边变量表列中选到右边,并请注意选中下方的Display frequency table复选框(要求
显示频数分布表)。如果您只要求得到一个频数分布表,那么就可以点OK按钮了。如果您想同时获得一些统计量,及统计图表,还需要进一步设置。 ①Statistics选项 单击Statistics按钮,打开对话框,请按图2-4自行设置。有关说明如下: (ⅰ)在定义百分位值(percentile value)的矩形框中,选择想要输出的各种分位数,SPSS提供的选项有: ●Quartiles四分位数,即显示25%、50%、75%的百分位数。 ●Cut points equal 把数据平均分为几份。如本例中要求平均分为3份。 Percentile显示用户指定的百分位数,可重复多次操作。本例中要求15%、50%、85%的百分位数。(ⅱ) 在定义输出集中趋势(Central Tendency)的矩形框中,选择想要输出的集中统计量,常用的选项有: ●Mean 算术平均数 ●Median 中数 ●Mode 众数 ●Sum 算术和 (ⅲ)在定义输出离散统计量(Dispersion)的矩形框中,选择想要输出的离散统计量,常用的选项有: ●Std. Deviation 标准差 ●Variance 方差 ●Range 全距 ●Minimum 最小值 ●Maximum 最大值 ●S.E. mean 平均数的标准误 (ⅳ)描述数据分布(Distribution)的统计量 ●Skewness 偏度,非对称分布指数。 ●Kurtosis 峰度,CASE围绕中心点的扩展程度。 另外,频数过程(Frequence)除了能够提供上面常用的统计量外,还可以对分组数据计算百分位数和中数(Values are group midpoints),即对于已经分组的数据,并且数据中的原始数据表示的是组中数的数据计算百分位数的值和中位数。
大学概率论与数理统计必过复习资料试题解析(绝对好用)
《概率论与数理统计》复习提要第一章随机事件与概率1.事件的关系 2.运算规则(1)(2)(3)(4) 3.概率满足的三条公理及性质:(1)(2)(3)对互不相容的事件,有(可以取)(4)(5) (6),若,则,(7)(8) 4.古典概型:基本事件有限且等可能 5.几何概率 6.条件概率(1)定义:若,则(2)乘法公式:若为完备事件组,,则有(3)全概率公式: (4) Bayes公式: 7.事件的独立 性:独立(注意独立性的应用)第二章随机变量与概率分 布 1.离散随机变量:取有限或可列个值,满足(1),(2)(3)对 任意, 2.连续随机变量:具有概率密度函数,满足(1)(2); (3)对任意, 4.分布函数,具有以下性质(1);(2)单调非降;(3)右连续;(4),特别;(5)对离散随机变量,; (6)为连续函数,且在连续点上, 5.正态分布的 概率计算以记标准正态分布的分布函数,则有(1);(2);(3) 若,则;(4)以记标准正态分布的上侧分位 数,则 6.随机变量的函数(1)离散时,求的值,将相同的概率相加;(2)连续,在的取值范围内严格单调,且有一阶连续导 数,,若不单调,先求分布函数,再求导。第三章随机向量 1.二维离散随机向量,联合分布列,边缘分布,有(1);(2 (3), 2.二维连续随机向量,联合密度,边缘密度,有 (1);(2)(4)(3);,3.二维均匀分布,其中为的面积 4.二维正态分布 且; 5.二维随机向量的分布函数有(1)关于单调非降;(2)关 于右连续;(3);(4),,;(5);(6)对 二维连续随机向量, 6.随机变量的独立性独立(1) 离散时独立(2)连续时独立(3)二维正态分布独立,且 7.随机变量的函数分布(1)和的分布的密度(2)最大最小分布第四章随机变量的数字特征 1.期望 (1) 离散时 (2) 连续 时, ;,; (3) 二维时, (4); (5);(6);(7)独立时, 2.方差(1)方差,标准差(2); (3);(4)独立时, 3.协方差 (1);;;(2)(3);(4)时, 称不相关,独立不相关,反之不成立,但正态时等价;(5) 4.相关系数;有, 5.阶原点矩,阶中心矩第五章大数定律与中心极限定理 1.Chebyshev不等式 2.大数定律 3.中心极限定理(1)设随机变量独立同分布, 或,或
正态分布讲解(含标准表)
2.4正态分布 复习引入: 总体密度曲线:样本容量越大,所分组数越多,各组的频率就越接近于总体在相应各组取值的概率.设想样本容量无限增大,分组的组距无限缩小,那么频率分布直方图就会无限接近于一条光滑曲线,这条曲线叫做总体密度曲线. 总体密度曲线 b 单位 O 频率/组距 a 它反映了总体在各个范围内取值的概率.根据这条曲线,可求出总体在区间(a,b)内取值的概率等于总体密度曲线,直线x=a,x=b及x轴所围图形的面积. 观察总体密度曲线的形状,它具有“两头低,中间高,左右对称”的特征,具有这种特征的总体密度曲线一般可用下面函数的图象来表示或近似表示: 2 2 () 2 , 1 (),(,) 2 x x e x μ σ μσ ? πσ - - =∈-∞+∞ 式中的实数μ、)0 (> σ σ是参数,分别表示总体的平均数与标准差,, ()x μσ ? 的图象为正态分布密度曲线,简称正态曲线. 讲解新课:
一般地,如果对于任何实数a b <,随机变量X 满足 ,()()b a P a X B x dx μσ?<≤=?, 则称 X 的分布为正态分布(normal distribution ) .正态分布完全由参数μ和σ确定,因此正态分布常记作),(2 σ μN .如果随机变量 X 服从正态分布,则记为X ~),(2σμN . 经验表明,一个随机变量如果是众多的、互不相干的、不分主次的偶然因素作用结果之和,它就服从或近似服从正态分布.例如,高尔顿板试验中,小球在下落过程中要与众多小木块发生碰撞,每次碰撞的结果使得小球随机地向左或向右下落,因此小球第1次与高尔顿板底部接触时的坐标 X 是众多随机碰撞的结果,所以它近似服从正态分布.在现实生活中,很多随机变量都服从或近似地服从正态分布.例如长度测量误差;某一地区同年龄人群的身高、体重、肺活量等;一定条件下生长的小麦的株高、穗长、单位面积产量等;正常生产条件下各种产品的质量指标(如零件的尺寸、纤维的纤度、电容器的电容量、电子管的使用寿命等);某地每年七月份的平均气温、平均湿度、降雨量等;一般都服从正态分布.因此,正态分布广泛存在于自然现象、生产和生活实际之中.正态分布在概率和统计中占有重要的地位. 说明:1参数μ是反映随机变量取值的平均水平的特征数,可以用样本均值去佑计;σ是衡量随机变量总体波动大小的特征数,可以用样本标准差去估计. 2.早在 1733 年,法国数学家棣莫弗就用n !的近似公式得到了正态分布.之后,德国数学家高斯在研究测量误差时从另一个角度导出了它,并研究了它的性质,因此,人们也称正态分布为高斯分布. 2.正态分布),(2 σ μN )是由均值μ和标准差σ唯一决定的分布 通过固定其中一个值,讨论均值与标准差对于正态曲线的影响
正态分布概率表
参考医学 正态分布概率表 1 — f? 0( u )= t P⑴t F(t)t F(0t卩⑴0.00 0.000 00.230. 181 9 0.46 0.354 5 W9 0. 50 9 8 0.01 0.008 00.24 0. 1H9 70.47 0.361 6 0.70 0,516 1 0+02 0,0160 0. 25 0,197 4 0,48 0.368 80+71 0.522 3 0.03 0*023 9(1. 26 0.205 1 0.49 0.375 9 0.72 0. 52 8 5 044 0.031 9(1.27 0,212 8 0.50O.3R2 9 0.73 "4 6 0R5 0039 90.28 0.220 5 0,51 0.389 9 0.74 0.540 7 0.06 0.047 80.29 0.228 20.52 036 9 0.75 0*546 7 0+07 0 €55 g0,30 0,235 8 0,53 0.403 9 276 0.552 7 0+08 0.063 80 31 0.243 4 0.54 0.410 8 0+77 0.558 7 0+09 (1.(171 7(J. 32 0.251 00.55 0.417 70.78 0.564 6 0. 10 0.0797 fl. 33 0.258 6 0.56 0,424 50.79 0.570 5 0.110,(J87 60.34 0.266 1 0.57 0.431 3 0.B0 0.576 3 0.12 0.09$ 50. 35 0.273 7 0.5S 0.43S 10.S1 O.5S2 1 0+13 OJ03 40. 36 0.281 20.59 0.444 8 0+82 0.587 8 0+14 (1.111 3 0. 37 0.288 6 0.60 0.451 5 M3 0.593 5 0.15 0J19 2 0. 38 0.296 1 0.61 0.458 10.84 0.599 1 0+160.127 10.39 0. 303 50.62 0.464 7 0.85 0.604 7 0.17 0.135 0 040 0330 8 0.63 0.471 3 0.S6 0.610 2 0+18 0.142 S0.41 0.318 20,64 0.477 8 0.87 0.6157 0+19 0.150 7 0 42 0, 325 50.650.484 3 0.88 0.621 1 0,20 0J58 5(J. 43 0. 332 8 0.66 0.490 10.89 0 . 62 6 5 0,21 0J66 3(J.44 0,340 1 0.67 0.497 10.90 0.631 9 0 + 220.174 10.45 0347 3 0.68 0.503 50.91 0.637 2
概率论与数理统计中的三种重要分布
概率论与数理统计中的三种重要分布 摘要:在概率论与数理统计课程中,我们研究了随机变量的分布,具体地研究了离散型随机变量的分布和连续型随机变量的分布,并简单的介绍了常见的离散型分布和连续型分布,其中二项分布、Poisson 分布、正态分布是概率论中三大重要的分布。因此,在这篇文章中重点介绍二项分布、Poisson 分布和正态分布以及它们的性质、数学期望与方差,以此来进行一次比较完整的概率论分布的学习。 关键词:二项分布;Poisson 分布;正态分布;定义;性质 一、二项分布 二项分布是重要的离散型分布之一,它在理论上和应用上都占有很重要的地位,产生 这种分布的重要现实源泉是所谓的伯努利试验。 (一)泊努利分布[Bernoulli distribution ] (两点分布、0-1分布) 1.泊努利试验 在许多实际问题中,我们感兴趣的是某事件A 是否发生。例如在产品抽样检验中,关心的是抽到正品还是废品;掷硬币时,关心的是出现正面还是反面,等。在这一类随机试验中,只有两个基本事件A 与A ,这种只有两种可能结果的随机试验称为伯努利试验。 为方便起见,在一次试验中,把出现A 称为“成功”,出现A 称为“失败” 通常记(),p A P = () q p A P =-=1。 2.泊努利分布 定义:在一次试验中,设p A P =)(,p q A P -==1)(,若以ξ记事件A 发生的次数, 则??? ? ??ξp q 10 ~,称ξ服从参数为)10(<
概率论与数理统计期末复习重要知识点
概率论与数理统计期末复习重要知识点 第二章知识点: 1.离散型随机变量:设X 是一个随机变量,如果它全部可能的取值只有有限个或可数无穷个,则称X 为一个离散随机变量。 2.常用离散型分布: (1)两点分布(0-1分布): 若一个随机变量X 只有两个可能取值,且其分布为 12{},{}1(01) P X x p P X x p p ====-<<, 则称X 服从 12 ,x x 处参数为p 的两点分布。 两点分布的概率分布:12{},{}1(01) P X x p P X x p p ====-<< 两点分布的期望:()E X p =;两点分布的方差:()(1)D X p p =- (2)二项分布: 若一个随机变量X 的概率分布由式 {}(1),0,1,...,. k k n k n P x k C p p k n -==-= 给出,则称X 服从参数为n,p 的二项分布。记为X~b(n,p)(或B(n,p)). 两点分布的概率分布:{}(1),0,1,...,. k k n k n P x k C p p k n -==-= 二项分布的期望:()E X np =;二项分布的方差:()(1)D X np p =- (3)泊松分布: 若一个随机变量X 的概率分布为{},0,0,1,2,... ! k P X k e k k λ λλ-==>=,则称X 服从参 数为λ的泊松分布,记为X~P (λ) 泊松分布的概率分布:{},0,0,1,2,... ! k P X k e k k λ λλ-==>= 泊松分布的期望: ()E X λ=;泊松分布的方差:()D X λ= 4.连续型随机变量: 如果对随机变量X 的分布函数F(x),存在非负可积函数 ()f x ,使得对于任意实数x ,有 (){}()x F x P X x f t dt -∞ =≤=? ,则称X 为连续型随机变量,称 ()f x 为X 的概率密度函数, 简称为概率密度函数。 5.常用的连续型分布:
常见统计量
?一、T检验 ?用途:?比较两组数据之间的差异 前提:正态性,?方差?齐次性,独?立性 假设:H0: μ0=μ1 H1: μ0≠μ1 SPSS中对应?方法: 1、单样本T检验(One-sample Test) (1)??目的:检验单个变量的均值与给定的某个常数是否?一致。 (2)判断标准:p<0.05;t>1.98即认为是有显著差异的。 2、独?立样本T检验(Independent-Samples T Test) (1)??目的:检验两个独?立样本均值是否相等。 (2)判断标准:p<0.05;t>1.98即认为是有显著差异的。 3、配对样本T检验(Paired-Samples T Test) (1)??目的:检验两个配对样本均值是否相等。 (2)判断标准:p<0.05;t>1.98即认为是有显著差异的。 ! ?二、?方差分析 ?用途:?比较多组数据之间的差异 前提:正态性,?方差?齐次性,独?立性 假设:H0: μ0=μ1=…… H1: μ0,μ1,……不全相等 SPSS中对应?方法: 1、单因素?方差分析(One-way ANOVA) (1)??目的:检验由单?一因素影响的多组样本均值差异。 (2)判断标准:p>0.05;t<1.98即认为是有显著差异的。 (3)特别说明:可以进?一步使?用LSD,Tukey?方法检验两两之间的差异。 2、多因素?方差分析(Univariate) (1)??目的:检验由多个因素影响的多组样本均值差异。 (2)判断标准:p>0.05;t<1.98即认为是有显著差异的。 (3)特别说明:可以进?一步使?用LSD,Tukey?方法检验两两之间的差异。! 三、?非参数检验 ?用途:?比较多组数据之间的差异,独?立性等
常用统计量及其应用
第四章 常用统计量及其应用 第一节 平均数与标准差的概念 一、平均数 反映一组性质相同的观测值的平均水平或集中趋势的统计量,其数学定义为 n x 1= ∑=n i i x 1 平均数在一定程度上代表一组数据的整体水平,体育工作中,常用这一概念来反映事物的某些特征。 例如,某中学的体育平均达标率,学生的平均身高,年龄某地区高考体育加试平均分数等等。 二、标准差 样本平均数描述数据的集中趋势,反映样本数据的平均水平。但是,平均数对整体的代表性是有条件的。 例如,吉斯莫先生经营一家工厂,规模不大,现欲招聘一名工人,汤姆先生参加面试,老板告诉他,本厂全体人员的工资入平均每人每周300元,汤姆一听,欣然接受,上班一天后,来找老板,声称受骗,老板算了一笔帐,汤姆听了无话可说。 平均工资 300元/周 说明:该厂平均工资尽管较高,但由于各个工资相差太大,平均数对整体的代表性较差。这就说明在实际应用中,仅有平均数是不够的,还要考虑到数据的离散程度。在数据相对比较集中时,平均数才具有代表性。 反映样本离散程度的统计量,称之为标准差 设样本观测值为21,x x …,n x 平均数为x ,看看如何来定量计算标准差? 样本的离散程度自然是相对平均数x 而言的为此构造出 )(1 x x i n i -∑ =
但上式各项有正有负,正负抵消 )(1 x x i n i -∑ ==0 所以要反映离散程度的大小可以让上式各项加以绝对值或求平方,但带绝对值后不便于处理,所以,选择后者从而有 21 )(x x i n i -∑ = 上式与样本含量的大小有关,所以,求平均的 n 121 )(x x i n i -∑ = 在实际应用中,上式对总体离散程度的估计往往偏小若以自由度(1-n )代替n ,则是无偏的因此,构造 221 ?)(11s x x n i n i =--∑= 上式中2 s 称为样本方差,还原成原来的量纲 则有 21 )(11x x n S i n i --= ∑= S 称为标准差,反映样本的离散程度。 结束语: 样本平均数反映样本数据的整体水平,但是要结合标准差,标准差反映样本数据的离散程度对于运动成绩,表现为成绩的稳定性。 第6次课(3学时) 教学目的:通过本次课的教学,使学生了解平均数和标准差在体育中的具体应用,掌握利用 平均数和标准差制定评分评价标准的方法。 教学内容:平均数和标准差在体育中的应用 1.标准百分 2.累进计分 3.离差法制定评价标准 4.在制定离差评价表中的应用 教学重点:1.标准百分和累进计分的计分思想 2.离差评价表的制定过程
正态分布概率公式(部分)
Generated by Foxit PDF Creator ? Foxit Software https://www.wendangku.net/doc/8019019912.html, For evaluation only.
图 62正态分布概率密度函数的曲线 正态曲线可用方程式表示。 n 当 →∞时,可由二项分布概率函数方程推导出正态 分布曲线的方程:
fx= (61 ) () .6
式中: x—所研究的变数; fx —某一定值 x出现的函数值,一般称为概率 () 密度函数 (由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某 一区间的概率, 不能计算变量取某一值, 即某一点时的概率, 所以用 “概率密度” 一词以与概率相区分),相当于曲线 x值的纵轴高度; p—常数,等于 31 .4 19……; e— 常数,等于 2788……; μ 为总体参数,是所研究总体 5 .12 的平均数, 不同的正态总体具有不同的 μ , 但对某一定总体的 μ 是一个常数; δ 也为总体参数, 表示所研究总体的标准差, 不同的正态总体具有不同的 δ , 但对某一定总体的 δ 是一个常数。 上述公式表示随机变数 x的分布叫作正态分布, 记作 N μ ,δ2 ), “具 ( 读作 2 平均数为 μ,方差为 δ 的正态分布”。正态分布概率密度函数的曲线叫正态 曲线,形状见图 62。 (二)正态分布的特性
1、正态分布曲线是以 x μ 为对称轴,向左右两侧作对称分布。因 =
的
数值无论正负, 只要其绝对值相等, 代入公式 61 ) ( .6 所得的 fx 是相等的, () 即在平均数 μ 的左方或右方,只要距离相等,其 fx 就相等,因此其分布是 () 对称的。在正态分布下,算术平均数、中位数、众数三者合一位于 μ 点上。
概率分布查表联系
1. 若某班学生统计学成绩服从正态分布) ,(25 80~N X ,任从中抽取一个同学,试问该同学的成绩在以下范围内的概率: (1)85)P(X ≤=()8413.0)1(1 58085580= Φ=≤=?? ? ??-≤-Z P X P (2)75)P(X ≤ =()1587.08413.01)1(1)1(1580755 80=-=Φ-=-Φ=-≤=??? ??-≤-Z P X P (3)85)X P(75≤≤ =()[]6827 .018413.0*21)1(2)1(1)1()1()1(11580855805 8075=-=-Φ=Φ--Φ=-Φ-Φ=≤-=??? ??-≤-≤-=Z P X P π
(4)85) X P(70≤≤19772.08413.01)2()1()]2(1[)1()2()1(-+=-Φ+Φ=Φ--Φ=-Φ-Φ= (5)90)P(X ≥ 9772.01)2(1)2(1)2(-=Φ-=≤-=≥=Z P Z P 2. 查表计算有关t 分布 (1)132.2)4(t 0.05= (2)169.3)10(t -2 0.01-= (3)10.01.476)5(t ==αα, (4)05.0-2.447)6(t -2 ==αα, (5)103.169)n (t 0.005==n ,
(6)112.718)n (t 2 0.02==n , 3. 查表计算有关2 χ分布 (1)307.18102 0.05 =)(χ (2)975.04.404122==αχα,) ( (3)511.072n 20.05==n ,)(χ (4)看下图查表,在( )处写出正式表达方式和具体数值。
正态分布概率公式(部分)
图 6-2 正态分布概率密度函数的曲线 正态曲线可用方程式表示。当n→∞时,可由二项分布概率函数方程推导出正态分布曲线的方程: f(x)= (6.16 ) 式中: x —所研究的变数; f(x) —某一定值 x 出现的函数值,一般称为概率密度函数(由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某一区间的概率,不能计算变量取某一值,即某一点时的概率,所以用“概率密度”一词以与概率相区分),相当于曲线 x 值的纵轴高度; p —常数,等于 3.14 159 ……; e —常数,等于 2.71828 ……;μ为总体参数,是所研究总体的平均数,不同的正态总体具有不同的μ,但对某一定总体的μ是一个常数;δ也为总体参数,表示所研究总体的标准差,不同的正态总体具有不同的δ,但对某一定总体的δ是一个常数。 上述公式表示随机变数 x 的分布叫作正态分布,记作 N( μ , δ2 ) ,读作“具平均数为μ,方差为δ 2 的正态分布”。正态分布概率密度函数的曲线叫正态曲线,形状见图 6-2 。 (二)正态分布的特性 1 、正态分布曲线是以 x= μ为对称轴,向左右两侧作对称分布。因的数值无论正负,只要其绝对值相等,代入公式( 6.16 )所得的 f(x) 是相等的,即在平均数μ的左方或右方,只要距离相等,其 f(x) 就相等,因此其分布是对称的。在正态分布下,算术平均数、中位数、众数三者合一位于μ点上。
2 、正态分布曲线有一个高峰。随机变数 x 的取值范围为( - ∞,+ ∞ ),在( - ∞ ,μ)正态曲线随 x 的增大而上升,;当 x= μ时, f(x) 最大;在(μ,+ ∞ )曲线随 x 的增大而下降。 3 、正态曲线在︱x-μ︱=1 δ处有拐点。曲线向左右两侧伸展,当x →± ∞ 时,f(x) →0 ,但 f(x) 值恒不等于零,曲线是以 x 轴为渐进线,所以曲线全距从 -∞到+ ∞。 4 、正态曲线是由μ和δ两个参数来确定的,其中μ确定曲线在 x 轴上的位置 [ 图 6-3] ,δ确定它的变异程度 [ 图 6-4] 。μ和δ不同时,就会有不同的曲线位置和变异程度。所以,正态分布曲线不只是一条曲线,而是一系列曲线。任何一条特定的正态曲线只有在其μ和δ确定以后才能确定。 5 、正态分布曲线是二项分布的极限曲线,二项分布的总概率等于 1 ,正态分布与 x 轴之间的总概率(所研究总体的全部变量出现的概率总和)或总面积也应该是等于 1 。而变量 x 出现在任两个定值 x1到x2(x1≠x2)之间的概率,等于这两个定值之间的面积占总面积的成数或百分比。正态曲线的任何两个定值间的概率或面积,完全由曲线的μ和δ确定。常用的理论面积或概率如下: 区间μ ± 1 δ面积或概率 =0.6826 μ ± 2 δ =0.9545 μ ± 3 δ=0.9973 μ± 1.960δ=0.9500 μ ±2.576 δ =0.9900
概率统计分布表(常用)
标准正态表 x 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.5000 0.5040 0.5080 0.5120 0.5160 0.5199 0.5239 0.5279 0.5319 0.5359 0.1 0.5398 0.5438 0.5478 0.5517 0.5557 0.5596 0.5636 0.5675 0.5714 0.5753 0.2 0.5793 0.5832 0.5871 0.5910 0.5948 0.5987 0.6026 0.6064 0.6103 0.6141 0.3 0.6179 0.6217 0.6255 0.6293 0.6331 0.6368 0.6406 0.6443 0.6480 0.6517 0.4 0.6554 0.6591 0.6628 0.6664 0.6700 0.6736 0.6772 0.6808 0.6844 0.6879 0.5 0.6915 0.6950 0.6985 0.7019 0.7054 0.7088 0.7123 0.7157 0.7190 0.7224 0.6 0.7257 0.7291 0.7324 0.7357 0.7389 0.7422 0.7454 0.7486 0.7517 0.7549 0.7 0.7580 0.7611 0.7642 0.7673 0.7704 0.7734 0.7764 0.7794 0.7823 0.7852 0.8 0.7881 0.7910 0.7939 0.7967 0.7995 0.8023 0.8051 0.8078 0.8106 0.8133 0.9 0.8159 0.8186 0.8212 0.8238 0.8264 0.8289 0.8315 0.8340 0.8365 0.8389
统计学第5-6章 正态分布 统计量其抽样分布
第5-6章 统计量及其抽样分布 5.1正态分布 5.1.1定义:当一个变量受到大量微小的、独立的随机因素影响时,这个变量一般服从正态分布或近似服从正态分布。 概率密度曲线图 例如:某个地区同年龄组儿童的发育特征:身高、体重、肺活量等 某一条件下产品的质量 如果随机变量X 的概率密度为 22 ()21 (),2x f x e x μσπσ --=-∞<<∞ 则称X 服从正态分布。 记做 2 (,)X N μσ:,读作:随机变量X 服从均值为μ,方差为2 σ的正态分布 其中, μ-∞<<∞,是随机变量X 的均值,0σ>是是随机变量X 的标准差 5.1.2正态密度函数f(x)的一些特点: ()0f x ≥,即整个概率密度曲线都在x 轴的上方。 曲线 ()f x 相对于x μ=对称,并在 x μ=处达到最大值,
1 () 2 fμ πσ = 。 1 μ< 2 μ< 3 μ 曲线的陡缓程度由 σ 决定:σ越大,曲线越平缓;σ越小,曲线越陡峭当 x 趋于无穷时,曲线以x轴为其渐近线。 标准正态分布 当 0,1 μσ == 时, 2 2 1 () 2 x f x e π - = , x -∞<<∞ 称 (0,1) N 为标准正态分布。
标准正态分布的概率密度函数: ()x ? 标准正态分布的分布函数: ()x Φ 任何一个正态分布都可以通过线性变换转化为标准正态分布 设 2 (,) X Nμσ : ,则 (0,1) X Z N μ σ - =: 变量 2 11 (,) X Nμσ :与变量2 22 (,) Y Nμσ :相互独立,则有 22 1212 +(+,+) X Y Nμμσσ : 5.1.3 正态分布表:可以查的正态分布的概率值()1() x x Φ-=-Φ 例:设 (0,1) X N :,求以下概率 (1) ( 1.5) P X< (2) (2) P X> (3) (13) P X -<≤
概率统计复习提纲(百度文库)讲解
《概率论与数理统计》总复习提纲 第一块随机事件及其概率 内容提要 基本内容:随机事件与样本空间,事件的关系与运算,概率的概念和基本性质,古典概率,几何概率,条件概率,与条件概率有关的三个公式,事件的独立性,贝努里试验. 1、随机试验、样本空间与随机事件 (1)随机试验:具有以下三个特点的试验称为随机试验,记为. 1)试验可在相同的条件下重复进行; 2)每次试验的结果具有多种可能性,但试验之前可确知试验的所有可能结果; 3)每次试验前不能确定哪一个结果会出现. (2)样本空间:随机试验的所有可能结果组成的集合称为的样本空间记为Ω;试验的每一个可能结果,即Ω中的元素,称为样本点,记为. (3)随机事件:在一定条件下,可能出现也可能不出现的事件称为随机事件,简称事件;也可表述为事件就是样本空间的子集,必然事件(记为)和不可能事件(记为). 2、事件的关系与运算 (1)包含关系与相等:“事件发生必导致发生”,记为或;且. (2)互不相容性:;互为对立事件且. (3)独立性: (1)设为事件,若有,则称事件与相互独立. 等价于:若 (). (2)多个事件的独立:设是n个事件,如果对任意的,任意的 ,具有等式,称个事件相互独立. 3、事件的运算 (1)和事件(并):“事件与至少有一个发生”,记为. (2)积事件(交):“事件与同时发生”,记为或.
(3)差事件、对立事件(余事件):“事件发生而不发生”,记为称为与的差事件; 称为的对立事件;易知:. 4、事件的运算法则 1) 交换律:,; 2) 结合律:,; 3) 分配律:,; 4) 对偶(De Morgan)律:,, 可推广 5、概率的概念 (1)概率的公理化定义: (2)频率的定义:事件在次重复试验中出现次,则比值称为事件在次重复试验中出现的频率,记为,即. (3)统计概率:称为事件的(统计)概率. 在实际问题中,当很大时,取 (4)古典概率:若试验的基本结果数为有限个,且每个事件发生的可能性相等,
正态分布的概念及表和查表方法
正态分布概念及图表 正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),最早由A·棣莫弗在求二项分布的渐近公式中得到。.高斯在研究测量误差时从另一个角度导出了它。P·S·拉普拉斯和高斯研究了它的性质。是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。 正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。 若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。 目录 1历史发展 2定理 3定义 ?一维正态分布 ?标准正态分布 4性质 5分布曲线
?图形特征 ?参数含义 6研究过程 7曲线应用 ?综述 ?频数分布 ?综合素质研究 ?医学参考值 历史发展 正态分布概念是由德国的数学家和天文学家Moivre于1733年首次提出的,但由于德国数学家Gauss率先将其应用于天文学家研究,故正态分布又叫高斯分布,高斯这项工作对后世的影响极大,他使正态分布同时有了“高斯分布”的名称,后世之所以多将最小二乘法的发明权归之于他,也是出于这一工作。但现今德国10马克的印有高斯头像的钞票,其上还印有正态分布的密度曲线。这传达了一种想法:在高斯的一切科学贡献中,其对人类文明影响最大者,就是这一项。在高斯刚作出这个发现之初,也许人们还只能从其理论的简化上来评价其优越性,其全部影响还不能充分看出来。这要到20世纪正态小样本理论充分发展起来以后。拉普拉斯很快得知高斯的工作,并马上将其与他发现的中心极限定理联系起来,为此,他在即将发表的一篇文章(发表于1810年)上加上了一点补充,指出如若误差可看成许多量的叠加,根据他的中心极限定理,误差理应有高斯分布。这是历史上第一次提到所谓“元误差学说”——误差是由大量的、由种种原因产生的元误差叠加而成。后来到1837年,海根()在一篇论文中正式提出了这个学说。